NLPIR(北理工张华平版中文分词系统)的SDK(C++)调用方法
- 一、本文内容简介
- 二、具体内容
- 1. 中文分词的基本概念
- 2.关于NLPIR(北理工张华平版中文分词系统)的基本情况
- 3.具体SDK模块(C++)的组装方式
- ①准备内容:
- ②开始组装
- 三.注意事项
一、本文内容简介
- 关于中文分词的基本概念
- 关于NLPIR(北理工张华平版中文分词系统)的基本情况
- 具体SDK模块(C++版)的组装方法
二、具体内容
1. 中文分词的基本概念
中文分词是自然语言处理的一个分支,自然语言即人们在日常生活中使用的语言,包含书面语,口语,例如报纸上的一篇通讯,博客里面的一篇文章。之所以称其为自然语言,是因为它区别于计算机语言,计算机语言的文法与组织方式较为规范,自然语言则贴近人们生活。自然语言处理作为一项技术,在搜索引擎,机器语义理解和对话系统中有着基础和决定性的作用和价值,这方面比较知名的例如微软的cortana(微软小娜),以及国内各个互联网公司发布的智能音箱等。
2.关于NLPIR(北理工张华平版中文分词系统)的基本情况
北理工张华平版中文分词系统(NLPIR),又名中科院分词系统,是国内高校院所中开源力度相当大的一家(下文将简称北理工分词系统),另一家是哈工大中文分词系统(LTP)。北理工分词系统功能丰富,目前已经包含了以下功能:
- 全文检索
- 新词发现
- 分词标注
- 统计分析与术语翻译大数据聚类与热点分析
- 大数据文本过滤
- 自动摘要
- 关键词提取
- 文档去重
- HTML正文提取
- 编码自动识别与转换
NLPIR提供的组件包中含有13种SDK组件包:
- Classify规则组件
- Cluster聚类组件
- DeepClassifier训练分类组件
- DocExtractor实体抽取组件
- HTMLPaser网站正文提取组件
- NLPIR-ICTCLAS分词组件
- JZsearch精准搜索组件
- JZSearch精准搜索客户端组件
- KeyExtract关键词提取组件
- RedupRemover文档去重组件
- Sentiment情感组件
- SentimentAnalysis情感分析组件
- Summary摘要组件
每个组件包内容介绍
- doc:使用说明文档和API文档
- include:头文件
- lib:linux32,linux64,win32,win64等不同版本的库
- projects:开发工程包
- sample:C#,C++,java等不同语言的案例
- Data:数据库
3.具体SDK模块(C++)的组装方式
注:以下组装方式以实体抽取模块(DocExtractor)为例,平台为VS2012
①准备内容:
前往Github下载源码,源码的数据量在740MB左右,因为DNS被禁的原因,一般网络的下载速度比较慢,几十kb的样子。博主的解决方法是使用国内的代码托管平台,例如博主使用的是码云( https://gitee.com),可以与Github关联同一个账户,将Github中的项目fork到码云中再进行下载,速度可以上每秒0.5MB。解压之后,如下图所示
整个github项目解压后的内瓤
实体抽取组件的路径为:NLPIR\NLPIR SDK\DocExtractor,其中包含的文件如下图
SDK中所含内容
②开始组装
1.点击新建—>项目—>其他语言—>Visual C++ —>空项目,名称为:DocExtractorCppTest,解决方案名称为:NLPIR-DE;如下图所示
新建空项目
2.将路径(NLPIR\NLPIR SDK\DocExtractor\projects\DocExtractor_c++)中的main.cpp文件拷贝到项目目录下(我的路径为NLPIR-DE\DocExtractorCppTest\)。
3.把路径(NLPIR\NLPIR SDK\DocExtractor\lib\win32)下的DocExtractor.dll以及DocExtractor.lib两个文件拷贝到项目目录下(我的路径为NLPIR-DE\DocExtractorCppTest\)。
4.将(NLPIR\License\license for a month\DocExtractor文档提取授权)下面的DocExtractor.user拷贝到路径NLPIR\NLPIR SDK\DocExtractor\Data下
5.将DATA文件夹拷贝到新建的解决方案目录下
6.将路径NLPIR\NLPIR SDK\DocExtractor\include下的文件DocExtractor.h拷贝到项目目录下,我的路径为NLPIR-DE\DocExtractorCppTest
7.经过以上操作,新建项目文件如下图
解决方案目录下
项目目录下
9.在VS中右键单击项目—>添加—>现有项,把项目目录下的四个文件 DocExtractor.dll,DocExtractor.h,DocExtractor.lib,main.cpp添加进去,点击运行,而后报错,如下图所示,正常现象,这是因为部分代码没有修改的缘故。
10.将如图所示的红色框中的代码去掉就可以,使dll文件及lib文件正确读取。
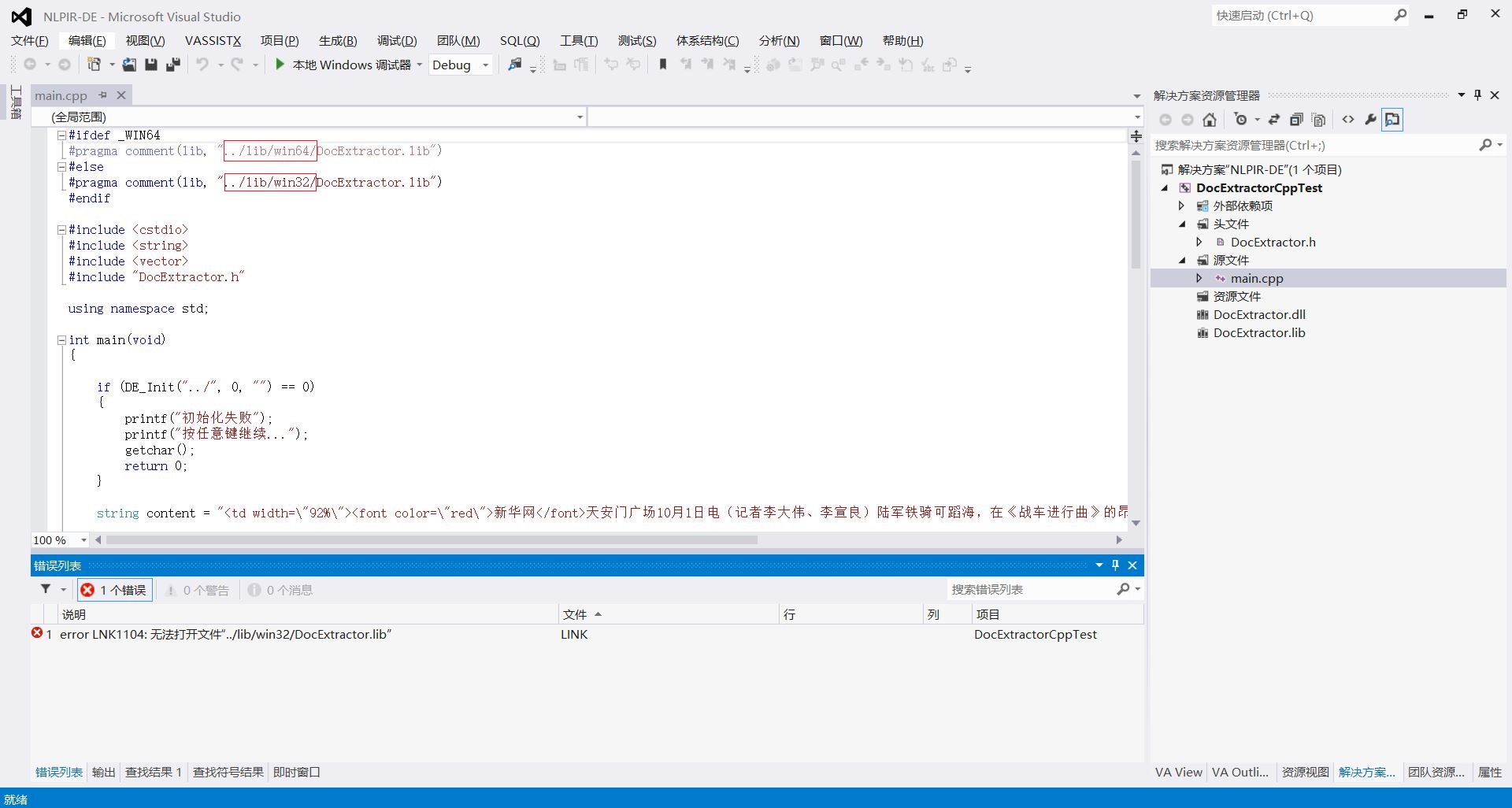 去代码
去代码
11.去掉之后再点击运行就可以正常运行了,效果如下
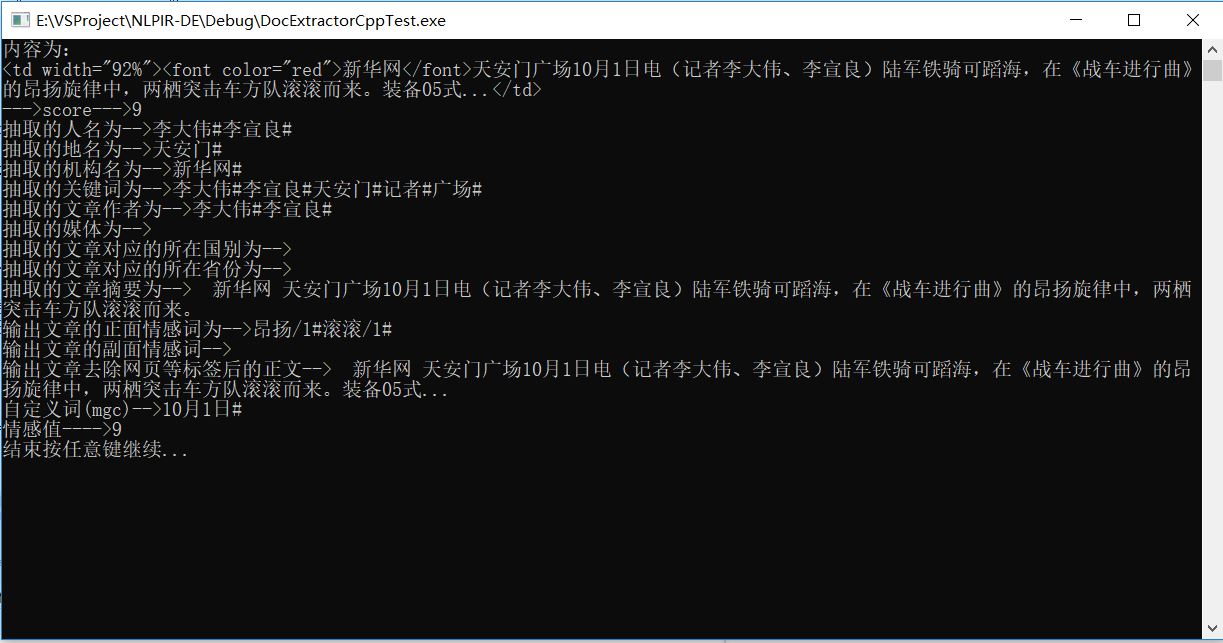
三.注意事项
- 之所以去掉红框中标注的代码是要把dll与lib的文件路径修改正确
- license授权文件每月更新一次,因此DATA文件夹下的授权文件DocExtractor.user要保持最新版本 2019-04-06 16:51:44
NLPIR(北理工张华平版中文分词系统)的SDK(C++)调用方法的更多相关文章
- Python环境下NIPIR(ICTCLAS2014)中文分词系统使用攻略
一.安装 官方链接:http://pynlpir.readthedocs.org/en/latest/installation.html 官方网页中介绍了几种安装方法,大家根据个人需要,自行参考!我采 ...
- 【原创】中文分词系统 ICTCLAS2015 的JAVA封装和多线程执行(附代码)
本文针对的问题是 ICTCLAS2015 的多线程分词,为了实现多线程做了简单的JAVA封装.如果有需要可以自行进一步封装其它接口. 首先ICTCLAS2015的传送门(http://ictclas. ...
- Sphinx中文分词安装配置及API调用
这几天项目中需要重新做一个关于商品的全文搜索功能,于是想到了用Sphinx,因为需要中文分词,所以选择了Sphinx for chinese,当然你也可以选择coreseek,建议这两个中选择一个,暂 ...
- (转)Sphinx中文分词安装配置及API调用
这几天项目中需要重新做一个关于商品的全文搜索功能,于是想到了用Sphinx,因为需要中文分词,所以选择了Sphinx for chinese,当然你也可以选择coreseek,建议这两个中选择一个,暂 ...
- 中文分词工具探析(一):ICTCLAS (NLPIR)
1. 前言 ICTCLAS是张华平在2000年推出的中文分词系统,于2009年更名为NLPIR.ICTCLAS是中文分词界元老级工具了,作者开放出了free版本的源代码(1.0整理版本在此). 作者在 ...
- 推荐十款java开源中文分词组件
1:Elasticsearch的开源中文分词器 IK Analysis(Star:2471) IK中文分词器在Elasticsearch上的使用.原生IK中文分词是从文件系统中读取词典,es-ik本身 ...
- Java开源中文分词类库
IKAnalyzer IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本.最初,它是以开 ...
- postgres中的中文分词zhparser
postgres中的中文分词zhparser postgres中的中文分词方法 基本查了下网络,postgres的中文分词大概有两种方法: Bamboo zhparser 其中的Bamboo安装和使用 ...
- 新浪SAE中文分词接口
最近发现新浪SAE平台上竟然也提供分词功能,分词效果也还不错,由新浪爱问提供的分词服务,研究了一番,做了一个简易版的在线调用接口(get方式,非post) 官网说明:http://apidoc.sin ...
随机推荐
- 612.1.004 ALGS4 | Elementary Sorts - 基础排序算法
sublime编辑器写代码,命令行编译 减少对ide的依赖//可以提示缺少什么依赖import 所有示例代码动手敲一遍 Graham's Scan是经典的计算几何算法 shffule 与 map-re ...
- 612.1.003 ALGS4 | Stacks and Queues
Algorithm | Coursera - by Robert Sedgewick Type the code one by one! 不要拜读--只写最有感触的!而不是仅仅做一个笔记摘录员,那样毫 ...
- 【Python】Java程序员学习Python(三)— 基础入门
一闪一闪亮晶晶,满天都是小星星,挂在天上放光明,好像许多小眼睛.不要问我为什么喜欢这首歌,我不会告诉你是因为有人用口琴吹给我听. 一.Python学习文档与资料 一般来说文档的资料总是最权威,最全面的 ...
- 直到黎明 Until Dawn 后感
直到黎明 会免游戏.白金神作.近些年的恐怖电影都有游戏化的趋势,韩国的某岩vlog,美国的真心话大冒险,都把观众作为meta代入游戏,几乎模糊了游戏与游戏的边界,直到黎明这部电影,与当年的暴雨和超凡双 ...
- spring boot(11)-druid监控
druid druid是和tomcat jdbc一样优秀的连接池,出自阿里巴巴.关于druid连接池参数,参考 https://github.com/alibaba/druid/wiki/DruidD ...
- linux上设置mysql编码
linux下设置mysql编码 linux下设置mysql编码 首先查找MySql的cnf文件的位置: [root@flyHome gaoxiang]# find / -iname '*.cnf' - ...
- hdfs基本操作-python接口
安装hdfs包 pip install hdfs 查看hdfs目录 [root@hadoop hadoop]# hdfs dfs -ls -R / drwxr-xr-x - root supergro ...
- Oracle EBS AP银行显示不全
- Sqlserver2014 迁移数据库
由于当初安装sqlserver 的时候选择默认安装的路径,导致现在c盘爆满,安装不了其它软件.因此想到了迁移数据库,网上搜索了一些简介,但是缺少一些步骤,导致数据库附加的时候失败.现总结如下: 1.将 ...
- win10 虚拟机 hyper-v 安装 centos 7
一.win 10 企业版 自带虚拟机 hyper-v 1.控制面板-->程序和功能-->启用或关闭Windows功能 勾上 hyper-v 确定就ok了 2.安装成功后会发现在 左下角“开 ...