SparkSql自定义数据源之读取的实现
一.sparksql读取数据源的过程
1.spark目前支持读取jdbc,hive,text,orc等类型的数据,如果要想支持hbase或者其他数据源,就必须自定义

2.读取过程
(1)sparksql进行 session.read.text()或者 session.read .format("text") .options(Map("a"->"b")).load("")

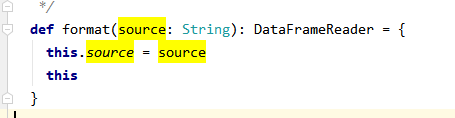

read.方法:创建DataFrameReader对象
format方法:赋值DataFrameReade数据源类型
options方法:赋值DataFrameReade额外的配置选项

进入 session.read.text()方法内,可以看到format为“text”
(2)进入load方法
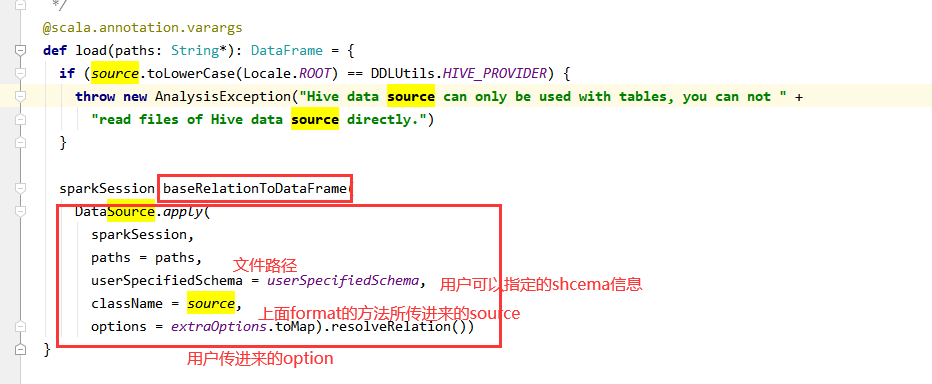
load原来是:sparkSession.baseRelationToDataFrame这个方法最终创建dataframe
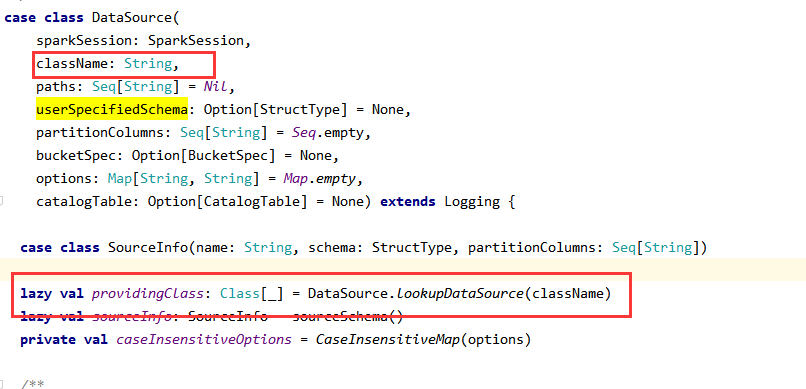
(3)进入DataSource的resolveRelation()方法
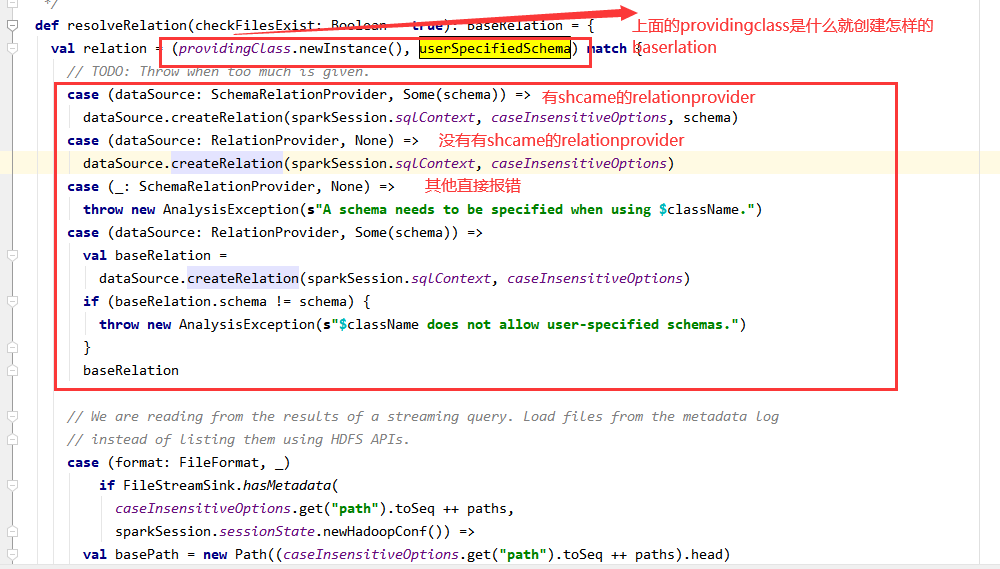
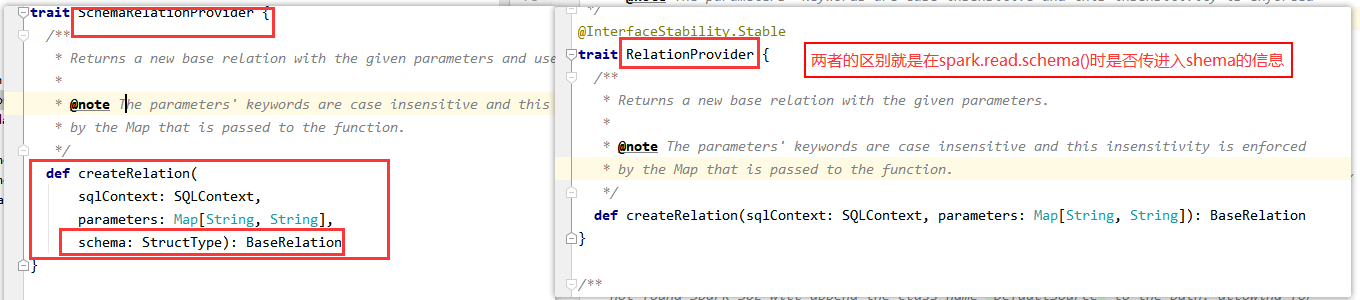
此段就是:providingClass这个类是哪一个接口的实现类,分为有shema与没有传入schema的两种
(3)providingClass是format传入的数据源类型,也就是前面的source
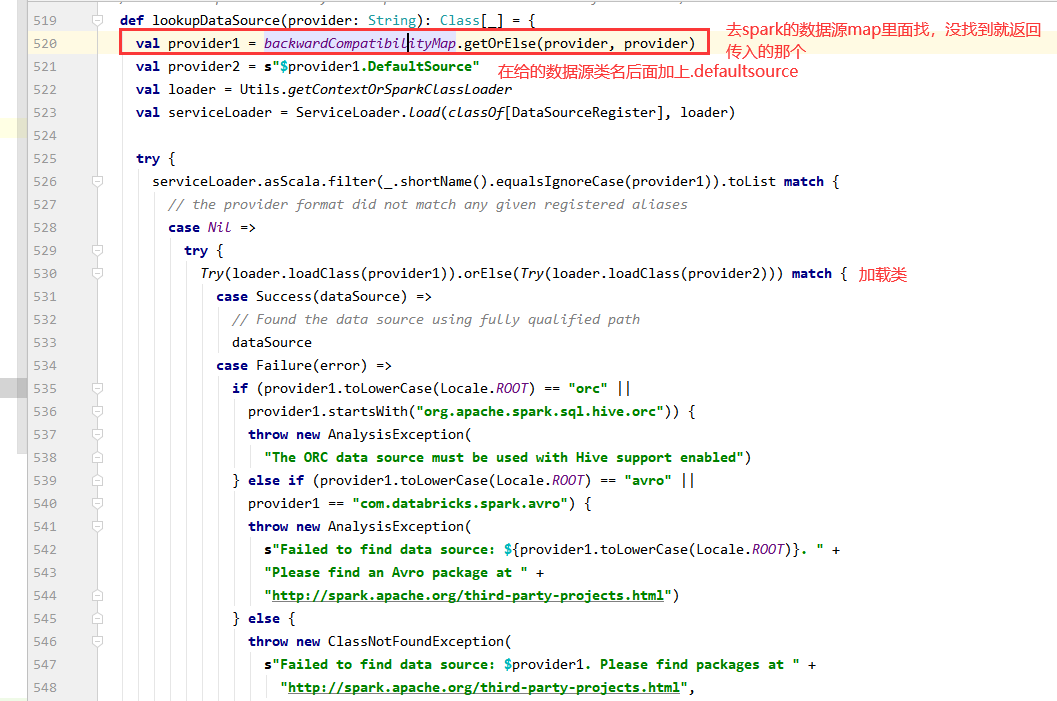
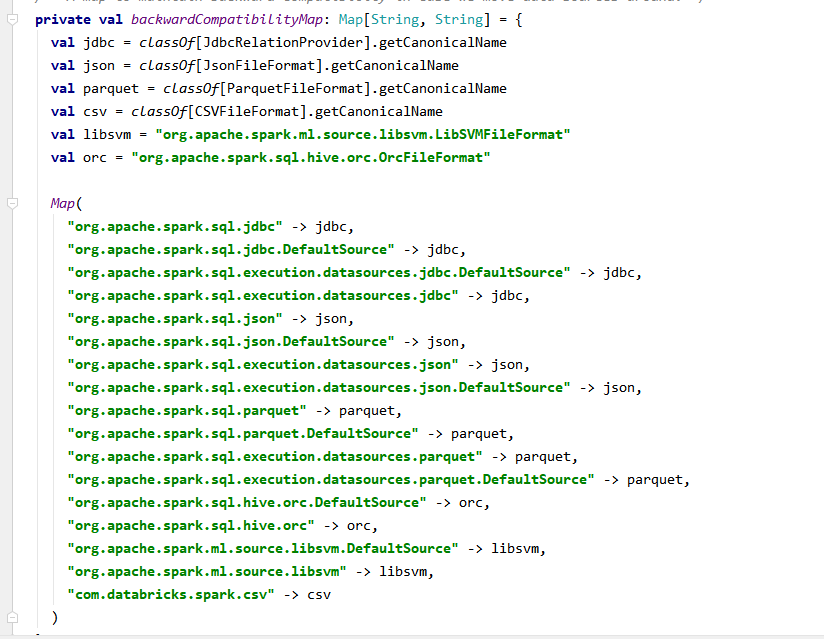
spark提供的所有数据源的map
4.得出结论只要写一个类,实现RelationProvider下面这个方法,在方法里面返回一个baserelation
def createRelation(sqlContext: SQLContext, parameters: Map[String, String]): BaseRelation
我们在实现baserelation里面的逻辑就可以了

5.看看spark读取jdbc类
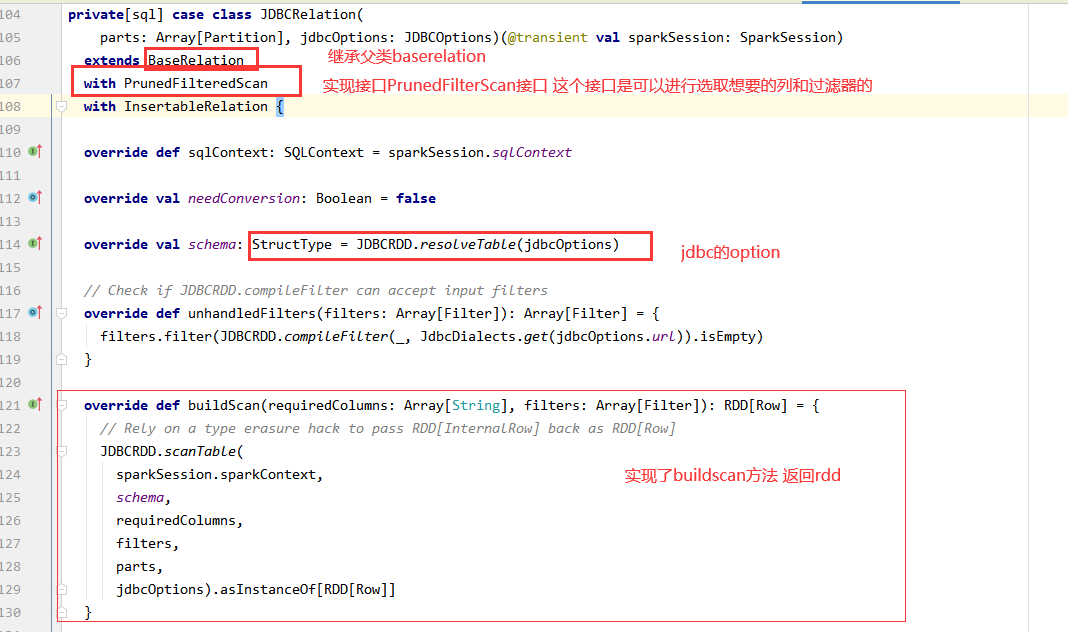
需要一个类,实现xxxScan这中类,这种类有三种,全局扫描tableScan,PrunedFilteredScan(列裁剪与谓词下推),PrunedScan ,
实现buildscan方法返回row类型rdd,结合baserelation有shcame这个变量 ,就凑成了dataframe
6.jdbcRdd.scanTable方法,得到RDD
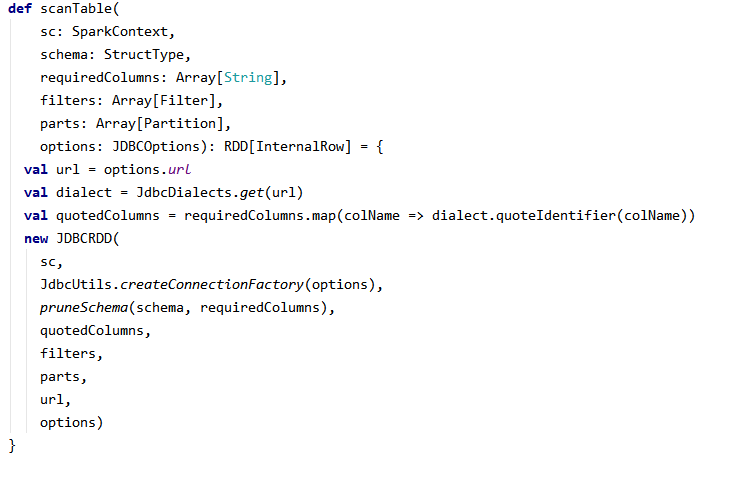
7.查看jdbcRDD的compute方法,是通过jdbc查询sql的方式获取数据
RDD的计算是惰性的,一系列转换操作只有在遇到动作操作是才会去计算数据,而分区作为数据计算的基本单位。在计算链中,无论一个RDD有多么复杂,其最终都会调用内部的compute函数来计算一个分区的数据。
override def compute(thePart: Partition, context: TaskContext): Iterator[InternalRow] = {
var closed = false
var rs: ResultSet = null
var stmt: PreparedStatement = null
var conn: Connection = null
def close() {
if (closed) return
try {
if (null != rs) {
rs.close()
}
} catch {
case e: Exception => logWarning("Exception closing resultset", e)
}
try {
if (null != stmt) {
stmt.close()
}
} catch {
case e: Exception => logWarning("Exception closing statement", e)
}
try {
if (null != conn) {
if (!conn.isClosed && !conn.getAutoCommit) {
try {
conn.commit()
} catch {
case NonFatal(e) => logWarning("Exception committing transaction", e)
}
}
conn.close()
}
logInfo("closed connection")
} catch {
case e: Exception => logWarning("Exception closing connection", e)
}
closed = true
}
context.addTaskCompletionListener{ context => close() }
val inputMetrics = context.taskMetrics().inputMetrics
val part = thePart.asInstanceOf[JDBCPartition]
conn = getConnection()
val dialect = JdbcDialects.get(url)
import scala.collection.JavaConverters._
dialect.beforeFetch(conn, options.asProperties.asScala.toMap)
// H2's JDBC driver does not support the setSchema() method. We pass a
// fully-qualified table name in the SELECT statement. I don't know how to
// talk about a table in a completely portable way.
//坐上每个分区的Filter条件
val myWhereClause = getWhereClause(part)
//最終查询sql语句
val sqlText = s"SELECT $columnList FROM ${options.table} $myWhereClause"
//jdbc查询
stmt = conn.prepareStatement(sqlText,
ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY)
stmt.setFetchSize(options.fetchSize)
rs = stmt.executeQuery()
val rowsIterator = JdbcUtils.resultSetToSparkInternalRows(rs, schema, inputMetrics)
//返回迭代器
CompletionIterator[InternalRow, Iterator[InternalRow]](
new InterruptibleIterator(context, rowsIterator), close())
}
SparkSql自定义数据源之读取的实现的更多相关文章
- JDBC 学习笔记(三)—— 数据源(数据库连接池):DBCP数据源、C3P0 数据源以及自定义数据源技术
本文目录: 1.应用程序直接获取连接的缺点(图解) 2.使用数据库连接池优化程序性能(图解) 3.可扩展增强某个类方法的功能的三种方式 4.自定 ...
- Pro自定义数据源原理
1. 概念 Connector:定义连接到一个数据源的连接信息,用于创建datastore. Datastore:代表一个数据源的实例,用于打开一个或多个tables或feature class. ...
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- FastReport自定义数据源及ListView控件的使用
##1.想批量生成一堆物资信息卡,效果如下图所示,fastreport可以一下全部生成,并且发现不用单独写东西, ##2.发现FastReport官方给出的Demo.exe很友好,基本可以满足要求,想 ...
- C#读取Excel文件:通过OleDb连接,把excel文件作为数据源来读取
转载于:http://developer.51cto.com/art/200908/142392.htm C#读取Excel文件可以通过直接读取和OleDb连接,把excel文件作为数据源来读取: ...
- Aspose.Word邮件合并之自定义数据源
Aspose.Word在进行邮件合并时,默认的几个重载方法对Database支持比较友好,但是也可以通过自定义数据源来实现从集合或者对象中返回数据进行邮件合并. 自定义数据源主要是通过实现IMailM ...
- 20. Spring Boot 默认、自定义数据源 、配置多个数据源 jdbcTemplate操作DB
Spring-Boot-2.0.0-M1版本将默认的数据库连接池从tomcat jdbc pool改为了hikari,这里主要研究下hikari的默认配置 0. 创建Spring Boot项目,选中 ...
- WinForm中使用CrystalReport水晶报表——基础,分组统计,自定义数据源
开篇 本篇文章主要是帮助刚开始接触CrystalReport报表的新手提供一个循序渐进的教程.该教程主要分为三个部分1)CrystalReport的基本使用方法:2)使用CrystalReport对数 ...
- 如何在ASP.NET Core自定义中间件中读取Request.Body和Response.Body的内容?
原文:如何在ASP.NET Core自定义中间件中读取Request.Body和Response.Body的内容? 文章名称: 如何在ASP.NET Core自定义中间件读取Request.Body和 ...
随机推荐
- 博客中css样式的正确设置
一.简介 博客园的文章是支持html代码和css样式的,即使是markdown写作.当某个标签需要特制样式时,我们可以自定义样式来覆盖掉原本的样式. 二.css样式优先级 参考至>>菜鸟教 ...
- js中单引号和双引号区别
总结: 1.无论单引号还是双引号都是成双成对出现的,否则报错!浏览器在读到第一个双引号开始,第二个双引号结束,同样浏览器读取单引号也是第一个开始,第二个单引号结束,在使用的时候必须遵循规则那就是一对双 ...
- luogu P6835 概率DP 期望
luogu P6835 概率DP 期望 洛谷 P6835 原题链接 题意 n + 1个节点,第i个节点都有指向i + 1的一条单向路,现在给他们添加m条边,每条边都从一个节点指向小于等于自己的一个节点 ...
- AcWing 392. 会合
一个思路不难,但是实现起来有点毒瘤的题. 显然题目给出的是基环树(内向树)森林. 把每一个基环抠出来. 大力分类讨论: 若 \(a, b\) 不在一个联通量里,显然是 \(-1, -1\) 若 \(a ...
- 算法——移掉K位数字使得数值最小
给定一个以字符串表示的非负整数 num,移除这个数中的 k 位数字,使得剩下的数字最小. leetcode 解题思路:如果这个数的各个位是递增的,那么直接从最后面开始移除一定就是最最小的:如果这个数的 ...
- mac系统下用ssh方式连接git仓库
1.应用程序-终端,键入命令 ssh-keygen -t rsa -C "xxxxx@xxxxx.com" ,后面是你的邮箱地址.一直回车,生成密钥. 2.键入 open ~ ...
- shell--检查apache是否启动脚本
#首先我们需要检查apache是否以启动,这里我们用到的说nmap命令,Linux默认情况下是没有安装nmap命令的. #那么我们需要安装下nmap,安装的命令很简单:yum -y install n ...
- 微信小程序日期转换、比较、加减
直接上干货: 在utils目录下新建一个dateUtil.js,代码如下:(在需要用的地方引入这个js,调用相关方法传入对应参数就可以使用了) 该工具脚本,实用性很高,通用于各类前端项目,熟悉后亦可以 ...
- uniapp保存图片到本地(APP和微信小程序端)
uniapp实现app端和微信小程序端图片保存到本地,其它平台未测过,原理类似. 微信小程序端主要是权限需要使用button的开放能力来反复调起,代码如下: 首先是条件编译两个平台的按钮组件: < ...
- C++ 消失的析构函数 —— virtual 实现的动态析构
在C++类的结构中可以使用类方法创建内存,使用类的析构函数去施放内存,但有这么一种情况会导致:即使在析构函数中释放了内存,但由于析构函数没有被调用而导致内存泄漏,如下代码. 1 #include &l ...