UNIX高级环境编程(6)标准IO函数库 - 流的概念和操作
标准IO函数库隐藏了buffer大小和分配的细节,使得我们可以不用关心预分配的内存大小是否正确的问题。
虽然这使得这个函数库很容易用,但是如果我们对函数的原理不熟悉的话,也容易遇到很多问题。
1 流和FILE实体(Streams and FILE Objects)
前面的章节中,IO集中在文件描述符,每一个打开的文件都对应一个文件描述符,通过文件描述符对文件进行操作。
现在使用了标准IO库,讨论的重点集中在流(streams)。
简要了解一下流:
- 当我们打开或创建了一个文件,我们说我们有一个流和该文件关联。
- stream支持单字节字符集和多字节字符集。stream的属性orientation决定使用单字符集还是多字符集。
- 当一个stream被创建时,没有指定orientation,这时,当使用宽字符集IO函数时,流的orientation设置为支持宽字符集;当使用单字符集IO函数时,流的orientation设置为支持单字符集。
只有两个函数可以修改流的orientation:
- freopen会清除流的orientation;
- fwide用来设置流的orientation。
fwide函数声明:
#include <stdio.h>
#include <wchar.h>
int fwide(FILE* fp, int mode);
函数返回值:
- 返回整数表示支持多字节字符集;
- 返回负数表示支持单字节字符集;
- 返回0表示没有设置stream的orientation。
mode取值的不同决定函数fwide的不同的行为:
- 如果mode为负数,fwide试着设置指定流支持单字节字符集;
- 如果mode为整数,fwide试着设置指定流支持多字节字符集;
- 如果mode为0,fwide不会试着设置流的orientation,但是会返回一个值代表当前流的orientation。
当我们打开一个流,函数fopen返回一个指向FILE对象的指针。FILE对象通常是一个结构体,包含所有控制流所需要的信息,包括:
- 实际IO所用的文件描述符;
- 一个指向流所使用的buffer的指针;
- buffer的大小;
- 当前在buffer中的字符数;
- error flag;
- 等。
2 缓存(Buffering)
缓存(buffering)的作用是为了尽可能少地调用read和write系统调用。
标准IO库提供三种类型的buffering:
完全缓存(Fully buffered):在这种缓存机制中,实际的IO操作发生在缓存被写满时。正在写入硬盘的文件被完全缓存在buffer中。缓存空间往往在第一次IO操作时通过调用malloc函数获取;
行缓存(Line buffered):在这种缓存机制中,实际的IO操作发生在新的一行字符被读入或者输出时,所以允许每一次只输出一个字符。行缓存有两点需要注意:buffer的大小是固定的,所以即使当前行没有读入或输出结束,依然可能发生实际的IO,当buffer被写满时;一旦有输入(从无缓存流或者行缓存流中输入)发生,所以已在buffer中缓存的输出流都会被立刻输出(flush)。
flush:标准IO缓存中内容立刻写入硬盘或者输出。在终端设备中,flush的作用也可能是丢弃缓存中得数据。
无缓存(Unbuffered):不缓存输入或输出内容。例如,如果我们使用fputs函数输出15个字符,那么我们希望这15个字符尽可能快地被打印出来。如标准错误输出就要求是无缓存输出。
ISO C标准要求下面的缓存特性:
- 标准输入输出在不关联交互设备的请款下,使用完全缓存(fully buffered);
- 标准错误输出不使用完全缓存。
上面的标准显然没有具体说明各种情况,一般来说:
- 标准错误输出不适用缓存;
- 其他流,如果关联终端,则使用行缓存,否则使用完全缓存。
我们可以使用函数setbuf和setvbuf函数更改流的缓存机制。
函数声明:
#include <stdio.h>
void setbuf(FILE* restrict fp, char* restrict buf);
int servbuf(FILE *restrict fp, char* restrict buf, int mode, size_t size);
函数返回值:
- OK:0;
- Error:非0
这些函数必须在流打开之后,其他流操作执行之前被调用。
函数作用:
setbuf可以打开或关闭缓存,打开缓存时,buf指向一个大小为BUFSIZ(stdio.h中定义的宏)的buffer,通常打开的时完全缓存,如果当前流关联的是终端设备,有的系统也会使用行缓存;
servbuf可以指定打开哪种类型的缓存。mode的参数可以取如下的值,如果指定为无缓存,则参数buf和size都会被忽略。

函数行为总结如下表所示:

通常来说,我们应该让系统自己选择buffer大小并自动分配,这样标准IO库会在关闭流时自动释放该内存。
flush函数。
函数声明:
#include <stdio.h>
int fflush(FILE *fp);
函数作用:
使得该流的所有缓存中未写入硬盘的数据传入内核中。
一种特殊情况是,如果fp为NULL,fflush会使得所有缓存的数据都被flush。
3 打开流(opening a stream)
函数fopen、freopen和fdopen函数用来打开一个标准输入输出流。
函数声明:
#include <stdio.h>
FILE *fopen(const char *restrict pathname, const char* restrict type);
FILE *freopen(const char *restrict pathname, const char *restrict type, FILE *restrict fp);
FILE *fdopen(int fd, const char *type);
函数细节:
- 函数fopen打开指定的文件;
- 函数freopen函数打开指定的文件到指定的流上,如果该流已经被打开,则先关闭该流;如果之前已经被打开的流设置了orientation,则清理。函数freopen通常用来打开文件到预定义的流上,如标准输入,标准输出或标准错误输出;
- fdopen输入一个文件描述符,将描述符关联到一个标准IO流上。函数fdopen的作用主要是为了将管道和网络连接关联到一个流上,而这些特殊类型的文件不能使用fopen函数打开,我们必须先用特定的函数获取文件描述符,然后用fdopen函数关联到一个流上。
参数type取值如下表所示,一共有15种取值,有得取值作用相同:

表格说明:
- 参数中的b字符为了让标准IO系统区分文本文件(text file)和二进制文件(binary file),因为内核并不区分文件文件和二进制文件,所以b字符并不影响内核的行为。
- 函数fdopen的参数type和其他的稍有不同。因为文件描述符已经被打开,所以打开文件流并不截断文件至长度为0。
- 标准IO库函数的append模式不可以用来创建新文件,因为要得到一个文件描述符,必须先打开一个存在的文件。
- 同样支持多进程同时以append模式写同一个文件。
当打开一个流对文件进行读写时,有两个限制:
- 输入后,如果不调用函数fflush, fseek, fsetpos或rewind的话,不可以紧接着进行输出。
- 输出后,如果不调用该函数fseek, fsetpos或rewind的话,不可以紧接着进行输入。
六种方式打开一个流总结如下表所示:
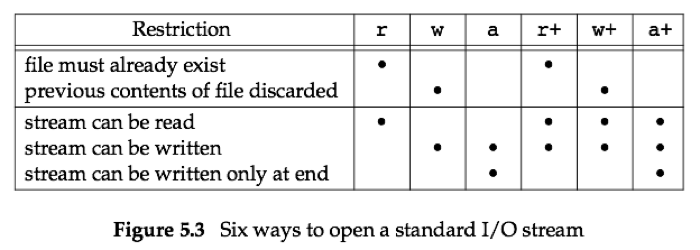
需要注意的一点是,当以w和a模式创建一个新文件时,并不能像open或create函数一样指定文件的权限标志位。
一种解决方法是通过调整我们的umask。
打开的流默认的是完全缓存,如果该流关联的是终端设备,则是行缓存。
像之前提到的那样,我们打开了一个流,并在其他操作之前,可以调用setbuf或setvbuf函数修改缓存方式。
关闭流
函数声明:
#include <stdio.h>
int fclose(FILE* fp);
函数细节,关闭流之前:
- 所有缓存待输出的数据都会被输出;
- 所有缓存带输入的数据都会被丢弃;
- 如果流使用的缓存是由标准IO库分配,则缓存会被释放;
- 如果进程正常终止,则所有缓存数据都会被flush(输出或者写入硬盘),并且所有打开的流都会被关闭。
4 读写一个流(Reading and Writing a Stream)
当我们打开一个流,我们有三种读写方式可供选择:
- 一次一个字符读写
- 一次一行读写:使用函数fgets和fputs
- 直接读写:每次读写固定长度的数据,使用函数fread和fwrite。
输入函数
函数声明:
#include <stdio.h>
int getc(FILE* fp);
int fgetc(FILE* fp);
int getchar(void);
函数返回值:
- ok:下一个字符
- EOF:文件结尾,一般为-1
- error:负数
函数细节:
- getchar和getc不同的地方在于:前者一定实现为函数,而后者可以被实现为一个宏;
- 函数返回值将unsigned char转型为int,这里,unsigned是为了转型为int时不会是负数。返回整数的目的是为了让所有可能的值都可以返回,包括错误码和文件结尾;
- 文件结尾符EOF往往定义为负数,而错误码也是负数,因此我们无法从返回值上判断是到达了文件结尾还是报错。
- 为了区分上面的两种情况,我们需要调用函数ferror或者feof。
函数声明:
#include <stdio.h>
int ferror(FILE* fp);
int feof(FILE* fp); // Both return: nonzero(true) if condition is true, 0(false) otherwise
void clearerr(FILE* fp);
在大多的实现中,FILE对象中会维护两个flag:
- 一个error flag
- 一个文件结尾符flag
这两个flag都可以通过调用clearerr清空。
读取一个流后,我们可以调用函数ungetc压回读出来的字符。
函数声明:
#include <stdio.h>
int ungetc(int c, FILE* fp);
函数返回值:c if OK, EOF on error
函数细节:只支持单个个字符的压回。
使用场景:
压回操作常使用在下面的场景:对于一个输入流,我们需要根据下一个字符来判断该如何处理当前的字符。
输出函数
输出函数和我们讨论过的输入函数一一对应,不再赘述。
函数声明:
#include <stdio.h>
int putc(int c, FILE* fp);
int fputc(int c, FILE* fp);
int putchar(int c);
5 逐行输入输出操作(Line-at-a-Time IO)
函数fgets和gets提供了逐行输入功能。
函数声明:
#include <stdio.h>
char *fgets(char* restrict buf, int n, FILE* restrict fp);
char *gets(char* buf);
函数细节:
- 两个函数都是读取一行数据至buffer中。
- 函数gets从标准输入流中读取,fgets从指定的输入流中读取。
- fgets需要我们指定缓冲区大小,读入的一行数据不得多于n-1个字符,以NULL结尾。如果fgets读取该行数据长度大于n,则该次只读取n-1个字符,并以null结尾,剩余的字符在下次调用fgets时读入。
- gets函数不推荐使用,因为它不做越界检查。
函数fputs和puts提供了逐行输出的功能。
函数声明:
#include <stdio.h>
int fputs(const char* restrict str, FILE* restrict fp);
int puts(const char* str);
函数细节:
- fputs函数将一个以null结尾的字符串输出到指定流中,最后的null byte并不输出;
- puts函数同样会输出一个以null结尾的字符串到标准输出,最后的null byte并不输出,输出结束后会输出一个换行符;
- 所以我们也不推荐使用puts函数,防止自动输出一个换行符,但是我们在使用fputs时要记得在必要的时候自己处理换行符。
6 标准输入输出效率分析
比较标准:
将一定量的数据从标准输入拷贝到标准输出,计算这一过程所需要的
- 用户CPU时间(User CPU)
- 系统CPU时间(System CPU)
- Clock time
- 程序文本大小
Code:
使用getc和putc的版本:
#include "apue.h"
int
main(void)
{
int c;
while ((c = getc(stdin)) != EOF)
if (putc(c, stdout) == EOF)
err_sys("output error");
if (ferror(stdin))
err_sys("input error");
exit(0);
}
使用fgets和fputs的版本:
#include "apue.h"
int
main(void)
{
char buf[MAXLINE];
while (fgets(buf, MAXLINE, stdin) != NULL)
if (fputs(buf, stdout) == EOF)
err_sys("output error");
if (ferror(stdin))
err_sys("input error");
exit(0);
}
测试数据:95.8M 3百万行
测试结果(和第三章中的数据进行了对比,之前跳过了该章节,可以自行查看一下):
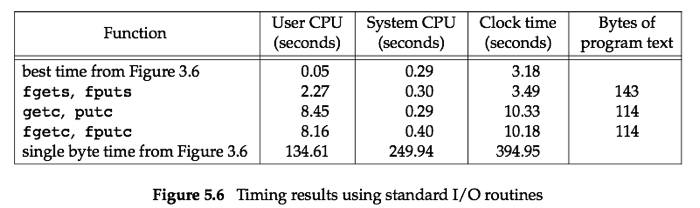
结果说明:
- 可以发现标准IO库函数User CPU时间都比read版本的最好时间要大,因为逐字符读写需要执行100million次循环,逐行读写需要执行3百万次循环,而第一行使用的read的最有版本执行了25224次循环;
- clock time的差异原因在于用户态时间的差异和等待IO完成的时间上的差异;
- System CPU时间基本和之前版本的相同,因为内核请求数基本相同。因此,在不关心buffer大小和分配,或者只需要关心一行buffer大小的使用下,获取了几乎最优的buffer选择。
- 最后一列显示了编译器编译后生成的汇编文件的大小。
- 逐行读写比逐字符读写快得多,因为fgets和fputs是用memccpy实现,memccpy函数用汇编来实现,效率更高。
- fgetc版本比read版本的最差时间(BUFFSIZE=1)要快得多,原因在于read版本会执行200million次函数调用,由于无缓存机制,所以相应的也会执行200million次系统调用,而fgetc版本也会执行200million次函数调用,但是由于缓存机制,只需要执行25224次系统调用。我们知道,系统调用的开销要比函数调用大得多。
7 小结
标准IO函数库分为两篇来介绍,本篇是第一篇,主要介绍了
- 流的基本概念
- 流的基本操作,包括打开、关闭、读写
- 对比了使用标准IO库的读写效率
参考资料:
《Advanced Programming in the UNIX Envinronment 3rd》
UNIX高级环境编程(6)标准IO函数库 - 流的概念和操作的更多相关文章
- UNIX高级环境编程1
UNIX高级环境编程1 故宫角楼是很多摄影爱好者常去的地方,夕阳余辉下的故宫角楼平静而安详. 首先,了解一下进程的基本概念,进程在内存中布局和内容. 此外,还需要知道运行时是如何为动态数据结构(如链表 ...
- UNIX高级环境编程(7)标准IO函数库 - 二进制文件IO,流定位,创建临时文件和内存流
1 二进制IO(Binary IO) 在前一篇我们了解了逐字符读写和逐行读写函数. 如果我们在读写二进制文件,希望以此读写整个文件内容,这两个函数虽然可以实现,但是明显会很麻烦且多次循环明显效率很低. ...
- 第3章 文件I/O(8)_贯穿案例:构建标准IO函数库
9. 贯穿案例:构建标准IO函数库 //mstdio.h #ifndef __MSTDIO_H__ #define __MSTDIO_H__ #include <unistd.h> #de ...
- UNIX高级环境编程(14)文件IO - O_DIRECT和O_SYNC详解 < 海棠花溪 >
春天来了,除了工作学习,大家也要注意锻炼身体,多出去运动运动. 上周末在元大都遗址公园海棠花溪拍的海棠花. 进入正题. O_DIRECT和O_SYNC是系统调用open的flag参数.通过指定o ...
- UNIX高级环境编程(13)信号 - 概念、signal函数、可重入函数
信号就是软中断. 信号提供了异步处理事件的一种方式.例如,用户在终端按下结束进程键,使一个进程提前终止. 1 信号的概念 每一个信号都有一个名字,它们的名字都以SIG打头.例如,每当进程调用了ab ...
- 高级UNIX环境编程5 标准IO库
标准IO库都围绕流进进行的 <stdio.h><wchar.h> memccpy 一般用汇编写的 ftell/fseek/ftello/fseeko/fgetpos/fsetp ...
- Unix高级环境编程
[07] Unix进程环境==================================1. 进程终止 atexit()函数注册终止处理程序. exit()或return语句: ...
- UNIX高级环境编程(9)进程控制(Process Control)- fork,vfork,僵尸进程,wait和waitpid
本章包含内容有: 创建新进程 程序执行(program execution) 进程终止(process termination) 进程的各种ID 1 进程标识符(Process Identifie ...
- UNIX高级环境编程(5)Files And Directories - 文件相关时间,目录文件相关操作
1 File Times 每个文件会维护三个时间字段,每个字段代表的时间都不同.如下表所示: 字段说明: st_mtim(the modification time)记录了文件内容最后一次被修改的时 ...
随机推荐
- 术语CDATA,其实可以理解为一种特殊的转移字符
参考:http://www.w3school.com.cn/xml/xml_cdata.asp 常见于XML文档,所有 XML 文档中的文本均会被解析器解析. 只有 CDATA 区段(Charact ...
- 面试题27:单链表向右旋转k个节点
Given a list, rotate the list to the right by kplaces, where k is non-negative. For example:Given1-& ...
- java面试⑥框架部分
2.5.1 什么是框架: 2.5.2 MVC模式 2.5.3 MVC框架 2.5.4 简单讲一下struts2的执行流程 2.5.5 Struts2中的拦截器,你都用它干什么? 2.5.6 简单讲一下 ...
- [转]验证发生前无法调用 Page.IsValid。应在 CausesValidation=True 且已启动回发的控件
在ASP.Net中,为了方便表单的验证,提供了验证控件来完成表单输入数据的验证.这些验证控件确实是功能强大,为写表单程序提供了极大的便利.但是,在不熟悉的情况下,经常碰到问题.其中,最常见的是遇到错误 ...
- vue权限路由实现方式总结二
之前已经写过一篇关于vue权限路由实现方式总结的文章,经过一段时间的踩坑和总结,下面说说目前我认为比较"完美"的一种方案:菜单与路由完全由后端提供. 菜单与路由完全由后端返回 这种 ...
- TFS Negotiate方式登录的IIS配置
使用vsts-agent连接到tfs(tfs2017)配置代理客户端,可以通过PAT.Negotiate.Integrated.Alternate四种方式登录.(参考) 默认情况下,采用Negotia ...
- Oracle.DataAccess.Client.OracleConnection.Open()报错System. NullReferenceException
使用ODAC链接Oracle数据库时,conn.Open()报错:未将对象的实例设置到对象引用. Oracle.DataAccess.dll版本:4.121.2.0 ODAC RELEASE 4 Or ...
- 基于asp.net mvc的近乎产品开发培训课程(第三讲)
演示产品源码下载地址:http://www.jinhusns.com/Products/Download
- Winform无边框窗体拖动
调用示例 当然,BUG还是有的,不过基本需求倒也可以
- 解决Coursera平台上Andrew.Ng的机器学习课程无法正常提交编程作业的问题
课程链接:https://www.coursera.org/learn/machine-learning/home/welcome 我使用的环境是MATLAB R2016a,Win10系统. 执行su ...