论文笔记:分形网络(FractalNet: Ultra-Deep Neural Networks without Residuals)
FractalNet: Ultra-Deep Neural Networks without Residuals
ICLR 2017
Gustav Larsson, Michael Maire, Gregory Shakhnarovich
文章提出了什么(What)
- ResNet提升了深度网络的表现,本文提出的分形网络也取得了优秀的表现,通过实验表示,残差结构对于深度网络来说不是必须的。
- ResNet缺乏正则方法,本文提出了drop-path,对子路径进行随机丢弃
为什么有效(Why)
- 分形网络不像resNet那样连一条捷径,而是通过不同长度的子路径组合,网络选择合适的子路径集合提升模型表现
- drop-path是dropout(防止co-adaption)的天然扩展,是一种正则方法,可以防止过拟合,提升模型表现
- drop-path提供了很好的正则效果,在不用数据增强时也取得了优秀的结果
- 通过实验说明了带drop-path训练后的总网络提取的单独列(网络)也能取得优秀的表现。
- 分形网络体现的一种特性为:浅层子网提供更迅速的回答,深层子网提供更准确的回答。
分形网络是怎么做的(How)
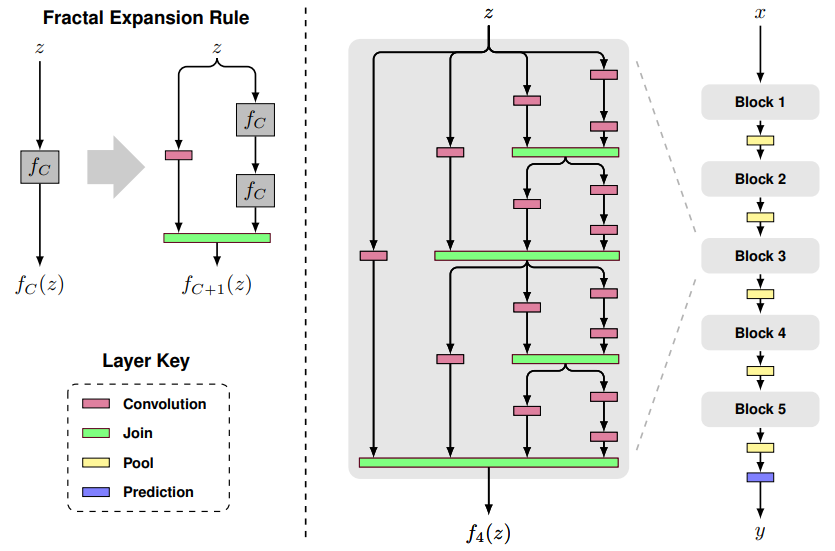
- 图中以粉红色的卷积层Convolution为基础层,实际上可以为其它类型的层或者子网络;绿色的Join层一般可以用相加或concat,这里采取了相加然后取平均,因此所有基础层可以使用一样的channel数量
- $ f_{C}(z) $ 中C表示列数,z表示输入,C=1表示一个基础层
- $ f_{C+1}(z) $ 则如图所示,在右边叠加两个$ f_{C}(z) $ ,左边接一个基础层
- 以此类推,当C等于4的时候,可以得到图中的$ f_{4}(z) $
- $ f_{4}(z) $作为一个block中,如图中最右边的网络所示,完整的网络接了5个block,block之间用Pool层连接,最后是预测层
- 令block个数为B,每个block中的列数为C,网络的总深度为$ B\cdot 2^{C-1} $
两种drop-path
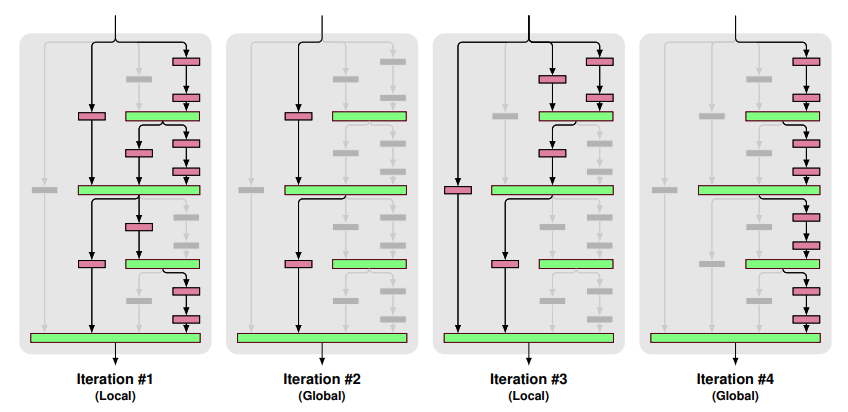
实验训练的时候,mini-batch之间交叉使用Local和Global
- Local:对join层的输入dropout,但是至少保证要有一个输入
- Global: 对于整个网络来说,只选择一条路径,且限制为某个单独列,所以这条路径是独立的强预测路径
模型对比的实验
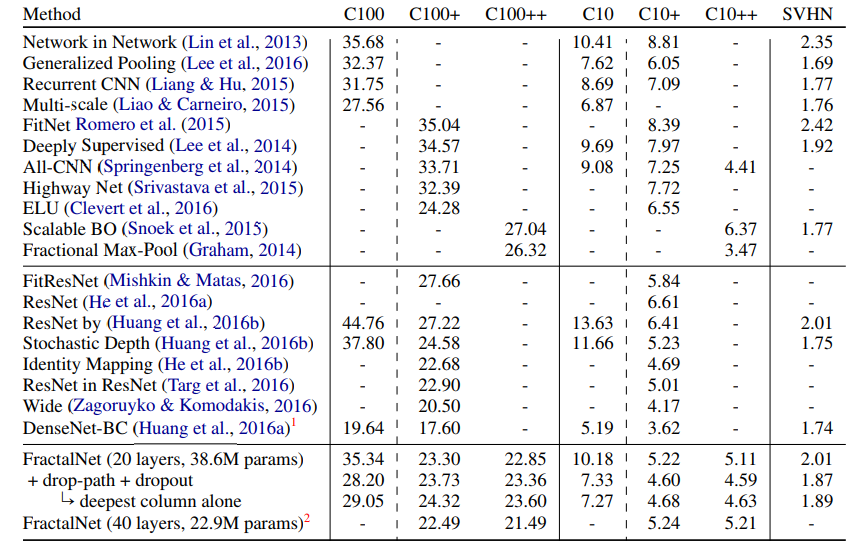
- +表示使用了水平镜像翻转和平移,++表示使用了更多的数据增强,实验主要和ResNet对比
- 用drop-path训练,可以从网络提取最深的单独列,在表格数据中可以看出也取得了不错的表现
- 不使用数据增强时,分形网络的表现超过了ResNet,可以看出分形网络更不容易过拟合
- 使用数据增强时,分形网络取得了和ResNet变种差不多的表现
- 不使用数据增强的时候,drop-path提升了表现
- 使用数据增强的时候,drop-path提升或者没有下降太大的表现
20层分形网络的模型细节
- 每个卷积层后面加了BN(先卷积,再BN,再relu激活)
- B=5,C=3
- 训练集都是32*32*3的图像,使用2*2的Max-pooling,经过5次下采样后32*32会变成1*1,最后的预测层使用softmax
- 为了实现方便,对于每一个block,调换了最后面的pool和join的顺序
- 五个block的卷积核数量默认为64,128,256,512,512
- 每个block最后的dropout概率设为0,0.1,0.2,0.3,0.4
- 整个网络的local drop-path设为0.15
- caffe实现,学习率为0.02,momentum为0.9,batchsize为100,使用Xavier初始化参数
- CIFAR-10/CIFAR-100迭代了400轮,SVHN迭代了20轮
- 每当“剩余epoch数减半”时,学习率除以10(比如剩余epoch为200时,剩余epoch为100时,剩余epoch为50时候)
其它实验
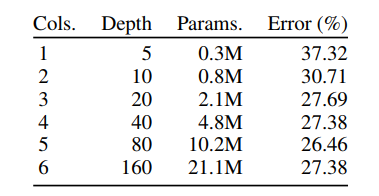
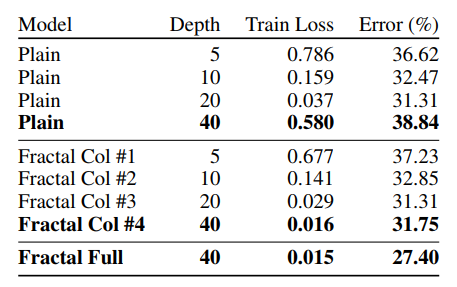
- 分形网络到了160层开始出现退化
- 平常的网络到了40层就出现了退化,到了160层不能收敛
- 使用了drop-path的分形网络提取的单独列(网络)比平常的网络取得了更优的表现,而且克服了退化问题(平常网络40层就退化)
- 这里的实验减小了每个block的channels,为16,32,64,128,128,batchsize设置为50
学习曲线
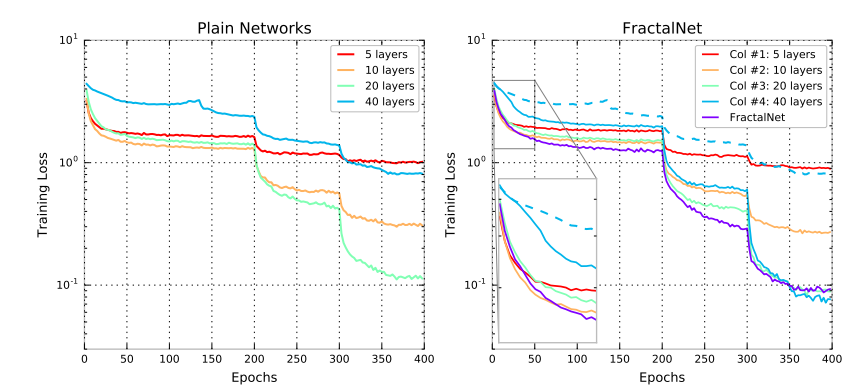
- 40层分形网络的学习曲线中,可以看到Col#4 开始学习时很慢,当其它子网学习趋近稳定时,Col#4学习速度提升
- 左图平常网络的学习曲线中没有这种性质(蓝色虚线)
- 假设分形网络会触发和深度监督,横向的“学生-教师”信息流类似的效果,那么可以这样分析,当分形网络依赖于单独使用Col#3来输出,当drop-path丢弃Col#3的时候,网络则会促进Col#4的学习,使得Col#4学的东西能代替Col#3,这是一个迷你的学生-教师问题
总结
- 论文的实验说明了路径长度才是训练深度网络的需要的基本组件,而不单单是残差块
- 分形网络和残差网络都有很大的网络深度,但是在训练的时候都具有更短的有效的梯度传播路径
- 分形网络简化了对这种需求(更短的有效的梯度传播路径)的满足,可以防止网络过深
- 多余的深度可能会减慢训练速度,但不会损害准确性
论文笔记:分形网络(FractalNet: Ultra-Deep Neural Networks without Residuals)的更多相关文章
- 论文笔记——Data-free Parameter Pruning for Deep Neural Networks
论文地址:https://arxiv.org/abs/1507.06149 1. 主要思想 权值矩阵对应的两列i,j,如果差异很小或者说没有差异的话,就把j列与i列上(合并,也就是去掉j列),然后在下 ...
- 【论文笔记】Malware Detection with Deep Neural Network Using Process Behavior
[论文笔记]Malware Detection with Deep Neural Network Using Process Behavior 论文基本信息 会议: IEEE(2016 IEEE 40 ...
- 论文翻译:2018_Source localization using deep neural networks in a shallow water environment
论文地址:https://asa.scitation.org/doi/abs/10.1121/1.5036725 深度神经网络在浅水环境中的源定位 摘要: 深度神经网络(DNNs)在表征复杂的非线性关 ...
- 论文笔记之:Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
Learning Multi-Domain Convolutional Neural Networks for Visual Tracking CVPR 2016 本文提出了一种新的CNN 框架来处理 ...
- 【论文笔记】Pyramidal Convolution: Rethinking Convolutional Neural Networks for Visual Recognition
地址:https://arxiv.org/pdf/2006.11538.pdf github:https://github.com/iduta/pyconv 目前的卷积神经网络普遍使用3×3的卷积神经 ...
- Deep Learning 16:用自编码器对数据进行降维_读论文“Reducing the Dimensionality of Data with Neural Networks”的笔记
前言 论文“Reducing the Dimensionality of Data with Neural Networks”是深度学习鼻祖hinton于2006年发表于<SCIENCE > ...
- 论文笔记:Mastering the game of Go with deep neural networks and tree search
Mastering the game of Go with deep neural networks and tree search Nature 2015 这是本人论文笔记系列第二篇 Nature ...
- 论文笔记-IGCV3:Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks
论文笔记-IGCV3:Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks 2018年07月11日 14 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
随机推荐
- JPA条件查询时间区间用LocalDateTime的问题
@Override public Page<Order> findAll(String outTradeNo, String tradeNo, String mchAppid, Strin ...
- [NOIp2015]运输计划 (二分 $+$ 树上差分)
#\(\mathcal{\color{red}{Description}}\) \(Link\) 在一棵带有边权的树上,可以选择使一条边权为零.然后对于所有\(M\)条链,使其链长最大值最小. #\( ...
- 拥抱.NET Core系列:MemoryCache 缓存选项 (转载)
阅读目录 MSCache项目 MemoryCacheOptions ExpirationScanFrequency SizeLimit CompactionPercentage 写在最后 在上一篇 ” ...
- 【vue】vue生命周期解读 (流程+钩子函数)
参考详细说明一波简书 (vue中钩子函数解读) 1.实例渲染流程 2.生命周期钩子函数比 钩子函数详解简书一 钩子函数详解简书二
- 学习java前端 两种form表单提交方式
第一种:原生方式 注意点:button标签的style为submit <form action="/trans/doTrans.do" method="post&q ...
- Xcode解决“Implicit declaration of function 'XXX' is invalid in C99” 警告或报错
1.Build Setting>>>C Language Dialect,然后选择GNU99[-std=gnu99] (选择看项目实际要求). 2.Build Setting> ...
- OpenGL ES画板
一.概述 利用自定义顶点和片元着色器渲染,并且设置图片纹理颜色为画笔颜色 二.核心代码 - (void)renderLineFromPoint:(CGPoint)start toPoint:(CGPo ...
- canvas绘制折线图(仿echarts)
遇到的问题:Retina屏上字体线条模糊问题 解决方案:放大canvas的大小,然后用css压缩回原大小,例如:想要900*400的画布,先将画布设置为 width="1800px" ...
- mimikatz将结果输出到一个文本的命令
mimikatz.exe "privilege::debug" "sekurlsa::logonpasswords" > pssword.txt
- 使用LINQ的Skip和Take函数分批获取数据
Skip函数和Take函数是System.Linq对类Enumberable的扩展, 其中Skip函数是跳过序列中的前n个数据,参数为需要跳过的数据量, Take函数是取序列中的n个数据,参数为要获取 ...