python selenium wait方法
遇到一个网站运行很慢,所以要等待某个元素显示出来之后再进行操作,自己手上的书上没有例子可以直接用
发现一篇文章:http://www.cnblogs.com/yoyoketang/p/6517477.html 原文如下
前言:
在脚本中加入太多的sleep后会影响脚本的执行速度,虽然implicitly_wait()这种方法隐式等待方法一定程度上节省了很多时间。
但是一旦页面上某些js无法加载出来(其实界面元素经出来了),左上角那个图标一直转圈,这时候会一直等待的。
一、参数解释
1.这里主要有三个参数:
class WebDriverWait(object):driver, timeout, poll_frequency
2.driver:返回浏览器的一个实例,这个不用多说
3.timeout:超时的总时长
4.poll_frequency:循环去查询的间隙时间,默认0.5秒
以下是源码的解释文档(案例一个是元素出现,一个是元素消失)
def __init__(self, driver, timeout, poll_frequency=POLL_FREQUENCY, ignored_exceptions=None):
"""Constructor, takes a WebDriver instance and timeout in seconds.
:Args:
- driver - Instance of WebDriver (Ie, Firefox, Chrome or Remote)
- timeout - Number of seconds before timing out
- poll_frequency - sleep interval between calls
By default, it is 0.5 second.
- ignored_exceptions - iterable structure of exception classes ignored during calls.
By default, it contains NoSuchElementException only.
Example:
from selenium.webdriver.support.ui import WebDriverWait \n
element = WebDriverWait(driver, 10).until(lambda x: x.find_element_by_id("someId")) \n
is_disappeared = WebDriverWait(driver, 30, 1, (ElementNotVisibleException)).\ \n
until_not(lambda x: x.find_element_by_id("someId").is_displayed())
"""
二、元素出现:until()
1.until里面有个lambda函数,这个语法看python文档吧
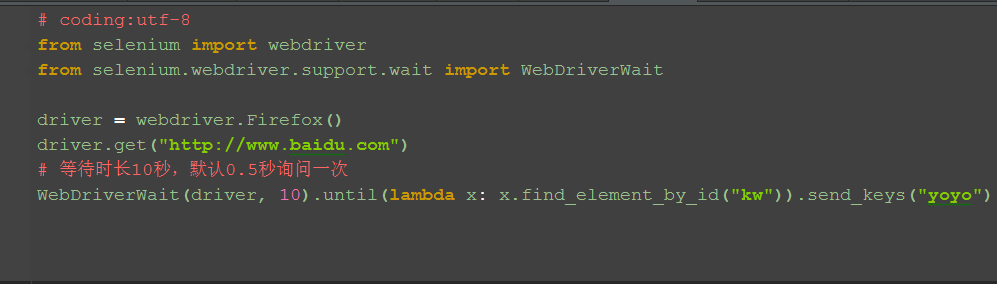
2.以百度输入框为例
三、元素消失:until_not()
1.判断元素是否消失,是返回Ture,否返回False
备注:此方法未调好,暂时放这
四、参考代码:
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
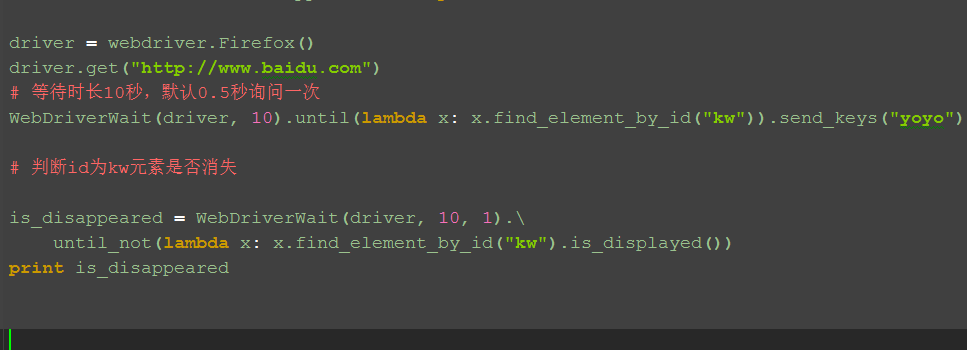
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
# 等待时长10秒,默认0.5秒询问一次
WebDriverWait(driver, 10).until(lambda x: x.find_element_by_id("kw")).send_keys("yoyo")
# 判断id为kw元素是否消失
is_disappeared = WebDriverWait(driver, 10, 1).\
until_not(lambda x: x.find_element_by_id("kw").is_displayed())
print is_disappeared
五、WebDriverWait源码
1.WebDriverWait主要提供了两个方法,一个是until(),另外一个是until_not()
以下是源码的注释,有兴趣的小伙伴可以看下
# Licensed to the Software Freedom Conservancy (SFC) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The SFC licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
import time
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import TimeoutException
POLL_FREQUENCY = 0.5 # How long to sleep inbetween calls to the method
IGNORED_EXCEPTIONS = (NoSuchElementException,) # exceptions ignored during calls to the method
class WebDriverWait(object):
def __init__(self, driver, timeout, poll_frequency=POLL_FREQUENCY, ignored_exceptions=None):
"""Constructor, takes a WebDriver instance and timeout in seconds.
:Args:
- driver - Instance of WebDriver (Ie, Firefox, Chrome or Remote)
- timeout - Number of seconds before timing out
- poll_frequency - sleep interval between calls
By default, it is 0.5 second.
- ignored_exceptions - iterable structure of exception classes ignored during calls.
By default, it contains NoSuchElementException only.
Example:
from selenium.webdriver.support.ui import WebDriverWait \n
element = WebDriverWait(driver, 10).until(lambda x: x.find_element_by_id("someId")) \n
is_disappeared = WebDriverWait(driver, 30, 1, (ElementNotVisibleException)).\ \n
until_not(lambda x: x.find_element_by_id("someId").is_displayed())
"""
self._driver = driver
self._timeout = timeout
self._poll = poll_frequency
# avoid the divide by zero
if self._poll == 0:
self._poll = POLL_FREQUENCY
exceptions = list(IGNORED_EXCEPTIONS)
if ignored_exceptions is not None:
try:
exceptions.extend(iter(ignored_exceptions))
except TypeError: # ignored_exceptions is not iterable
exceptions.append(ignored_exceptions)
self._ignored_exceptions = tuple(exceptions)
def __repr__(self):
return '<{0.__module__}.{0.__name__} (session="{1}")>'.format(
type(self), self._driver.session_id)
def until(self, method, message=''):
"""Calls the method provided with the driver as an argument until the \
return value is not False."""
screen = None
stacktrace = None
end_time = time.time() + self._timeout
while True:
try:
value = method(self._driver)
if value:
return value
except self._ignored_exceptions as exc:
screen = getattr(exc, 'screen', None)
stacktrace = getattr(exc, 'stacktrace', None)
time.sleep(self._poll)
if time.time() > end_time:
break
raise TimeoutException(message, screen, stacktrace)
def until_not(self, method, message=''):
"""Calls the method provided with the driver as an argument until the \
return value is False."""
end_time = time.time() + self._timeout
while True:
try:
value = method(self._driver)
if not value:
return value
except self._ignored_exceptions:
return True
time.sleep(self._poll)
if time.time() > end_time:
break
raise TimeoutException(message)
python selenium wait方法的更多相关文章
- python+selenium安装方法
一.准备工具: 下载 python[python 开发环境] http://python.org/getit/ 下载 setuptools [python 的基础包工具] http://pypi.py ...
- python selenium webdriver方法封装(find_element_by)
下面是对find_element_by_就行了封装,封装之后的高级方法就是getElement() 下面是具体的代码: def getElement(self, selector): "&q ...
- Python+selenium自动化测试中Windows窗口跳转方法
Python+selenium自动化测试中Windows窗口跳转方法 #第一种方法 #获得当前窗口 nowhandle=driver.current_window_handle #打开弹窗 drive ...
- Python+Selenium定位元素的方法
Python+Selenium有以下八种定位元素的方法: 1. find_element_by_id() eg: find_element_by_id("kw") 2. find_ ...
- Python+Selenium自动化-定位一组元素,单选框、复选框的选中方法
Python+Selenium自动化-定位一组元素,单选框.复选框的选中方法 之前学习了8种定位单个元素的方法,同时webdriver还提供了8种定位一组元素的方法.唯一区别就是在单词elemen ...
- Python+Selenium自动化-设置等待三种等待方法
Python+Selenium自动化-设置等待三种等待方法 如果遇到使用ajax加载的网页,页面元素可能不是同时加载出来的,这个时候,就需要我们通过设置一个等待条件,等待页面元素加载完成,避免出现 ...
- Python+Selenium自动化-定位页面元素的八种方法
Python+Selenium自动化-定位页面元素的八种方法 本篇文字主要学习selenium定位页面元素的集中方法,以百度首页为例子. 0.元素定位方法主要有: id定位:find_elemen ...
- 一次完整的自动化登录测试-基于python+selenium进行cnblog的自动化登录测试
Web登录测试是很常见的测试!手动测试大家再熟悉不过了,那如何进行自动化登录测试呢!本文作者就用python+selenium结合unittest单元测试框架来进行一次简单但比较完整的cnblog自动 ...
- python selenium自动化(二)自动化注册流程
需求:使用python selenium来自动测试一个网站注册的流程. 假设这个网站的注册流程分为三步,需要提供比较多的信息: 在这个流程里面,需要用户填入信息.在下拉菜单中选择.选择单选的radio ...
随机推荐
- 用Micro:bit控制遥控车
很多遥控车是用Arduino来控制,同样也可以用Micro:bit来控制.这篇文章我们就来做个测试. 这次需要用到扩展板,管脚比较多,请参考下图 一.材料: •micro:bit 二片 •micro: ...
- centos安装及Xshell连接配置
一.百度下载并安装VMware 二.下载centos 打开https://www.centos.org,点击“get centos now”,点击“DVD ISO”下载(也可以下滑点击“more do ...
- Laya1.x Timer小记
Timer是时钟管理类,在Laya初始化的时候会创建一个实例,通过Laya.timer访问. TimerHandler TimerHandler是对每一个定时任务的封装,每次调用frameOnce.f ...
- python装饰器(披着羊皮的狼)
python装饰器的作用是在不改变原有函数的基础上,对函数的功能进行增加或者修改. 装饰器语法是python语言更加优美且避免很多繁琐的事情,flask中配置路由的方式便是装饰器. 首先python中 ...
- ngxin 添加模块
if test -n "$NGX_ADDONS"; then echo configuring additional modules for ngx_addon_dir in $N ...
- Go入门指南
第一部分:学习 Go 语言 第1章:Go 语言的起源,发展与普及 1.1 起源与发展 1.2 语言的主要特性与发展的环境和影响因素 第2章:安装与运行环境 2.1 平台与架构 2.2 Go 环境变量 ...
- django orm 操作表
django orm 操作表 1.基本操作 增 models.Tb1.objects.create(c1='xx', c2='oo') 增加一条数据,可以接受字典类型数据 **kwargs inser ...
- js循环复制一个div
<html> <head> <title>Test of cloneNode Method</title> <script type=" ...
- Daily Srum 10.21
到目前为止,我们组处在学习阶段,很多知识点都还不太清楚,所以现在我们还在看相关书籍和博客,任务. 而我们此间主要是在阅读一些材料: 陈谋一直在看学长的代码,其中C#的很多方式我都不太明白(尽管和Jav ...
- iOS 开发学习-类的创建与实现,与java语言的对比
Person.h #import <Foundation/Foundation.h> @interface Person : NSObject { //在{}中定义属性(全局变量/实例变量 ...