Effective_Python mapreduce
<1>完全吊炸天构造器的写法。。。
import os
import threading,time
class GenericInputData(object):
def read(self):
raise NotImplementedError
@classmethod
def generate_inputs(cls,config):
raise NotImplementedError class PathInputData(GenericInputData):
def __init__(self,path):
super(PathInputData, self).__init__()
self.path=path
def read(self):
return open(self.path).read()
def get_path_name(self):
return self.path """this class method init the Constructor function->__init__() ... """
@classmethod
def generate_inputs(cls,config):
data_dir = config['data_dir'] #dict elements
for name in os.listdir(data_dir):
yield cls(os.path.join(data_dir,name)) class GenerateWorker(object):
def __init__(self,input_data):
self.input_data = input_data
self.result = None
def map(self):
raise NotImplementedError
def reduce(self, other):
raise NotImplementedError
@classmethod
def create_workers(cls,input_class,config):
workers = []
for input_path_data in input_class.generate_inputs(config):
workers.append(cls(input_path_data)) # direct __init__ Constructor function
return workers class LineCountWorker(GenerateWorker):
"""default no __init__ function, then will use the default parent class __init__"""
def __init__(self,input_data):
super(LineCountWorker, self).__init__(input_data)
def map(self):
data = self.input_data.read()
self.result = data.count("\n")
def reduce(self, other):
self.result+= other.result
def get_worker_name(self):
return self.input_data.get_path_name() class Thread_Excute_workers(threading.Thread):
def __init__(self,threadId,worker):
super(Thread_Excute_workers, self).__init__()
self.worker = worker
self.th_id = threadId
def run(self):
self.worker.map()
print "Thread ID " + str(self.th_id) + " run " + self.worker.get_worker_name() + '\n' def excute(workers):
threads = [] # create thread elements
thread_id = 0
for w in workers:
th = Thread_Excute_workers(thread_id,w)
th.start()
threads.append(th)
thread_id = thread_id + 1
for rh_thread in threads:
rh_thread.join() # caculate worker of reduce
first,rest = workers[0],workers[1:]
for rh_work in rest:
first.reduce(rh_work)
return first.result def mapreduce(worker_class,input_class,config):
workers = worker_class.create_workers(input_class,config)
return excute(workers) config = {'data_dir': "C:\\data_dir"}
result = mapreduce(LineCountWorker,PathInputData,config)
print result
<2> Create md5
import hashlib def getMd5(data):
md5_obj = hashlib.md5()
md5_obj.update(str(data))
md5_var = md5_obj.hexdigest()
return md5_var
if __name__ == "__main__":
a = getMd5(1)
b = getMd5(1)
print a==b
print a
<3> 单元测试
def just_do_it(text):
return text.capitalize()
cap.py
import cap
import unittest
class TestCap(unittest.TestCase):
def test_one_word(self):
text = 'duck'
result = cap.just_do_it(text)
self.assertEqual(result,'Duck') def test_length(self):
test = 'duck'
result = len(cap.just_do_it(test))
self.assertEqual(result,4)
if __name__ == '__main__':
log_file = "log_file.txt"
f = open(log_file, "w")
runner = unittest.TextTestRunner(stream=f,verbosity=2)
unittest.main(exit = False,testRunner=runner)
f.close()
unittest_cap
如果不想放在文件里,直接unittest.main()
<4>Bytes 子节
(1)转换字节:

(2) 读取png 文件的width ,height
import struct
import pprint
import binascii
pngHeader = b'\x89PNG\r\n\x1a\n'
f = file('test.png',mode='r')
pngByte = f.read(30) if pngByte[:8] == pngHeader:
print 'this is a png file'
# '> big-endian'
# 'L is 4 bytes unsigned long int'
# 'width is at 16-20 stream pos, height is 21-24 stream pos'
# 'L L is 8 bytes'
width,height = struct.unpack('>LL',pngByte[16:24])
print 'width height:',width,height print 'width bytes is ' , struct.unpack('>L',pngByte[16:20])
print 'height bytes is ' , pngByte[20:24]
(3)一些类的概念:
"""
# <1>PROPERTY do not hidden_name member , but can use name=PROPERTY(get,set)
class duck():
def __init__(self,input_name):
self.hidden_name = input_name
def get_name(self):
print 'inside getter'
return self.hidden_name
def set_name(self,input_name):
self.hidden_name = input_name
name = property(get_name,set_name) if __name__ == "__main__":
d = duck('tttttt')
d.hidden_name = 'ttt' # Very stupid , not hidden
#d.set_name() # this can be called ok
print d.name
""" """
# <2>use @property and setter method
class duck():
def __init__(self,input_name):
self.hidden_name = input_name #GETTER METHOD
@property
def name(self):
print 'inside the getter'
return self.hidden_name #SETTER METHOD
@name.setter
def name(self,input_name):
print 'inside the getter'
self.hidden_name = input_name d = duck('houdini')
d.name = "test"
print d.name
""" """
#<3> @property connect the self.member
class Circle():
def __init__(self,radius):
self.radius = radius @property
def diameter(self):
return self.radius*2 c = Circle(2)
print c.radius # 2
print c.diameter # 4
c.radius = 7
print c.diameter # 14 c.diameter = 1000 # It's can not set value,because it have not diameter.setter(),but in py2.7 ,it set ok......
print c.diameter # 1000
""" """
#<4> hidden ?
class Duck():
def __init__(self,input_name):
self.__name = input_name @property
def name(self):
print 'getter method'
return self.__name
@name.setter
def name(self,input_name):
print 'setter method'
self.__name = input_name d = Duck('Maya')
print d.name
d.name = 'Houdini'
print d.name
#print d.__name #ERROR
#print d._Duck__name #Get hidden member,But Result is Maya....
""" """
#<5> @classmethod,class member
class A():
count = 0 #Same as C++ static member
def __init__(self):
A.count += 1 #Same as C++ static member @classmethod
def kids(cls):
print " A has childs num is " ,cls.count
a1=A()
a2=A()
a3=A()
A.kids()
""" #<6> Magic method
class Word():
def __init__(self,text):
self.text = text def __eq__(self, other):
return self.text == other.text def __add__(self, other):
return Word(self.text+other.text) def __sub__(self, other):
return Word(self.text-other.text)
a = Word(1)
b = Word(2)
print a==b # False
c = a+b
print c.text #
print isinstance(c,int) # False
print isinstance(c,float) # False
print isinstance(c,Word) # True
(4) 深入函数参数:*arg,**kwargs,指向函数的参数
# coding=utf-8
'''
Created by yangping liu on 2017-05-19.
Copyright (c) 2018 YiAnimation.All rights reserved.
''' #<1>
#参数*arg,其实进去就作为元组
def test_turple(*arg): #arg as tuple
print arg
for x in arg:
print '*arg index value is ' ,x
#参数**kwargs,进去就作为字典
def test_dictArguments(farg, **kwargs): #kwargs as dict
print "farg:", farg
for key in kwargs:
print "another keyword arg: %s: %s" % (key, kwargs[key]) test_turple(1,2,3,4,5)
test_dictArguments(farg=1, myarg2="two", myarg3=3) #<2>
#定义一个add函数,接受*args,其实*args是有顺序的元组
def add(*args):
return sum(args) #定义一个callback,用来指向函数,而args是callback函数的参数
def testAddpointer(callback,*args):
if(len(args)) == 0 : #non arg function
return callback()
return callback(*args) print testAddpointer(add)
print testAddpointer(add,1,2,3)
print testAddpointer(add,1,2,4,5,6,7,8,9) #定义一个只有2个参数,其实对于+法功能其实很垃圾,毕竟不能1+2+3+4...
def addBad(x=0,y=1):
return x+y
print testAddpointer(addBad) # 1 我们的函数参数 函数指针依然适合
print testAddpointer(addBad,1,2) # 3 函数参数 函数指针依然适合 #<3>
print "\ndict to function arguments samples"
#定义一个加法,不过这次有3个参数
def add2(arg1,arg2,arg3):
return arg1 + arg2 + arg3
kwargs = {"arg2" :2,"arg3" :3}
#把1可以传入arg1,**kwargs就会会作为arg2 = 2 ,arg3=3
print add2(1,**kwargs) #结果6 #<4>
print '\nfunction pointer to a function,args is **kwargs'
def add3(master,senior):
return master+senior
#我们函数参数这次带的是**kwargs
def testAddPointerDict(callback,**kwargs):
return add3(**kwargs) #注意传入方法
dictFunctionArg = {'master':1,'senior':2}
print testAddPointerDict(add3,**dictFunctionArg) # ok
print testAddPointerDict(add3,master=1,senior=2) # ok
print testAddPointerDict(add3,senior=2,master=1) # ok
(5)修饰器:
def document_it(func):
def new_function(*args,**kwargs):
print "running function : " ,func.__name__
print 'position arguments : ',args
print 'keyword arguments : ' ,kwargs
result = func(*args,**kwargs)
print('Result :',result)
return result
return new_function def add_ints(a,b):
return a+b cooler_add_ints = document_it(add_ints) #implicat the de
print cooler_add_ints(a=1,b=2)
print cooler_add_ints(b=3,a=2)
print cooler_add_ints(1,2) # direct document this function
@document_it
def add_ints2(a,b):
return a+b
(6)如何制作更加成熟的callBack
class callback(object):
def __init__(self, func, *args, **kwargs):
self.func = func
self.args = args
self.kwargs = kwargs def __call__(self, *args):
try:
return self.func(*self.args, **self.kwargs)
except:
return None #define add_simple
def add_simple(x,y):
return x+y
add_simpleCallBack = callback(add_simple,10,15) #define print simple
def print_simple(var= 'Error Code'):
print var
print_simpleCallBack = callback(print_simple) if add_simpleCallBack:
print 'callback add object object:' ,add_simpleCallBack()
if print_simpleCallBack:
print 'callback print simple:',print_simpleCallBack()
(7)一些特殊方法测试:
class Description:
def __init__(self):
self.data = []
def __add__(self, other):
self.data.append(other)
return self
def __str__(self):
return str(self.data)
def __sub__(self, other):
self.data.remove(other)
return self
def __len__(self):
return len(self.data)
def __getitem__(self, item):
return self.data[item] if __name__ == "__main__":
e = Description()
e+=1
e+=2
e+=3
e-=3
e+='houdini'
e+='maya'
print 'length is ',len(e), ' Data is :',e
print e[0]
(8)打包
C:\Python27\Scripts\pyinstaller.exe -F -w --name MusterRendering --icon=icon.ico sqlite_muster.py

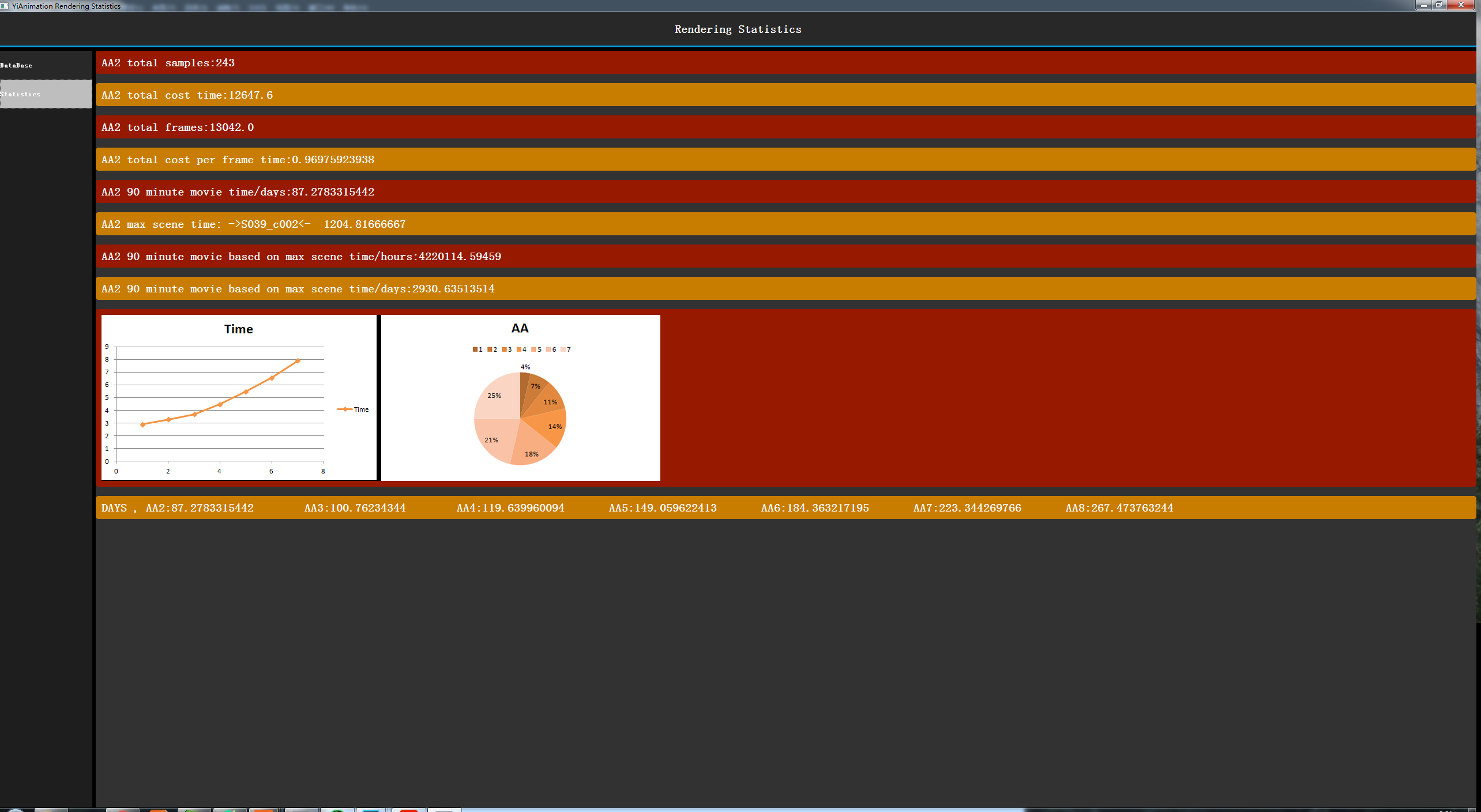
<>元类:
"Type" create a class:
class ObjectCreator(object):
pass def echo(cls):
print cls def unit_test_part1():
my_object = ObjectCreator()
echo(my_object)
echo(ObjectCreator)
echo(hasattr(ObjectCreator, "new_attribute")) # add new_attribute='foo' for class
ObjectCreator.new_attribute = 'foo' #attribute for class
echo(hasattr(ObjectCreator, "new_attribute")) #true
echo(ObjectCreator.new_attribute) #foo #Class to a variable
nclass = ObjectCreator
echo(hasattr(nclass,"new_attribute")) #true
echo(nclass.new_attribute) #foo # type create class
foo = type('foo',(),{'bar':True}) #create a class 'foo'
echo(foo.__class__) #type 'type'
echo(type(foo)) #type 'type'
echo(foo) #<class '__main__.foo'>
echo(foo.bar) #true
fooChild = type('fooChild',(foo,),{'ok':False})
echo(fooChild)
echo(fooChild.bar) #true
echo(fooChild.ok)
type.__class__ ,type.__class__.__class__
# unit_test part2
def unit_test_part2():
def foo():
pass
echo(foo.__class__) #type 'function'
echo('houdini'.__class__) #type 'str'
echo((2).__class__) #type 'int'
echo((2).__class__.__class__) #type 'type'
Change class member name to a Upper.
def upper_attr(future_class_name, future_class_parents, future_class_attr):
print future_class_name,"|",future_class_parents,"|",future_class_attr
att = {}
for name,value in future_class_attr.items():
if name.startswith('__'):
continue
att[name.upper()] = value
att['json'] = "json" # add a lower attribute for class return type(future_class_name, future_class_parents, att) #__metaclass__ = upper_attr class Foo(object):
bar = 'pip'
hou = 'houdini'
__metaclass__ = upper_attr if __name__ == "__main__":
print Foo.BAR
print Foo.HOU
print Foo.json
OOP metaClass
generate some attribute for class
class MetaClass(type):
def __new__(cls,name,baseClass,dict):
print '==================='
print cls
print name
print baseClass
print dict
print '===================' attrib = {}
attrib['houdini'] = ''
attrib['maya'] = ''
attrib['nuke'] = ''
return super(MetaClass, cls).__new__(cls,name,baseClass,attrib) class Foo2(object):
__metaclass__ = MetaClass if __name__ == "__main__":
print Foo2.houdini
print Foo2.maya
print Foo2.nuke
结果:
===================
<class '__main__.MetaClass'>
Foo2
(<type 'object'>,)
{'__module__': '__main__', '__metaclass__': <class '__main__.MetaClass'>}
===================
1
2
3
PyQt5 对应python2.7
pip install python-qt5
..
Effective_Python mapreduce的更多相关文章
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- mapreduce多文件输出的两方法
mapreduce多文件输出的两方法 package duogemap; import java.io.IOException; import org.apache.hadoop.conf ...
- mapreduce中一个map多个输入路径
package duogemap; import java.io.IOException; import java.util.ArrayList; import java.util.List; imp ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- [Hadoop in Action] 第5章 高阶MapReduce
链接多个MapReduce作业 执行多个数据集的联结 生成Bloom filter 1.链接MapReduce作业 [顺序链接MapReduce作业] mapreduce-1 | mapr ...
- MapReduce
2016-12-21 16:53:49 mapred-default.xml mapreduce.input.fileinputformat.split.minsize 0 The minimum ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- MapReduce剖析笔记之八: Map输出数据的处理类MapOutputBuffer分析
在上一节我们分析了Child子进程启动,处理Map.Reduce任务的主要过程,但对于一些细节没有分析,这一节主要对MapOutputBuffer这个关键类进行分析. MapOutputBuffer顾 ...
- MapReduce剖析笔记之七:Child子进程处理Map和Reduce任务的主要流程
在上一节我们分析了TaskTracker如何对JobTracker分配过来的任务进行初始化,并创建各类JVM启动所需的信息,最终创建JVM的整个过程,本节我们继续来看,JVM启动后,执行的是Child ...
随机推荐
- Android:理解Fragment
最近都在公司搞测试,静不下心来学android.今天就把Fragment搞懂吧. Fragment的几点要点: 1.用于大屏幕平板,容纳更多组件,可复用2.Fragment必须嵌入Activity中 ...
- 简单的自定义Adapter
import android.content.Context; import android.view.LayoutInflater; import android.view.View; import ...
- QWeb、Widget继承
对于Odoo前端来说,所有的js对象都是继承自openerp.web.Class这个类,然后由此派生出Widget,由Widget派生出其他诸如View等可视化部件,结合QWeb,我们可以实现对现有部 ...
- 利用call与apply向函数传递参数
Js中函数对象都有call与apply两个方法属性,二者使用方法和功能一样,只是传递参数的格式不同,call逐个传递单个参数,apply一次性传递一个参数数组. 这两个方法可以改变函数的调用对象,并且 ...
- 安装redis,执行make test时遇到You need tcl 8.5 or newer in order to run the Redis test
安装他yum install tcl
- 配置非默认端口的监听Listener
- lua库函数
这些函数都是Lua编程语言的一部分, 点击这里了解更多. assert(value) - 检查一个值是否为非nil, 若不是则(如果在wow.exe打开调试命令)显示对话框以及输出错误调试信息 col ...
- 在win7下安装unbuntu系统
1.分盘 准备EasyBCD,ubuntu操作系统 配置EasyBCD,安装ubuntu http://www.linuxidc.com/Linux/2014-04/100369.htm http:/ ...
- codeforces480E Parking Lot
题目大意:给一个点阵,其中有的地方没有点,操作是去掉某个点,并询问当前点阵中最大的正方形 若没有修改的话,裸dp 加上修改,可以考虑时光倒流,这样答案就是递增的 可以用并查集维护点的连通性,O^2的 ...
- Print all nodes at distance k from a given node
Given a binary tree, a target node in the binary tree, and an integer value k, print all the nodes t ...