深度学习基础系列(十一)| Keras中图像增强技术详解
在深度学习中,数据短缺是我们经常面临的一个问题,虽然现在有不少公开数据集,但跟大公司掌握的海量数据集相比,数量上仍然偏少,而某些特定领域的数据采集更是非常困难。根据之前的学习可知,数据量少带来的最直接影响就是过拟合。那有没有办法在现有少量数据基础上,降低或解决过拟合问题呢?
答案是有的,就是数据增强技术。我们可以对现有的数据,如图片数据进行平移、翻转、旋转、缩放、亮度增强等操作,以生成新的图片来参与训练或测试。这种操作可以将图片数量提升数倍,由此大大降低了过拟合的可能。本文将详解图像增强技术在Keras中的原理和应用。
一、Keras中的ImageDataGenerator类
图像增强的官网地址是:https://keras.io/preprocessing/image/ ,API使用相对简单,功能也很强大。
先介绍的是ImageDataGenerator类,这个类定义了图片该如何进行增强操作,其API及参数定义如下:
keras.preprocessing.image.ImageDataGenerator(
featurewise_center=False, #输入值按照均值为0进行处理
samplewise_center=False, #每个样本的均值按0处理
featurewise_std_normalization=False, #输入值按照标准正态化处理
samplewise_std_normalization=False, #每个样本按照标准正态化处理
zca_whitening=False, # 是否开启增白
zca_epsilon=1e-06,
rotation_range=0, #图像随机旋转一定角度,最大旋转角度为设定值
width_shift_range=0.0, #图像随机水平平移,最大平移值为设定值。若值为小于1的float值,则可认为是按比例平移,若大于1,则平移的是像素;若值为整型,平移的也是像素;假设像素为2.0,则移动范围为[-1,1]之间
height_shift_range=0.0, #图像随机垂直平移,同上
brightness_range=None, # 图像随机亮度增强,给定一个含两个float值的list,亮度值取自上下限值间
shear_range=0.0, # 图像随机修剪
zoom_range=0.0, # 图像随机变焦
channel_shift_range=0.0,
fill_mode='nearest', #填充模式,默认为最近原则,比如一张图片向右平移,那么最左侧部分会被临近的图案覆盖
cval=0.0,
horizontal_flip=False, #图像随机水平翻转
vertical_flip=False, #图像随机垂直翻转
rescale=None, #缩放尺寸
preprocessing_function=None,
data_format=None,
validation_split=0.0,
dtype=None)
下文将以mnist和花类的数据集进行图片操作,其中花类(17种花,共1360张图片)数据集可见我的百度网盘: https://pan.baidu.com/s/1YDA_VOBlJSQEijcCoGC60w 。让我们以直观地方式看看各参数能带来什么样的图片变化。
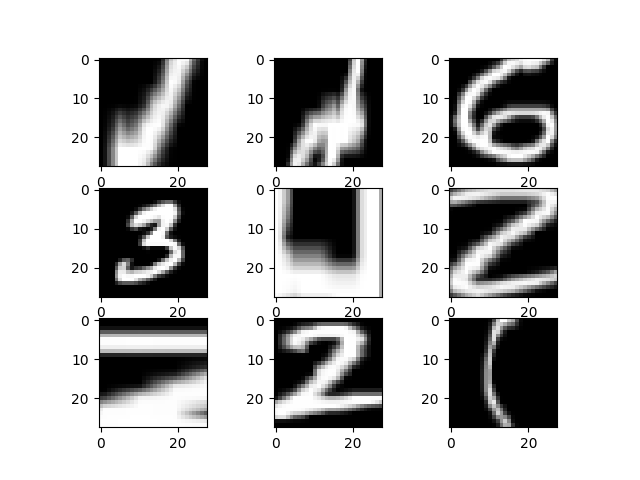
随机旋转
我们可用mnist数据集对图片进行随机旋转,旋转的最大角度由参数定义。
from keras.datasets import mnist
from keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot
from keras import backend as K K.set_image_dim_ordering('th') (train_data, train_label), (test_data, test_label) = mnist.load_data()
train_data = train_data.reshape(train_data.shape[0], 1, 28, 28)
train_data = train_data.astype('float32') # 创建图像生成器,指定对图像操作的内容
datagen = ImageDataGenerator(rotation_range=90)
# 图像生成器要训练的数据
datagen.fit(train_data) # 这是个图像生成迭代器,是可以无限生成各种新图片,我们指定每轮迭代只生成9张图片
for batch_data, batch_label in datagen.flow(train_data, train_label, batch_size=9):
for i in range(0, 9):
# 创建一个 3*3的九宫格,以显示图片
pyplot.subplot(330 + 1 + i)
pyplot.imshow(batch_data[i].reshape(28, 28), cmap=pyplot.get_cmap('gray'))
pyplot.show()
break
生成结果为:

随机平移
我们可用花类数据集对图片进行随机平移,可以在垂直和水平方向上平移,平移最大值由参数定义。
from keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot
from keras.preprocessing.image import array_to_img IMAGE_SIZE = 224
NUM_CLASSES = 17
TRAIN_PATH = '/home/yourname/Documents/tensorflow/images/17flowerclasses/train'
TEST_PATH = '/home/yourname/Documents/tensorflow/images/17flowerclasses/test'
FLOWER_CLASSES = ['Bluebell', 'ButterCup', 'ColtsFoot', 'Cowslip', 'Crocus', 'Daffodil', 'Daisy',
'Dandelion', 'Fritillary', 'Iris', 'LilyValley', 'Pansy', 'Snowdrop', 'Sunflower',
'Tigerlily', 'tulip', 'WindFlower'] # 创建图像生成器,指定对图像操作的内容,平移的最大比例为50%
train_datagen = ImageDataGenerator(width_shift_range=0.5, height_shift_range=0.5) # 这是个图像生成迭代器,是可以无限生成各种新图片,我们指定每轮迭代只生成9张图片
for X_batch, y_batch in train_datagen.flow_from_directory(directory=TRAIN_PATH, target_size=(IMAGE_SIZE, IMAGE_SIZE),batch_size=9, classes=FLOWER_CLASSES):
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(array_to_img(X_batch[i]))
pyplot.show()
break
生成结果为:

可以观察到,图片除了实现平移外,其原来的位置都被最近的图案给填充,因为默认给的填充方式是nearest。
随机亮度调整
我们可用花类数据集对图片进行随机亮度调整,亮度范围由参数定义。
from keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot
from keras.preprocessing.image import array_to_img IMAGE_SIZE = 224
NUM_CLASSES = 17
TRAIN_PATH = '/home/yourname/Documents/tensorflow/images/17flowerclasses/train'
TEST_PATH = '/home/yourname/Documents/tensorflow/images/17flowerclasses/test'
FLOWER_CLASSES = ['Bluebell', 'ButterCup', 'ColtsFoot', 'Cowslip', 'Crocus', 'Daffodil', 'Daisy',
'Dandelion', 'Fritillary', 'Iris', 'LilyValley', 'Pansy', 'Snowdrop', 'Sunflower',
'Tigerlily', 'tulip', 'WindFlower'] # 创建图像生成器,指定对图像操作的内容,亮度范围在0.1~10之间随机选择
train_datagen = ImageDataGenerator(brightness_range=[0.1, 10]) # 这是个图像生成迭代器,是可以无限生成各种新图片,我们指定每轮迭代只生成9张图片
for X_batch, y_batch in train_datagen.flow_from_directory(directory=TRAIN_PATH, target_size=(IMAGE_SIZE, IMAGE_SIZE),batch_size=9, classes=FLOWER_CLASSES):
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(array_to_img(X_batch[i]))
pyplot.show()
break
生成结果为:
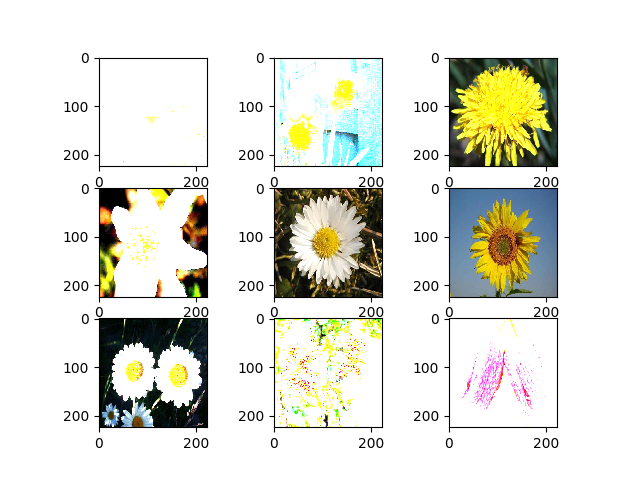
随机焦距调整
我们可用mnist数据集对图片进行随机焦距调整,焦距调整值由参数定义。
from keras.datasets import mnist
from keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot
from keras import backend as K K.set_image_dim_ordering('th') (train_data, train_label), (test_data, test_label) = mnist.load_data()
train_data = train_data.reshape(train_data.shape[0], 1, 28, 28)
train_data = train_data.astype('float32') # 创建图像生成器,指定对图像操作的内容,焦距值在0.1~1之间
datagen = ImageDataGenerator(zoom_range=[0.1, 1])
# 图像生成器要训练的数据
datagen.fit(train_data) # 这是个图像生成迭代器,是可以无限生成各种新图片,我们指定每轮迭代只生成9张图片
for batch_data, batch_label in datagen.flow(train_data, train_label, batch_size=9):
for i in range(0, 9):
# 创建一个 3*3的九宫格,以显示图片
pyplot.subplot(330 + 1 + i)
pyplot.imshow(batch_data[i].reshape(28, 28), cmap=pyplot.get_cmap('gray'))
pyplot.show()
break
生成结果为:
可以看出这跟相机调焦一样,可以放大或缩小焦距。
随机翻转
我们可用花类数据集对图片进行随机翻转。
from keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot
from keras.preprocessing.image import array_to_img IMAGE_SIZE = 224
NUM_CLASSES = 17
TRAIN_PATH = '/home/hutao/Documents/tensorflow/images/17flowerclasses/train'
TEST_PATH = '/home/hutao/Documents/tensorflow/images/17flowerclasses/test'
FLOWER_CLASSES = ['Bluebell', 'ButterCup', 'ColtsFoot', 'Cowslip', 'Crocus', 'Daffodil', 'Daisy',
'Dandelion', 'Fritillary', 'Iris', 'LilyValley', 'Pansy', 'Snowdrop', 'Sunflower',
'Tigerlily', 'tulip', 'WindFlower'] # 创建图像生成器,指定对图像操作的内容,图片随机翻转
train_datagen = ImageDataGenerator(horizontal_flip=True, vertical_flip=True) # 这是个图像生成迭代器,是可以无限生成各种新图片,我们指定每轮迭代只生成9张图片
for X_batch, y_batch in train_datagen.flow_from_directory(directory=TRAIN_PATH, target_size=(IMAGE_SIZE, IMAGE_SIZE),batch_size=9, classes=FLOWER_CLASSES):
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(array_to_img(X_batch[i]))
pyplot.show()
break
生成结果为:

从上图可看出,有些图片水平翻转了,有些是垂直翻转了。
ZCA图像增白
说实在我不太清楚该技术有何用,用花类图片实验结果显示zca不支持,可以用mnist数据集来看看效果。
from keras.datasets import mnist
from keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot
from keras import backend as K K.set_image_dim_ordering('th') (train_data, train_label), (test_data, test_label) = mnist.load_data()
train_data = train_data.reshape(train_data.shape[0], 1, 28, 28)
train_data = train_data.astype('float32') # 创建图像生成器,指定对图像操作的内容,增白图片
datagen = ImageDataGenerator(zca_whitening=True)
# 图像生成器要训练的数据
datagen.fit(train_data) # 这是个图像生成迭代器,是可以无限生成各种新图片,我们指定每轮迭代只生成9张图片
for batch_data, batch_label in datagen.flow(train_data, train_label, batch_size=9):
for i in range(0, 9):
# 创建一个 3*3的九宫格,以显示图片
pyplot.subplot(330 + 1 + i)
pyplot.imshow(batch_data[i].reshape(28, 28), cmap=pyplot.get_cmap('gray'))
pyplot.show()
break
生成结果为:
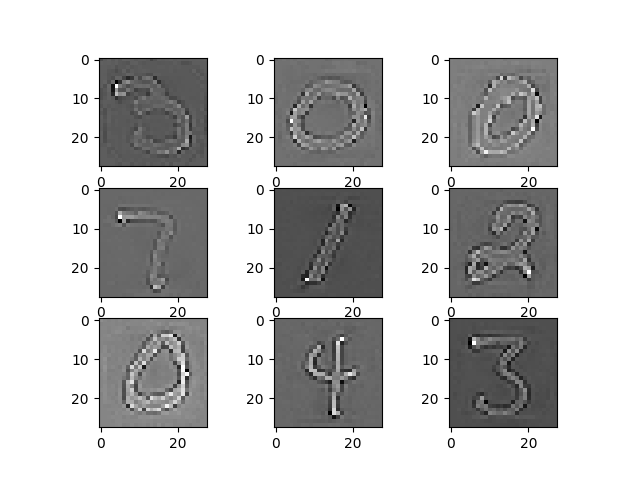
特征标准化
特征标准化的含义是使图片的像素均值为0,标准差为1,不过我试了多次,直观效果不明显。
from keras.datasets import mnist
from keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot
from keras import backend as K K.set_image_dim_ordering('th') (train_data, train_label), (test_data, test_label) = mnist.load_data()
train_data = train_data.reshape(train_data.shape[0], 1, 28, 28)
train_data = train_data.astype('float32') # 创建图像生成器,指定对图像操作的内容,允许图片标准化处理
datagen = ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True)
# 图像生成器要训练的数据
datagen.fit(train_data) # 这是个图像生成迭代器,是可以无限生成各种新图片,我们指定每轮迭代只生成9张图片
for batch_data, batch_label in datagen.flow(train_data, train_label, batch_size=9):
for i in range(0, 9):
# 创建一个 3*3的九宫格,以显示图片
pyplot.subplot(330 + 1 + i)
pyplot.imshow(batch_data[i].reshape(28, 28), cmap=pyplot.get_cmap('gray'))
pyplot.show()
break
生成结果为:

就个人而言,我倾向于在图像增强中使用旋转、亮度调整、翻转和平移操作。
二、Keras如何进行图像增强数据训练
在之前的文章中我已经展现过数据增强的使用。在Keras中,增强图片有三种来源:
- 图片来源于已知数据集,如mnist、cifar,数据格式为numpy格式;
- 图片来源于我们自己搜集的图片,如本文引入的花类数据集,其图片为jpg、png等格式;
- 图片来源于panda数据集;
其中数据来源已知数据集,其操作方法如下:
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes) datagen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True) #生成器绑定训练集
datagen.fit(x_train) # 模型绑定生成器,并不停地迭代产生数据,可指定迭代次数,假设图片总数为1000张,batch默认为32,则每次迭代需要产生1000/32=32个步骤
history = model.fit_generator(datagen.flow(x_train, y_train, batch_size=32),
steps_per_epoch=len(x_train) / 32, epochs=epochs)
数据来源图片集,其操作方法如下:
batch_size = 32
# 迭代50次
epochs = 50
# 依照模型规定,图片大小被设定为224
IMAGE_SIZE = 224
TRAIN_PATH = '/home/yourname/Documents/tensorflow/images/17flowerclasses/train'
TEST_PATH = '/home/yourname/Documents/tensorflow/images/17flowerclasses/test'
FLOWER_CLASSES = ['Bluebell', 'ButterCup', 'ColtsFoot', 'Cowslip', 'Crocus', 'Daffodil', 'Daisy','Dandelion', 'Fritillary', 'Iris', 'LilyValley', 'Pansy', 'Snowdrop', 'Sunflower','Tigerlily', 'tulip', 'WindFlower'] # 使用数据增强
train_datagen = ImageDataGenerator(rotation_range=90)
# 可指定输出图片大小,因为深度学习要求训练图片大小保持一致
train_generator = train_datagen.flow_from_directory(directory=TRAIN_PATH,
target_size=(IMAGE_SIZE, IMAGE_SIZE),
classes=FLOWER_CLASSES)
test_datagen = ImageDataGenerator()
test_generator = test_datagen.flow_from_directory(directory=TEST_PATH,
target_size=(IMAGE_SIZE, IMAGE_SIZE),
classes=FLOWER_CLASSES)
# 运行模型
history = model.fit_generator(train_generator, epochs=epochs, validation_data=test_generator)
需要说明的是,这些增强图片都是在内存中实时批量迭代生成的,不是一次性被读入内存,这样可以极大地节约内存空间,加快处理速度。若想保留中间过程生成的增强图片,可以在上述方法中添加保存路径等参数,此处不再赘述。
三、结论
本文介绍了如何在Keras中使用图像增强技术,对图片可以进行各种操作,以生成数倍于原图片的增强图片集。这些数据集可帮助我们有效地对抗过拟合问题,更好地生成理想的模型。
深度学习基础系列(十一)| Keras中图像增强技术详解的更多相关文章
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 转:LoadRunner中参数化技术详解
LoadRunner中参数化技术详解 LoadRunner在录制脚本的时候,只是忠实的记录了所有从客户端发送到服务器的数据,而在进行性能测试的时候,为了更接近真实的模拟现实应用,对于某些信息需要每次提 ...
- Tensorflow2(一)深度学习基础和tf.keras
代码和其他资料在 github 一.tf.keras概述 首先利用tf.keras实现一个简单的线性回归,如 \(f(x) = ax + b\),其中 \(x\) 代表学历,\(f(x)\) 代表收入 ...
- 深度学习基础系列(七)| Batch Normalization
Batch Normalization(批量标准化,简称BN)是近些年来深度学习优化中一个重要的手段.BN能带来如下优点: 加速训练过程: 可以使用较大的学习率: 允许在深层网络中使用sigmoid这 ...
- 深度学习基础系列(四)| 理解softmax函数
深度学习最终目的表现为解决分类或回归问题.在现实应用中,输出层我们大多采用softmax或sigmoid函数来输出分类概率值,其中二元分类可以应用sigmoid函数. 而在多元分类的问题中,我们默认采 ...
- 深度学习基础系列(十)| Global Average Pooling是否可以替代全连接层?
Global Average Pooling(简称GAP,全局池化层)技术最早提出是在这篇论文(第3.2节)中,被认为是可以替代全连接层的一种新技术.在keras发布的经典模型中,可以看到不少模型甚至 ...
- 深度学习基础系列(一)| 一文看懂用kersa构建模型的各层含义(掌握输出尺寸和可训练参数数量的计算方法)
我们在学习成熟网络模型时,如VGG.Inception.Resnet等,往往面临的第一个问题便是这些模型的各层参数是如何设置的呢?另外,我们如果要设计自己的网路模型时,又该如何设置各层参数呢?如果模型 ...
- 深度学习(PYTORCH)-3.sphereface-pytorch.lfw_eval.py详解
pytorch版本sphereface的原作者地址:https://github.com/clcarwin/sphereface_pytorch 由于接触深度学习不久,所以花了较长时间来阅读源码,以下 ...
随机推荐
- mysql zip 解压安装
系统:win10 专业版 mysql 5.7.21 解压安装. 对于Windows,mysql官网推荐使用可执行文件进行安装,这里我还是暂时用noinstall 解压zip文件来安装 zip 文件解压 ...
- Linux基础操作命令-打包压缩
将用户信息数据库文件和组信息数据库文件纵向合并为一个文件/1.txt(覆盖) 将用户信息数据库文件和用户密码数据库文件纵向合并为一个文件/2.txt(追加) 将/1.txt./2.txt两个文件打包为 ...
- 使用TS+Sequelize实现更简洁的CRUD
如果是经常使用Node来做服务端开发的童鞋,肯定不可避免的会操作数据库,做一些增删改查(CRUD,Create Read Update Delete)的操作,如果是一些简单的操作,类似定时脚本什么的, ...
- mogodb的安装与配置
下载:https://www.mongodb.com/https://www.mongodb.com/ 安装:一直next,中间选择custom,选择自己的安装路径,最后安装成功. 配置:打开安装好的 ...
- 一个罕见的MSSQL注入漏洞案例
一个罕见的MSSQL注入漏洞案例 这里作者准备分享一个在去年Google赏金计划中发现的相当罕见漏洞,也是作者在整个渗透测试生涯中唯一一次遇到的. 目标网站使用了微软 SQL Server 数据库并且 ...
- Spring4笔记9--Spring的事务管理(AOP应用的例子)
Spring的事务管理: 事务原本是数据库中的概念,在 Dao 层.但一般情况下,需要将事务提升到业务层,即 Service 层.这样做是为了能够使用事务的特性来管理具体的业务. 在 Spring ...
- SDL封装的系统操作(转载)
Andrew Haung bluedrum@163.com SDL封装很多操作系统的功能,为了保证SDL程序可移植性,最好尽量用这一些封装函数,哪果没有的话,才使用各种操作本地函数. 对于如何封各个 ...
- MySQL 高可用:mysql+Lvs+Keepalived 负载均衡及故障转移
系统信息: mysql主库 mysql从库 VIP 192.168.1.150 mysql 主主同步都设置 auto-increment-offset,auto-increment-increment ...
- Flask:abort()函数
Windows 10家庭中文版,Python 3.6.4,Flask 1.0.2 abort()函数用于提前退出(Google翻译abort)一个请求,并用指定的错误码返回. 函数原型如下: flas ...
- 在JAVA中记录日志的十个小建议
JAVA日志管理既是一门科学,又是一门艺术.科学的部分是指了解写日志的工具以及其API,而选择日志的格式,消息的格式,日志记录的内容,哪种消息对应于哪一种日志级别,则完全是基于经验.从过去的实践证明, ...