Scala + Thrift+ Zookeeper+Flume+Kafka配置笔记
1. 开发环境
1.1. 软件包下载
1.1.1. JDK下载地址
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
安装到 D:\GreenSoftware\Java\Java8X64\jdk1.8.0_91 目录
1.1.2. Maven下载地址
https://maven.apache.org/download.cgi
解压到 D:\GreenSoftware\apache-maven-3.3.9 目录
1.1.3. Scala下载地址
https://www.scala-lang.org/download/
解压到 D:\GreenSoftware\Java\scala-2.12.6 目录
1.1.4. Thrift下载地址
http://thrift.apache.org/download
将下载的thrift-0.11.0.exe文件放到 D:\Project\ServiceMiddleWare\thrift目录下,并重命名为thrift.exe
1.1.5. Zookeeper
https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/current/
解压到 D:\Project\ServiceMiddleWare\zookeeper-3.4.10目录
1.1.6. Flume下载地址
http://flume.apache.org/download.html
解压到 D:\Project\ServiceMiddleWare\flume-1.8.0目录
1.1.7. Kafka下载地址
http://kafka.apache.org/downloads
解压到 D:\Project\ServiceMiddleWare\kafka_2.12-1.1.0 目录
1.2. JDK+Maven+Scala+Thrift
1.2.1. 环境变量
JAVA_HOME D:\GreenSoftware\Java\Java8X64\jdk1.8.0_91
CLASSPATH .;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
MAVEN_HOME D:\GreenSoftware\apache-maven-3.3.9
SCALA_HOME D:\GreenSoftware\Java\scala-2.12.6
PATH 中加入
%JAVA_HOME%\bin;
%MAVEN_HOME%\bin;
%SCALA_HOME%\bin;
D:\Project\ServiceMiddleWare\thrift;
1.3. 安装、配置及验证
1.3.1. JDK
C:\Users\zyx>java -version
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
C:\Users\zyx>
1.3.2. Maven
C:\Users\zyx>mvn -version
Apache Maven 3.3.9 (bb52d8502b132ec0a5a3f4c09453c07478323dc5; 2015-11-11T00:41:47+08:00)
Maven home: D:\GreenSoftware\apache-maven-3.3.9\bin\..
Java version: 1.8.0_91, vendor: Oracle Corporation
Java home: D:\GreenSoftware\Java\Java8X64\jdk1.8.0_91\jre
Default locale: zh_CN, platform encoding: GBK
OS name: "windows 10", version: "10.0", arch: "amd64", family: "dos"
1.3.3. Scala
C:\Users\zyx>scala -version
Scala code runner version 2.12.6 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.
C:\Users\zyx>scala
Welcome to Scala 2.12.6 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_91).
Type in expressions for evaluation. Or try :help.
scala> :quit
C:\Users\zyx>
1.3.4. Thrift
C:\Users\zyx>thrift -version
Thrift version 0.11.0
1.3.5. Zookeeper
1.3.5.1. 配置
在D:\Project\ServiceMiddleWare\zookeeper-3.4.10\conf目录下创建一个zoo.cfg文件,内容如下
tickTime=2000
dataDir=D:/Project/ServiceMiddleWare/zookeeper-3.4.10/data/db
dataLogDir=D:/Project/ServiceMiddleWare/zookeeper-3.4.10/data/log
clientPort=2181
# Zookeeper Cluster
# server.1=127.0.0.1:12888:1388
# server.2=127.0.0.1:12889:1389
# server.3=127.0.0.1:12887:1387
1.3.5.2. 启动Zookeeper
D:\Project\ServiceMiddleWare\zookeeper-3.4.10\bin\zkServer.cmd
1.3.5.3. 启动客户端
D:\Project\ServiceMiddleWare\zookeeper-3.4.10\bin\zkCli.cmd -server 127.0.0.1:2181
1.3.5.4. 基本命令
查看目录
ls /
1.3.5.5. 创建节点
create /config 0
1.3.5.6. 删除节点
delete /config
1.3.5.7. 退出客户端
quit
1.3.6. Kafka
1.3.6.1. 配置
1.3.6.1.1. Kafka的配置文件
修改D:\Project\ServiceMiddleWare\kafka_2.12-1.1.0\config目录下的server.properties文件,内容如下
broker.id=0
port=9092
host.name=127.0.0.1
# listeners=PLAINTEXT://127.0.0.1:9092
# register zookeeper’s node data
# advertised.listeners=PLAINTEXT://127.0.0.1:9092
# log.dirs=/tmp/kafka-logs
log.dirs=D:/Project/ServiceMiddleWare/kafka_2.12-1.1.0/data/log
log.dir = D:/Project/ServiceMiddleWare/kafka_2.12-1.1.0/data/log
# zookeeper.connect=localhost:2181
zookeeper.connect=127.0.0.1:2181
# Zookeeper Cluster
# zookeeper.connect=127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
1.3.6.1.2. 日志的配置
修改D:\Project\ServiceMiddleWare\kafka_2.12-1.1.0\config目录下的log4j.properties文件,内容如下
kafka.logs.dir=D:/Project/ServiceMiddleWare/kafka_2.12-1.1.0/data/log
log.dir = /tmp/kafka-logs
1.3.6.1.3. 端口配置(如果同一台服务器配置多个Kafka,则需要)
修改D:\Project\ServiceMiddleWare\kafka_2.12-1.1.0\bin\windows目录下的kafka-run-class.bat文件,在文件开头增加内容如下
set JMX_PORT=19093
set JAVA_DEBUG_PORT =5005
1.3.6.2. 启动Kafka
D:\Project\ServiceMiddleWare\kafka_2.12-1.1.0\bin\windows\kafka-server-start.bat D:\Project\ServiceMiddleWare\kafka_2.12-1.1.0\config\server.properties
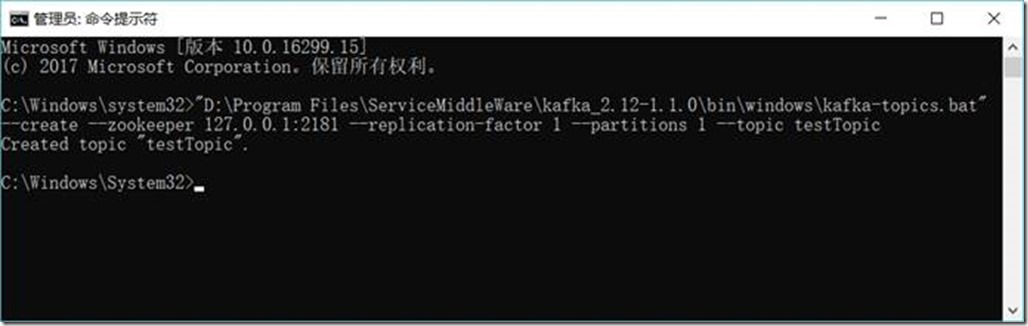
1.3.6.3. 创建主题(Topic)
D:\Project\ServiceMiddleWare\kafka_2.12-1.1.0\bin\windows\kafka-topics.bat --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic testTopic
1.3.6.4. 创建生产者(Producer)
D:\Project\ServiceMiddleWare\kafka_2.12-1.1.0\bin\windows\kafka-console-producer.bat --broker-list 127.0.0.1:9092 --topic testTopic
1.3.6.5. 创建消费者(Consumer)
D:\Project\ServiceMiddleWare\kafka_2.12-1.1.0\bin\windows\kafka-console-consumer.bat --zookeeper 127.0.0.1:2181 --topic testTopic
1.3.6.6. 生成者发送消息
Hello world
你好
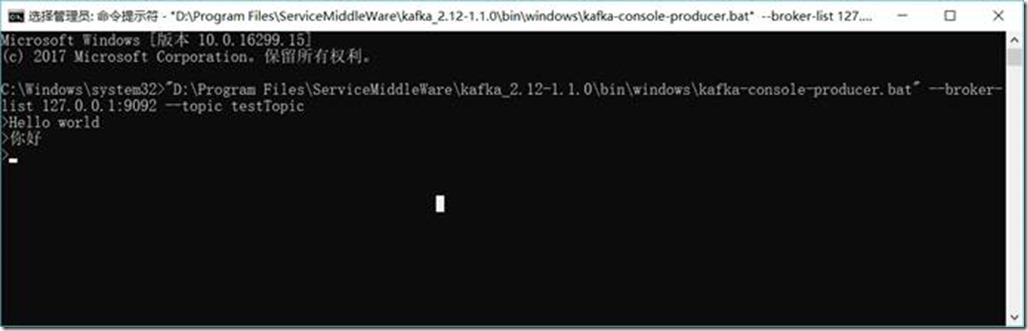
1.3.6.7. 消费者收到消息
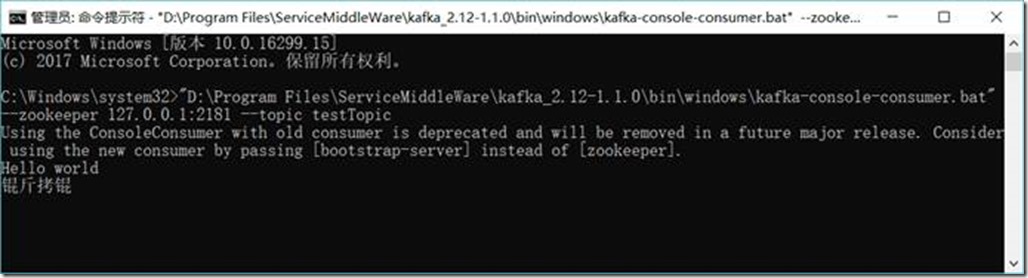
1.3.6.8. 查看主题(Topic)状态
D:\Project\ServiceMiddleWare\kafka_2.12-1.1.0\bin\windows\kafka-topics.bat --describe --zookeeper 127.0.0.1:2181 --topic testTopic
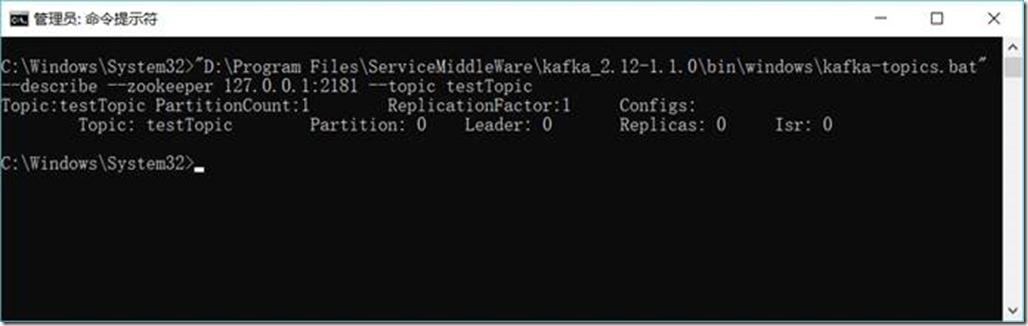
1.3.6.9. 彻底删除topic
https://blog.csdn.net/odailidong/article/details/61615554
1.3.7. Flume
1.3.7.1. 配置
1.3.7.1.1. Flume的配置文件
在D:\Project\ServiceMiddleWare\flume-1.8.0\conf目录下创建一个flume.agent1.conf文件,内容如下:
# flume.agent1.conf: A single-node Flume listen netcat configuration
# Name the components on this agent
agent1.sources = sources1
agent1.sinks = sinks1
agent1.channels = channels1
# Describe/configure the source
# agent1.sources.sources1.type = Avro, Exec, HTTP, JMS, Netcat, Sequence generator, Spooling directory, Syslog, Thrift, Twitter
agent1.sources.sources1.type = netcat
agent1.sources.sources1.bind = 127.0.0.1
agent1.sources.sources1.port = 44444
agent1.sources.source1.interceptors = interceptor1
# agent1.sources.source1.interceptors.interceptor1.type = Host, Morphline, Regex extractor, Regex filtering, Static, Timestamp, UUID
agent1.sources.source1.interceptors.interceptor1.type = timestamp
# Describe the sink
# agent1.sinks.sinks1.type = Avro, Elasticsearch, File roll, HBase, HDFS, IRC, Logger, Morphline(Solor), Null, Thrift
agent1.sinks.sinks1.type = logger
# Use a channel which buffers events in memory
# agent1.channels.channels1.type = File, JDBC, Memory
agent1.channels.channels1.type = memory
agent1.channels.channels1.capacity = 1000
agent1.channels.channels1.transactionCapacity = 100
# Bind the source and sink to the channel
agent1.sources.sources1.channels = channels1
agent1.sinks.sinks1.channel = channels1
1.3.7.1.2. 日志的配置
修改D:\Project\ServiceMiddleWare\flume-1.8.0\conf目录下的log4j.properties文件,内容如下
# flume.log.dir=./logs
flume.log.dir=D:/Project/ServiceMiddleWare/flume-1.8.0/data/log
1.3.7.2. 启动Flume
D:\Project\ServiceMiddleWare\flume-1.8.0\bin\flume-ng.cmd agent -conf D:/Project/ServiceMiddleWare/flume-1.8.0/conf -conf-file D:/Project/ServiceMiddleWare/flume-1.8.0/conf/flume.agent1.conf -name agent1 -property flume.root.logger=INFO,console
或
cd D:\Project\ServiceMiddleWare\flume-1.8.0\bin
flume-ng.cmd agent -conf ../conf -conf-file ../conf/flume.agent1.conf -name agent1 -property flume.root.logger=INFO,console
1.3.7.3. 访问44444端口,模拟数据输入
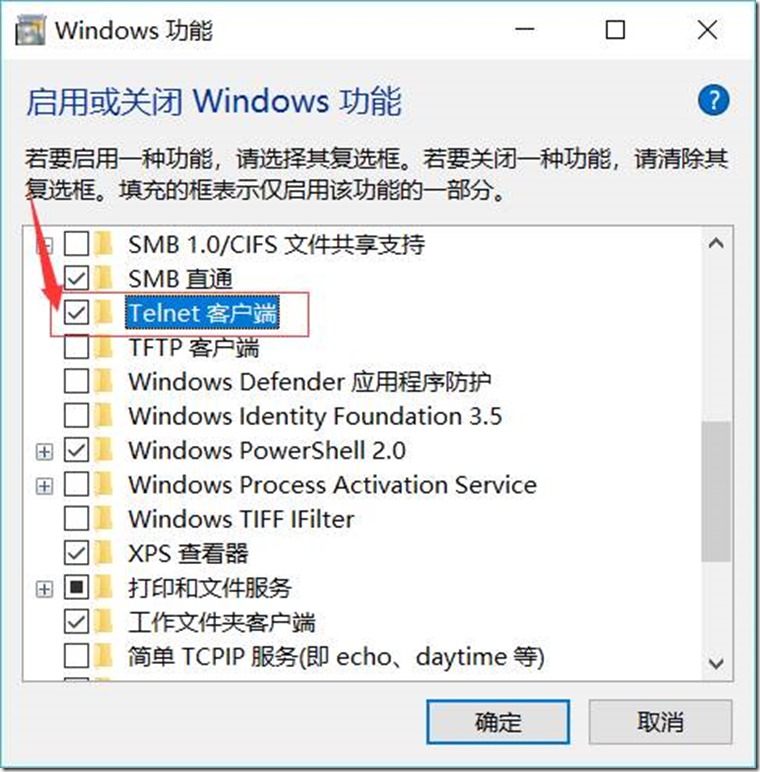
telnet 127.0.0.1 44444
然后输入任意内容
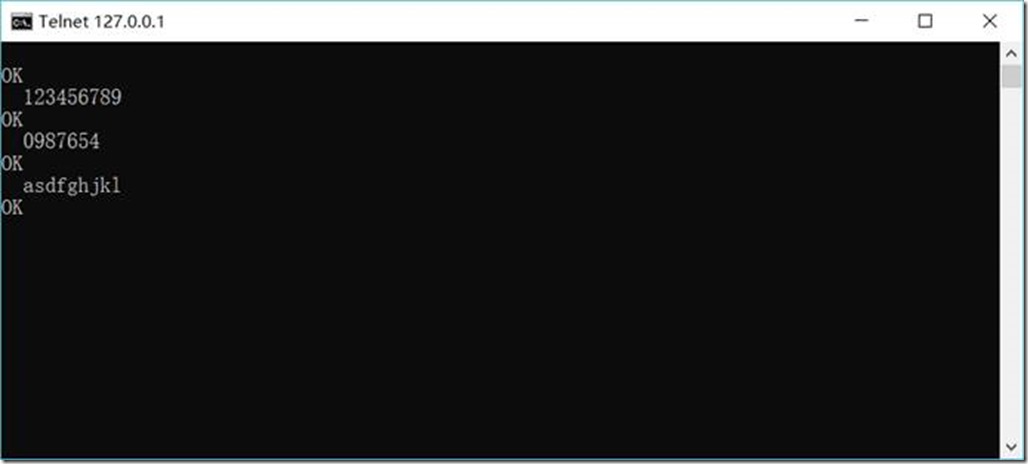
查看Flume接收结果:
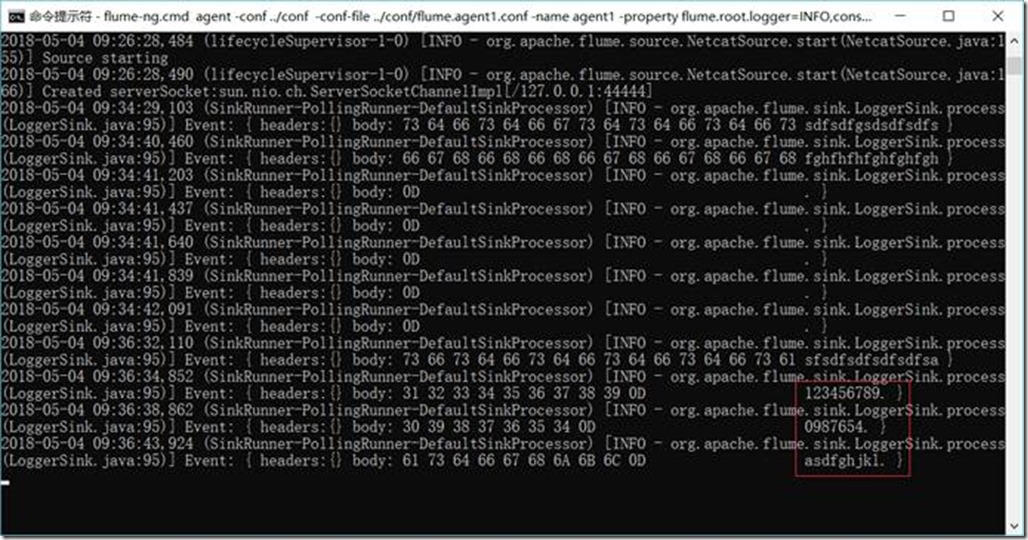
1.3.8. Flume与Kafka连接
1.3.8.1. Flume的配置
在D:\Project\ServiceMiddleWare\flume-1.8.0\conf目录下修改flume.agent1.conf文件,内容如下:
# flume.agent1.conf: A single-node Flume listen netcat configuration
# Name the components on this agent
agent1.sources = sources1
agent1.sinks = sinks1
agent1.channels = channels1
# Describe/configure the source
# agent1.sources.sources1.type = Avro, Exec, HTTP, JMS, Netcat, Sequence generator, Spooling directory, Syslog, Thrift, Twitter
agent1.sources.sources1.type = netcat
agent1.sources.sources1.bind = 127.0.0.1
agent1.sources.sources1.port = 44444
agent1.sources.source1.interceptors = interceptor1
# agent1.sources.source1.interceptors.interceptor1.type = Host, Morphline, Regex extractor, Regex filtering, Static, Timestamp, UUID
agent1.sources.source1.interceptors.interceptor1.type = timestamp
# Describe the sink
# agent1.sinks.sinks1.type = Avro, Elasticsearch, File roll, HBase, HDFS, IRC, Logger, Morphline(Solor), Null, Thrift
# agent1.sinks.sinks1.type = logger
agent1.sinks.sinks1.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.sinks1.kafka.topic = testTopic
agent1.sinks.sinks1.kafka.bootstrap.servers = 127.0.0.1:9092
agent1.sinks.sinks1.kafka.flumeBatchSize = 20
agent1.sinks.sinks1.kafka.producer.acks = 1
agent1.sinks.sinks1.kafka.producer.linger.ms = 1
agent1.sinks.sinks1.kafka.producer.compression.type = snappy
# Use a channel which buffers events in memory
# agent1.channels.channels1.type = File, JDBC, Memory
agent1.channels.channels1.type = memory
agent1.channels.channels1.capacity = 1000
agent1.channels.channels1.transactionCapacity = 100
# Bind the source and sink to the channel
agent1.sources.sources1.channels = channels1
agent1.sinks.sinks1.channel = channels1
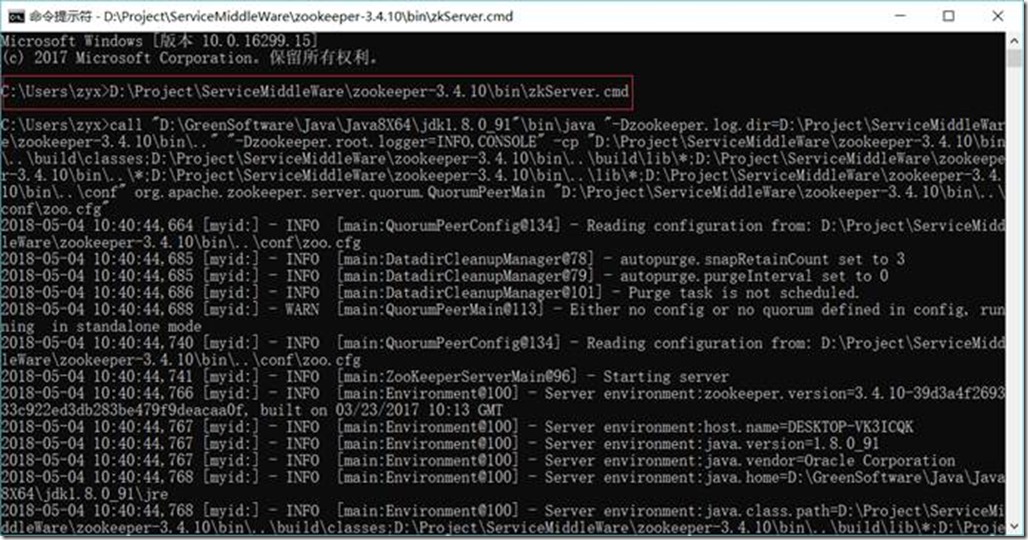
1.3.8.2. 启动Zookeeper
D:\Project\ServiceMiddleWare\zookeeper-3.4.10\bin\zkServer.cmd
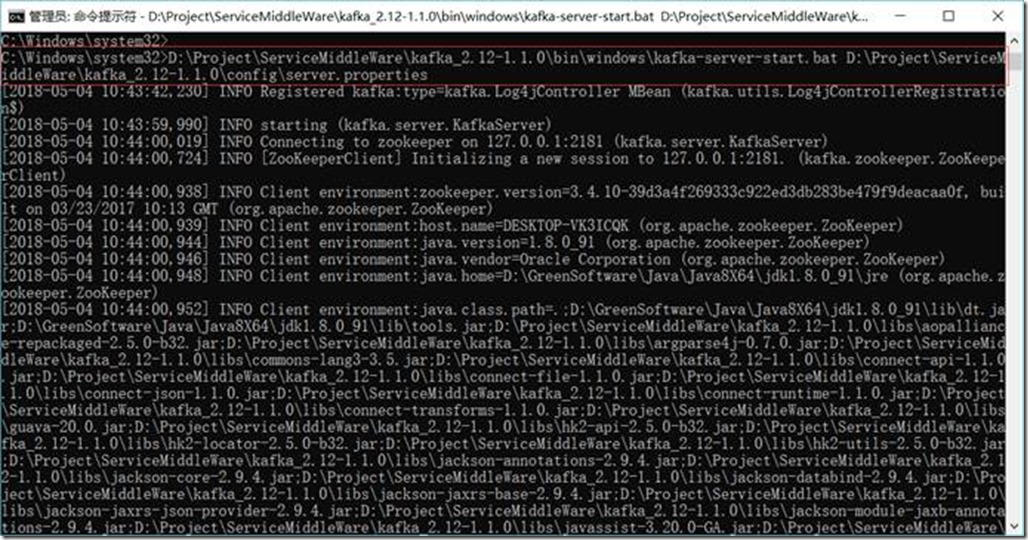
1.3.8.3. 启动Kafka
D:\Project\ServiceMiddleWare\kafka_2.12-1.1.0\bin\windows\kafka-server-start.bat D:\Project\ServiceMiddleWare\kafka_2.12-1.1.0\config\server.properties
1.3.8.4. 创建消费者(Consumer)
D:\Project\ServiceMiddleWare\kafka_2.12-1.1.0\bin\windows\kafka-console-consumer.bat --zookeeper 127.0.0.1:2181 --topic testTopic

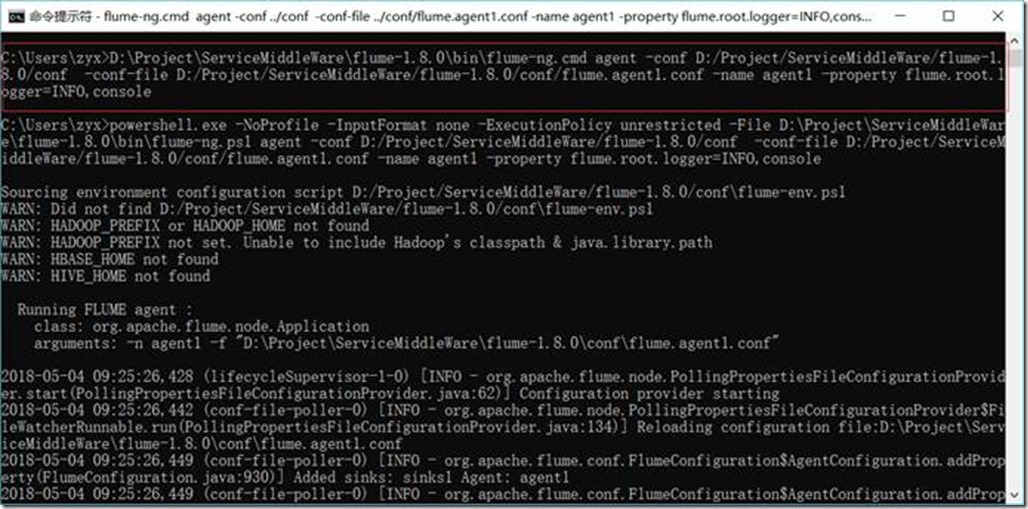
1.3.8.5. 启动Flume
D:\Project\ServiceMiddleWare\flume-1.8.0\bin\flume-ng.cmd agent -conf D:/Project/ServiceMiddleWare/flume-1.8.0/conf -conf-file D:/Project/ServiceMiddleWare/flume-1.8.0/conf/flume.agent1.conf -name agent1 -property flume.root.logger=INFO,console
1.3.8.6. 启动Flume的数据生产者(访问44444端口,模拟数据输入)
telnet 127.0.0.1 44444
然后输入任意内容
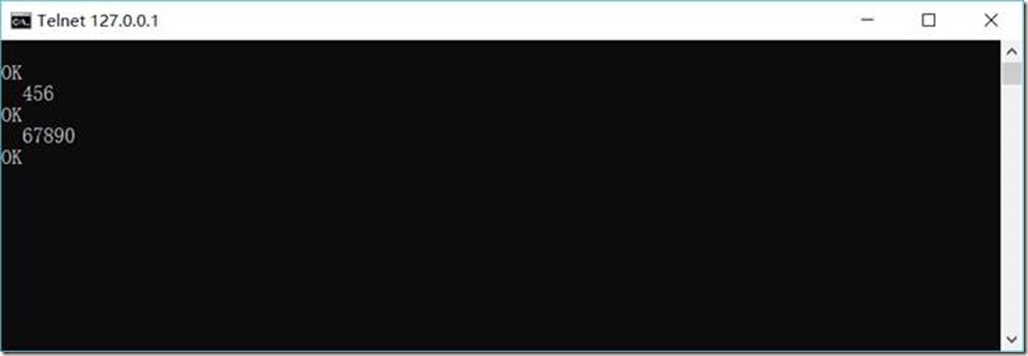
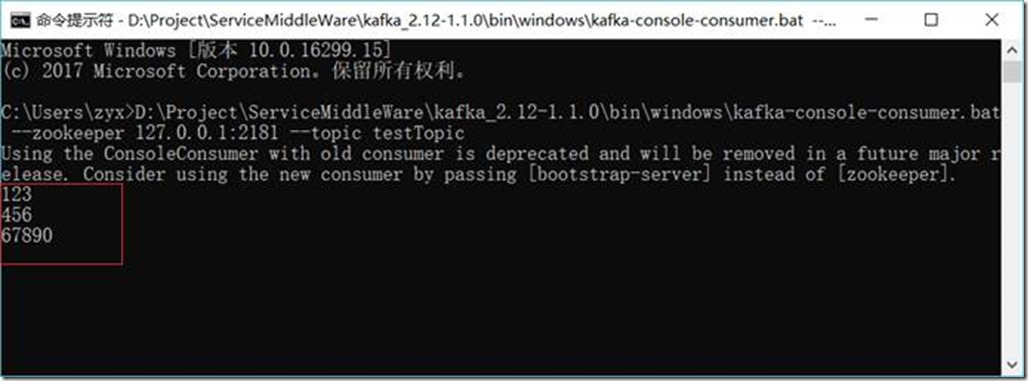
1.3.8.7. 查看kafka中消费者收到消息结果
Scala + Thrift+ Zookeeper+Flume+Kafka配置笔记的更多相关文章
- 最新 Zookeeper + Flume + Kafka 简易整合教程
在大数据领域有很多耳熟能详的框架,今天要介绍的就是 zookeeper.flume.kafka.因为平时是做数据接入的,所以对这些实时的数据处理系统不是很熟悉.通过官网的简要介绍,搭建了一套简要的平台 ...
- flume kafka 配置指南
1.官方网站也有配置: https://flume.apache.org/FlumeUserGuide.html#kafka-source 2.clodera 官方配置 https://www.clo ...
- Flume - Kafka日志平台整合
1. Flume介绍 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供 ...
- 【转】flume+kafka+zookeeper 日志收集平台的搭建
from:https://my.oschina.net/jastme/blog/600573 flume+kafka+zookeeper 日志收集平台的搭建 收藏 jastme 发表于 10个月前 阅 ...
- windows安装zookeeper和kafka,flume
一.安装JDK 过程比较简单,这里不做说明. 最后打开cmd输入如下内容,表示安装成功 二.安装zooeleeper 下载安装包:http://zookeeper.apache.org/release ...
- Apache ZooKeeper在Kafka中的角色 - 监控和配置
1.目标 今天,我们将看到Zookeeper在Kafka中的角色.本文包含Kafka中需要ZooKeeper的原因.我们可以说,ZooKeeper是Apache Kafka不可分割的一部分.在了解Zo ...
- HyperLedger Fabric基于zookeeper和kafka集群配置解析
简述 在搭建HyperLedger Fabric环境的过程中,我们会用到一个configtx.yaml文件(可参考Hyperledger Fabric 1.0 从零开始(八)--Fabric多节点集群 ...
- kafka集群与zookeeper集群 配置过程
Kafka的集群配置一般有三种方法,即 (1)Single node – single broker集群: (2)Single node – multiple broker集群: (3)Mult ...
- Ubuntu16.04配置单机版Zookeeper和Kafka
1. 配置zookeeper单机模式 选择的是zookeeper-3.4.10版本,官网下载链接:http://mirrors.hust.edu.cn/apache/zookeeper/stable/ ...
随机推荐
- 微信小程序一些总结
1.体验版和线上是啥区别,啥关系 在微信开发者工具里提交代码后进入体验版,在微信后台里点击版本管理,就可以看到线上版本,和开发体验版,描述里有提交备注. 在体验版里发布审核之后会进入到线上.他们两个可 ...
- Andrew Ng机器学习第五章——多变量线性回归
一.多变量线性回归的技巧之一——特征缩放 1.为什么要使用特征缩放? 特征缩放用来确保特征值在相似的范围之内. 设想这样一种情况(房价预测),两个特征值分别是房子的大小和卧室的数量.每个特征值所处的范 ...
- VSTO学习(六)——创建Outlook解决方案
本专题概要 引言 Outlook对象模型 自定义Outlook窗体 小结 一.引言 在上一个专题中,为大家简单介绍了下如何创建Word解决方案的,所以本专题中将为大家介绍下Outlook相关的内容.我 ...
- C++ 实现Biginteger
网上C++版Biginteger参差不齐,一下子没有找到一个令人满意Biginteger,最近用c++改写了一下C#版 BigInteger,可以用于RSA大素数的生成,分享给大家.也请大家批评指正改 ...
- EJB3 阶段总结+一个EJB3案例 (2)
这篇博文接着上一篇博文的EJB案例. 在上一篇博文中,将程序的架构基本给描述出来了,EJB模块分为5层. 1)DB层,即数据库层 在则一部分,我使用的数据库为mysql.在EJB程序中,访问数据库是通 ...
- TCP与UDP的差别以及TCP三次握手、四次挥手
UDP: 1.UDP面向报文,无需建立连接,不可靠,数量小,高层就解决差错重传,无需拥塞控制 2.支持音频.视频传输 3.检查和检验UDP包头和数据和伪首部 4.分组开销小(头部8个字节),提供最大努 ...
- 《Algorithms算法》笔记:优先队列(1)——API和初等实现
1.优先队列的API和初等实现 做一个总结: 栈 :先进后出 队列 :先进先出 随机队列 : 随机出 优先队列:每次出来的是最大值或最小值 1.1优先队列的API 优先队列在很多场合都有用, 比如:在 ...
- HUE配置文件hue.ini 的hdfs_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- 关于符号Symbol第一篇
Symbol类的一个实例代表一个符号.对于语法树来说,并不是每个节点都有一个符号实例.下面列举了哪些语法树节点具有符号的引用,如下表格: 其中JCNewClass.JCAssignOp.JCUnary ...
- 自然语言处理--Word2vec(一)
一.自然语言处理与深度学习 自然语言处理应用 深度学习模型 为什么需要用深度学习来处理呢 二.语言模型 1.语言模型实例: 机器翻译 拼写纠错 ...