[Python]南邮OJ代码备份爬虫
之前看过Python学习的经验,说以project为导向学习。
自己分析了一下,一般接触Python的都有一定的其它语言基础,对于程序设计的基本逻辑,语法都有一个大概的了解。而Python这样的脚本语言。没有过于独特的语法,在一定的其它语言的基础上。更是能够直接上手的。
之前看Python简明教程,半天没有进度。正好遇上Python爬虫项目,直接上手,方便快捷。
站点:http://acm.njupt.edu.cn/welcome.do?
method=index,正值系统更新,于是写一个备份代码的爬虫。
使用的Python库
urllib库:
这个库封装了通过URL与网络server通信的方法。包括HTTP的request,response等等。眼下为止基本够用。
re库:
即regularexpress,正則表達式库。用来在HTML文档中检索信息。
基本框架
首先通过HTTP协议,向目标server提交request请求,然后接受response应答。
我们再从应答中,得到我们须要的内容:用户cookie和代码。最后新建本地文件,把他们放进去就可以。
详细步骤
A.HTTP请求
Python果然是短平快的语言,例如以下三行搞定:
myUrl ="http://acm.njupt.edu.cn/acmhome/index"#目标页面
req=urllib2.Request(myUrl)#用URL得到request对象
myResponse = urllib2.urlopen(req)#通过urlopen()函数发送request,得到返回的response
myPage = myResponse.read()#在response中读取页面信息
B.登入权限获取
分析页面我们看到,要备份代码须要提交username与password。并且提交的页面不是主页,而是登陆页。依据HTTP的知识,须要用POST方法提交包括表单信息的request。使用chrome开发者工具,检測到提价的表达包括例如以下内容。

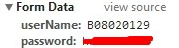
这在Python中也好实现:
myUrl ="http://acm.njupt.edu.cn/acmhome/login.do"#url地址改为登入页
self.postdata = urllib.urlencode({
'userName':self.userName,
'password':self.passWord
})#{}中为Python的字典结构数据,传入username和password
#urlencode()函数把字典结构编码为特定的data类
req=urllib2.Request(
url = myUrl,
data = self.postdata
)
#给Request传入URL以及编码好的data数据
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
C.处理cookie
之前的还少考虑了一个东西。就是登入后要訪问站点的其它页面时。须要用到登入的cookie。
Python中没有特殊定义的訪问貌似是不保留cookie的。于是我们要从写一个可保留cookie的HTTP通信方式。
首先是Python中的几个概念:
opener:用于通信的对象,之前代码中urllib.urlopen()使用系统默认的opener,等价于default_opener.urlopen()
handler:一个opener包括多个hander。用于处理通信间的各种子问题,包括cookie问题。
于是,上面处理cookie的方法就是。重写一个opener,给予其可处理cookie的handler。
cookie_support =urllib2.HTTPCookieProcessor(cookielib.CookieJar())
#新建cookie_handler
opener =urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
#用cookie_handler建立cookie_opener
urllib2.install_opener(opener)
#设定为默认opener
到此,我们能够实现登入权限获取。
D.定位到代码页面
我们要从首页開始,找到代码页面。本来直接获取URL就可以。
只是发现代码页面URL例如以下:

这个页面包括了时间和登入信息的未知编码。应该是通过转义的。这里的解决方法是通过已知页面获取URL而不是手动输入。
分析页面后。能够例如以下获得代码页面:
首页-->用户信息-->通过代码-->’G++|GCC|JAVA’字段超链接,例如以下
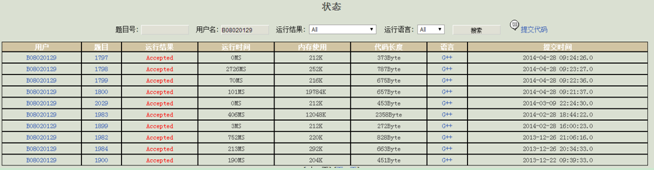
于是,解析获得的HTML,得到超链接:
myItem = re.findall('<ahref=\"/acmhome/solutionCode\.do\?id\=.*?\"\ ',myPage,re.S)
for item in myItem:
url='http://acm.njupt.edu.cn/acmhome/solutionCode.do?
id='+item[37:len(item)-2]
E.扣去文本
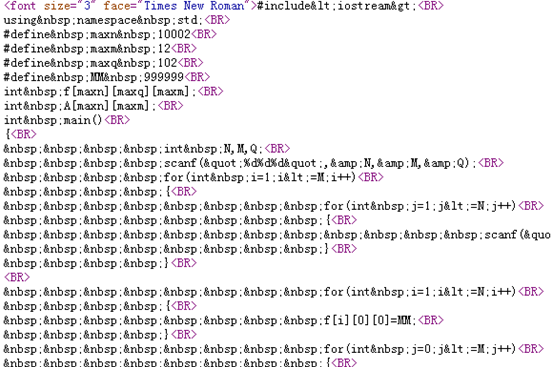
如上。能够看出站点是用XML来存储,转义为HTML。于是我们要替换文本中的转义标签。得到正常文本:
class Tool:
A= re.compile(" \;")
B= re.compile("\<BR\>")
C= re.compile("<\;")
D= re.compile(">\;")
E= re.compile(""\;")
F= re.compile("&")
G= re.compile("Times\ New\ Roman\"\>")
H= re.compile("\</font\>")
I= re.compile("'")
J= re.compile("语言:(.*)?face=\"",re.DOTALL)
def replace_char(self,x):
x=self.A.sub(" ",x)
x=self.B.sub("\r",x)
x=self.C.sub("<",x)
x=self.D.sub(">",x)
x=self.E.sub("\"",x)
x=self.F.sub("&",x)
x=self.G.sub("",x)
x=self.H.sub("",x)
x=self.I.sub("\'",x)
x=self.J.sub("",x)
return x
*注意,Python中字符串有替换函数,str.replace(替换字符,原字符)。只是假设要依据正則表達式来替换。须要用re模块的re.sub()函数才行。replace不能使用正則表達式。
*还有。replace返回替换的字符串,原始字符串没有不论什么改变
F.存入文件
首先要得到代码的中文题目作为文件名称。只是这在自己的代码页看不到,仅仅能到代码主页去找。找到后抓取<title>中的字段作为用户名就可以。
tname=re.findall('title\>.*?\</title',p,re.S)
f =open(tname[0][6:len(tname[0])-7]+'_'+sname[8:len(sname)-8]+'.txt','w+')
f.write(self.mytool.replace_char(mytem[0]))
f.close()
终于程序
# -*- coding: cp936 -*-
#copyright by B08020129 import urllib2
import urllib
import re
import thread
import time
import cookielib cookie_support =urllib2.HTTPCookieProcessor(cookielib.CookieJar())
opener = urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
urllib2.install_opener(opener) class Tool:
A= re.compile(" \;")
B= re.compile("\<BR\>")
C= re.compile("<\;")
D= re.compile(">\;")
E = re.compile(""\;")
F = re.compile("&")
G =re.compile("Times\ New\ Roman\"\>")
H= re.compile("\</font\>")
I= re.compile("'")
J= re.compile("语言:(.*)?face=\"",re.DOTALL)
def replace_char(self,x):
x=self.A.sub(" ",x)
x=self.B.sub("\r",x)
x=self.C.sub("<",x)
x=self.D.sub(">",x)
x=self.E.sub("\"",x)
x=self.F.sub("&",x)
x=self.G.sub("",x)
x=self.H.sub("",x)
x=self.I.sub("\'",x)
x=self.J.sub("",x)
return x class HTML_Model:
def __init__(self,u,p):
self.userName = u
self.passWord =p
self.mytool = Tool()
self.page = 1
self.postdata = urllib.urlencode({
'userName':self.userName,
'password':self.passWord
})
def GetPage(self):
myUrl = "http://acm.njupt.edu.cn/acmhome/login.do"
req=urllib2.Request(
url = myUrl,
data = self.postdata
)
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
flag = True
while flag:
myUrl="http://acm.njupt.edu.cn/acmhome/showstatus.do? problemId=null&contestId=null&userName="+self.userName+"&result=1&language=&page="+str(self.page)
#print(myUrl)
myResponse = urllib2.urlopen(myUrl)
myPage = myResponse.read()
st="\<a\ href\=.*?G\+\+"
next = re.search(st,myPage)
if next:
flag = True
else:
flag = False
myItem = re.findall('<ahref=\"/acmhome/solutionCode\.do\?id\=.*?\"\ ',myPage,re.S)
for item in myItem:
#print(item)
url='http://acm.njupt.edu.cn/acmhome/solutionCode.do?id='+item[37:len(item)-2]
#print(url)
myResponse =urllib2.urlopen(url)
myPage = myResponse.read()
mytem = re.findall('语言.*? </font>.*?Times NewRoman\"\>.*?\</font\>',myPage,re.S)
#print(mytem)
sName = re.findall('源码--.*?</strong',myPage,re.S)
for sname in sName:
#print(sname[2:len(sname)-8])
name="http://acm.njupt.edu.cn/acmhome/problemdetail.do?&method=showdetail&id="+sname[8:len(sname)-8];
#print(name)
p=urllib2.urlopen(name).read()
#print(p)
tname=re.findall('title\>.*?\</title',p,re.S)
print(tname[0][6:len(tname[0])-7]+'_'+sname[8:len(sname)-8])
f =open(tname[0][6:len(tname[0])-7]+'_'+sname[8:len(sname)-8]+'.txt','w+')
f.write(self.mytool.replace_char(mytem[0]))
f.close()
print('done!')
self.page = self.page+1 print u'plz input the name'
u=raw_input()
print u'plz input password'
p=raw_input()
myModel =HTML_Model(u,p)
myModel.GetPage()
得到文件

以及文件里的正常代码:

下一步用更好地方法试着一键注冊及提交全部代码。
[Python]南邮OJ代码备份爬虫的更多相关文章
- 南邮oj[1401] 乘车费用
Description lqp家离学校十分十分远,同时他又没有钱乘taxi.于是他不得不每天早早起床,匆匆赶到公交车站乘车到学校.众所周知CZ是个公交车十分发达的地方,但是CZ的公交车十分的奇怪,lq ...
- (转)Python新手写出漂亮的爬虫代码2——从json获取信息
https://blog.csdn.net/weixin_36604953/article/details/78592943 Python新手写出漂亮的爬虫代码2——从json获取信息好久没有写关于爬 ...
- (转)Python新手写出漂亮的爬虫代码1——从html获取信息
https://blog.csdn.net/weixin_36604953/article/details/78156605 Python新手写出漂亮的爬虫代码1初到大数据学习圈子的同学可能对爬虫都有 ...
- 南邮ctf-web的writeup
WEB 签到题 nctf{flag_admiaanaaaaaaaaaaa} ctrl+u或右键查看源代码即可.在CTF比赛中,代码注释.页面隐藏元素.超链接指向的其他页面.HTTP响应头部都可能隐藏f ...
- 南邮CTF - Writeup
南邮CTF攻防平台Writeup By:Mirror王宇阳 个人QQ欢迎交流:2821319009 技术水平有限~大佬勿喷 ^_^ Web题 签到题: 直接一梭哈-- md5 collision: 题 ...
- 【python】一个简单的贪婪爬虫
这个爬虫的作用是,对于一个给定的url,查找页面里面所有的url连接并依次贪婪爬取 主要需要注意的地方: 1.lxml.html.iterlinks() 可以实现对页面所有url的查找 2.获取页面 ...
- python中执行javascript代码
python中执行javascript代码: 1.安装相应的库,我使用的是PyV8 2.import PyV8 ctxt = PyV8.JSContext() ctxt.enter() ...
- 南邮CTF--md5_碰撞
南邮CTF--难题笔记 题目:md5 collision (md5 碰撞) 解析: 经过阅读源码后,发现其代码是要求 a !=b 且 md5(a) == md5(b) 才会显示flag,利用PHP语言 ...
- 南邮JAVA程序设计实验1 综合图形界面程序设计
南邮JAVA程序设计实验1 综合图形界面程序设计 实验目的: 学习和理解JAVA SWING中的容器,部件,布局管理器和部件事件处理方法.通过编写和调试程序,掌握JAVA图形界面程序设计的基本方法. ...
随机推荐
- C#.NET常见问题(FAQ)-程序如何单步调试和设置断点
对于控制台程序而言,直接按F10(不按F5运行)就可以单步运行,当前运行行会显示为黄色(不管是一条语句,还是一个函数,都会直接执行完毕得到结果) 你可以在变量名上右击添加监视(会自动放到监视1中) ...
- C#应用视频教程3.4 Halcon+C#测试
有了前面的基础后,我们来测试一下如何把程序做的更通用,首先是把初始化的方法修改一下,在初始化的时候传递过去HTuple这个对象(改成了全局的变量,以便于不同的方法调用) 其次需要有相机打开/相机关 ...
- cocos lua 加密与解密 混淆 (版本号cocos3.4)
cocos luacompile cocos luacompile Overview Usage Available Arguments Samples Overview Compile the .l ...
- 安装apache+php记录
安装apache yum install httpd 修改apache配置文件,可以修改apache的默认端口号,根目录等 /etc/httpd/conf/httpd.conf 启动/重启apache ...
- 吐槽一下Page Restore
以前觉得Page Restore确实挺好用的,而且确实用Page Restore快速解决过一些问题.但是仔细想想很多时候Page Restore可能根本用不上. 因为SQL Server在备份的时候是 ...
- 你的灯亮着吗pdf –读书笔记
十句话概括这本书 1.确认问题比找到方法更重要 2.解决问题其实解决的是"人的期待" 3.你在解决问题中可能会发现新的机会 4.要了解问题的可变性和复杂性 5.站在用户而不 ...
- java面试第十一天
多线程: 进程与线程: 进程:同一个操作系统中执行的一个子程序,包含了三部分虚拟CPU.代码.数据 多进程:同一个操作系统中执行的多个并行的子程序.可以提高cpu的使用率 线程:在同一个进程当中执行的 ...
- MySQL主从常见的架构
Master-Slave 级联 双Master互为主备
- python之函数用法__str__()
# -*- coding: utf-8 -*- #python 27 #xiaodeng #python之函数用法__str__() #http://www.cnblogs.com/hongfei/p ...
- 【laravel5.4】git上clone项目到本地,配置和运行 项目报错:../vendor/aotuload.php不存在
1.一般我们直接使用git clone 将git的项目克隆下来,在本地git库和云上git库建立关联关系 2.vendor[扩展]文件夹是不会上传的,那么下载下来直接运行项目,会报错: D:phpSt ...