对抗生成网络 Generative Adversarial Networks


如果想让generator生成想要的目标数据,就把这些真实数据作为discriminator的输入,discriminator的另一部分输入就是generator生成的数据。
1. 初始化generator和discriminator。
2. 迭代:
固定generator的参数,更新discriminator的参数,maximize f
固定discriminator的参数,更新generator的参数,minimize f

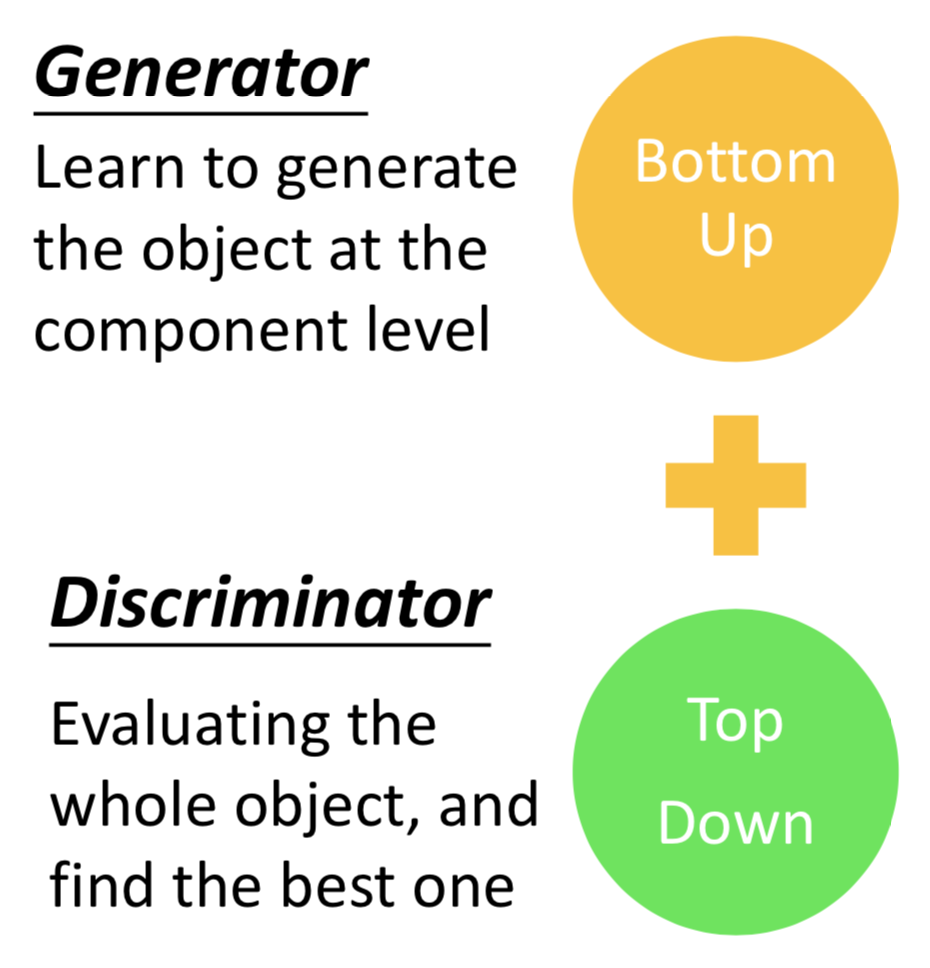
Structured Learning/Prediction: 输出一个序列、矩阵、图、树... Output is composed of components with dependency
重要的是各个components之间的关系。
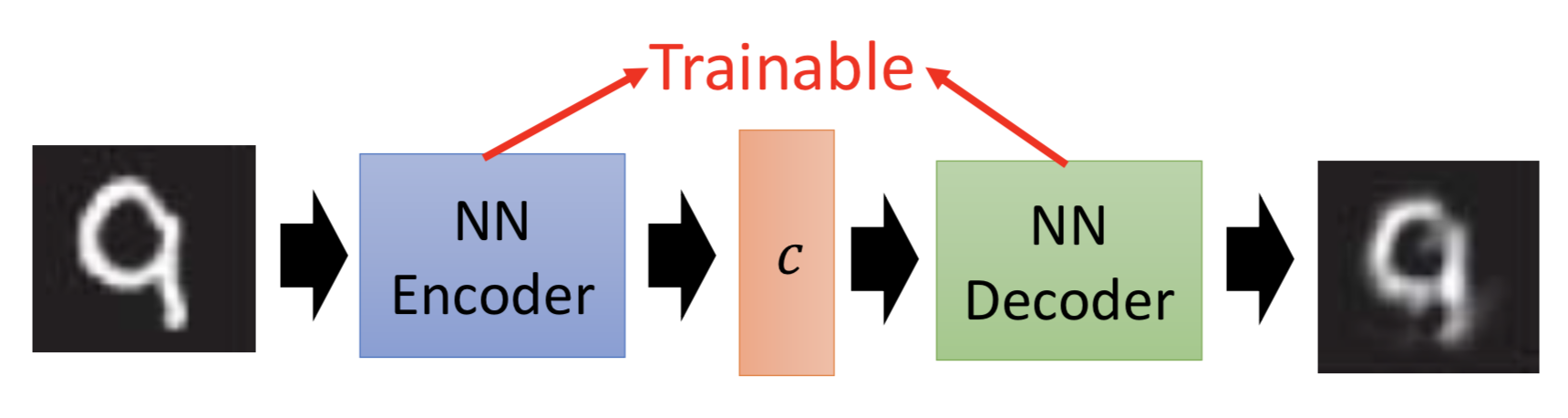
其实是可以的。把 <code, object> 的 pair 作为训练数据对,据此训练一个NN来拟合code和object之间的映射关系即可。




GAN 的优势,从 generator 和 discriminator 两部分来看,一个是生成容易、一个是判别的整体性

6. Conditional generation
典型任务:text-to-image,输入一段文字,输出一个对应的图片。







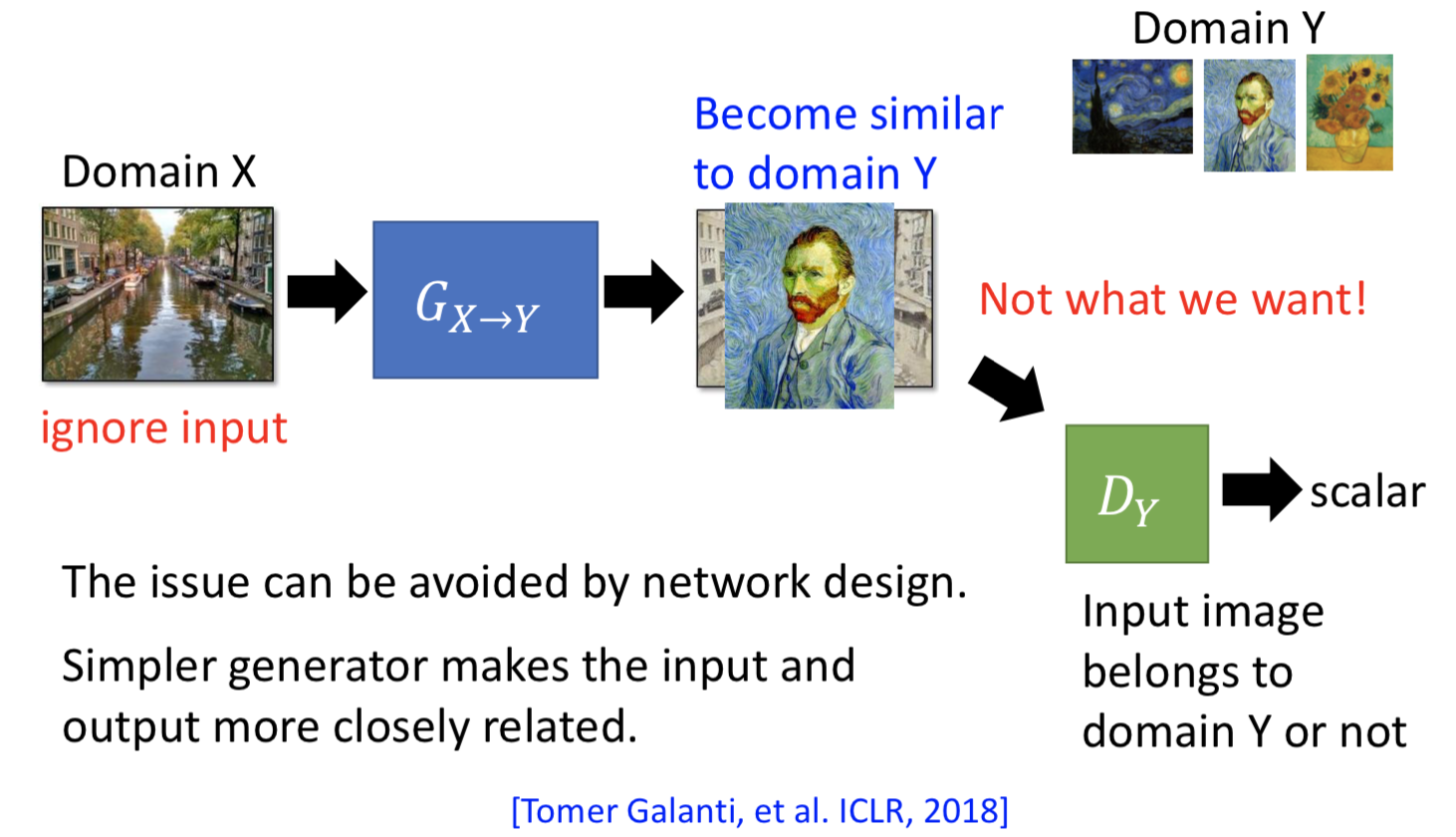
1. 直接忽视 generator 生成数据和输入的联系,硬做就好。但前提是 generator 不要太深(generator 不会把输入变得太多)。
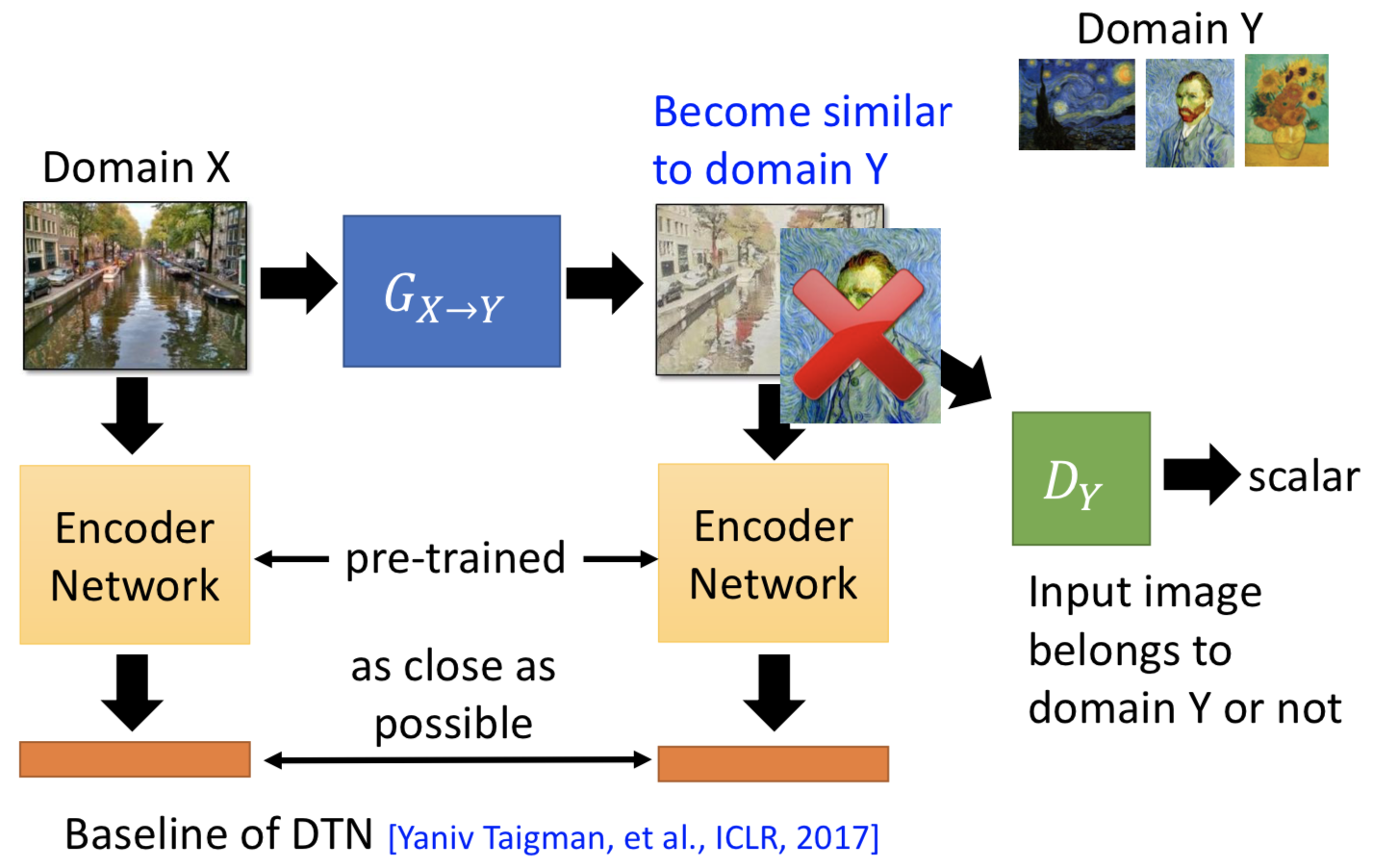
2. 拿一个 pre-trained 的模型出来,对 generator 的输入和输出都做 embedding。训练 generator 的时候,不仅要骗过 discriminator 让生成图片和目标图片越像越好,同时也要让两个 embedding 后的向量不要差太多。
3. Cycle GAN,一个 generator 负责从 domain x 转到 domain y,另一个 generator 负责转回来。所以 generator 不仅要骗过 discriminator,还要使得转回来之后越像越好。Cycle GAN 也可以做双向的。
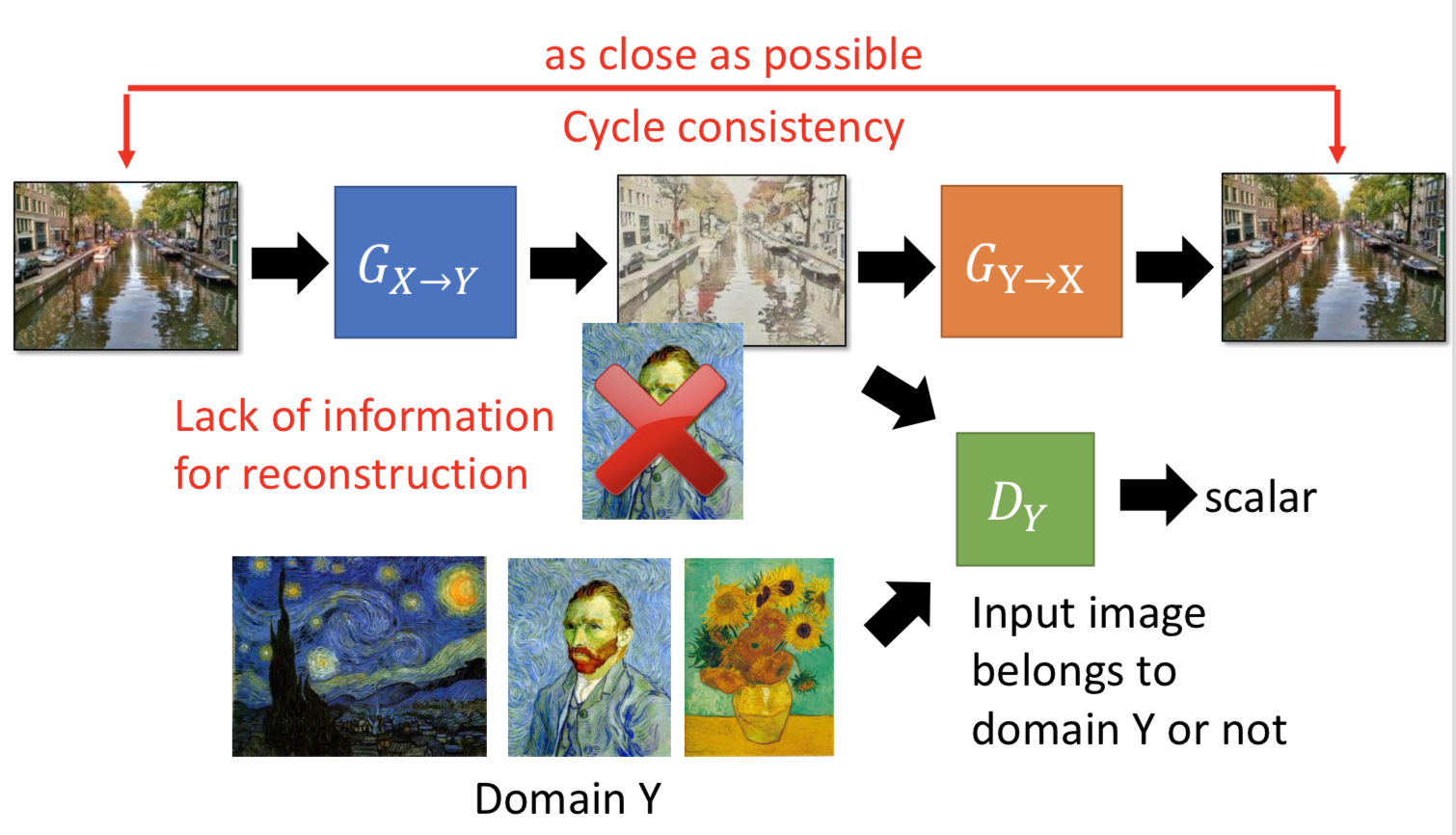
4. Star GAN,多个 domain 之间互相转。


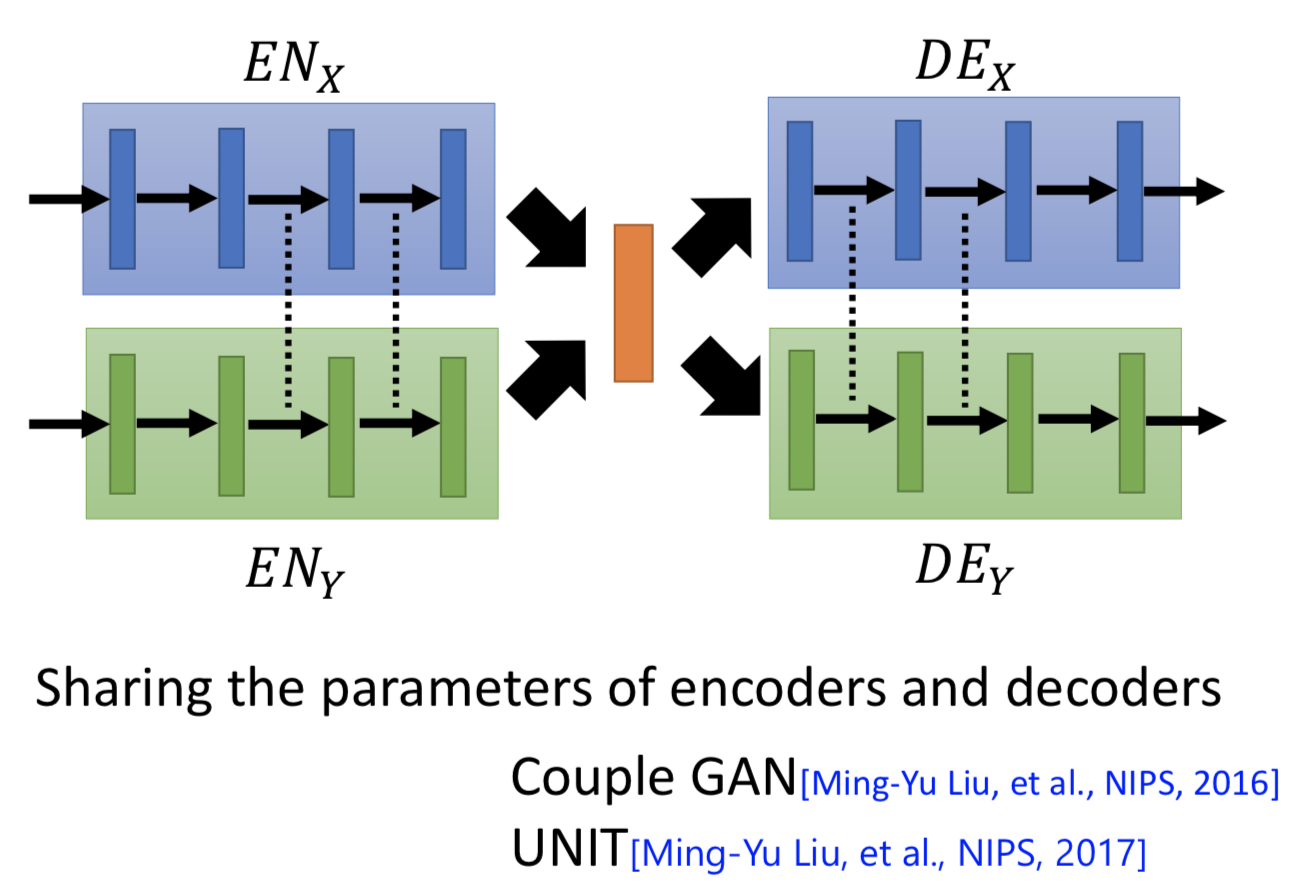
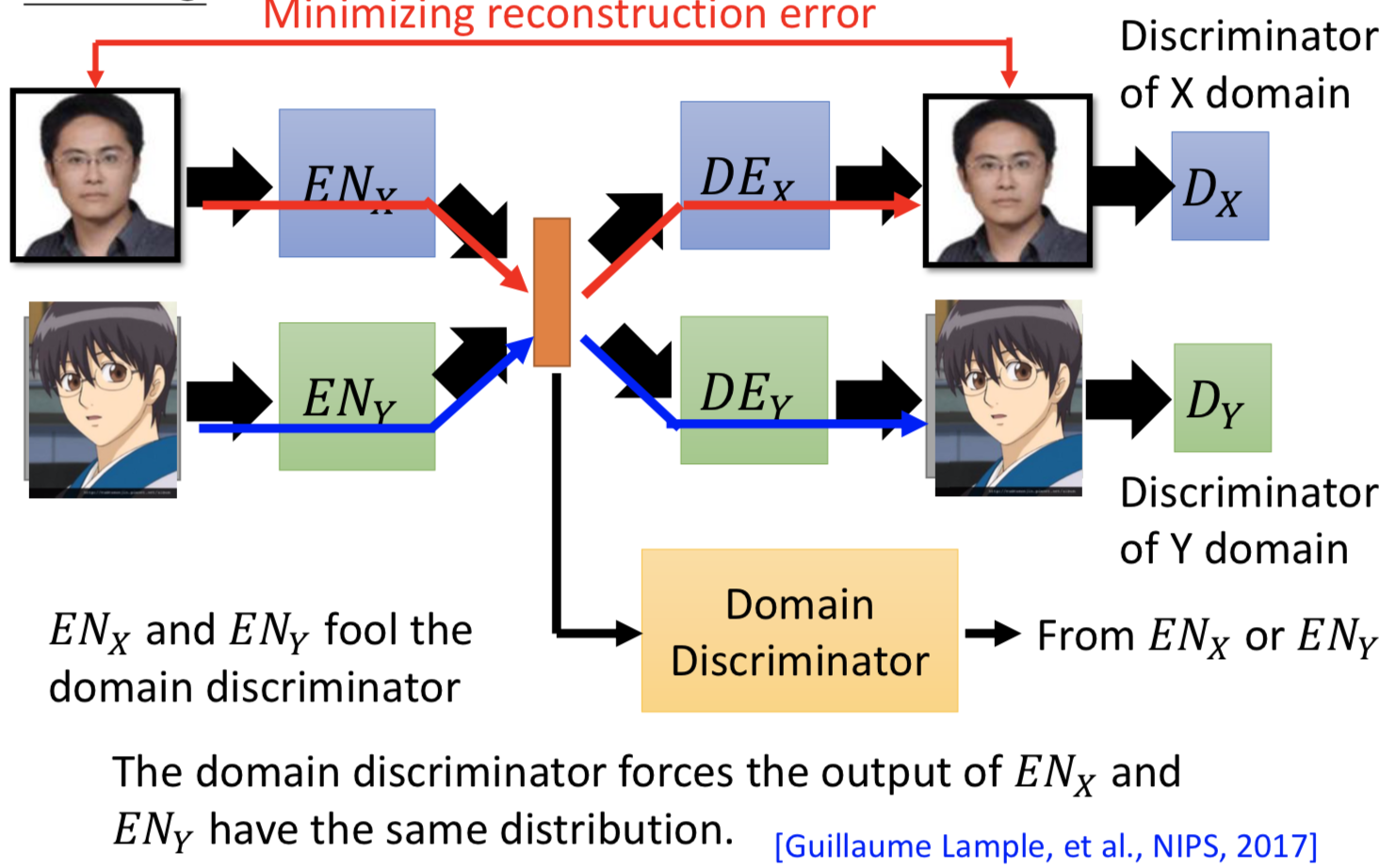
2. 再加一个 domain discriminator,来判别 latent space 的向量是来自 domain x 和 domain y。ENx 和 ENy 就是要骗过这个disriminator,强制不同 domain 的具有同属性的输入经过 encoder 之后都投到一个 latent space 里面并且 code 在空间中的位置越接近越好。
3. cycle consistency
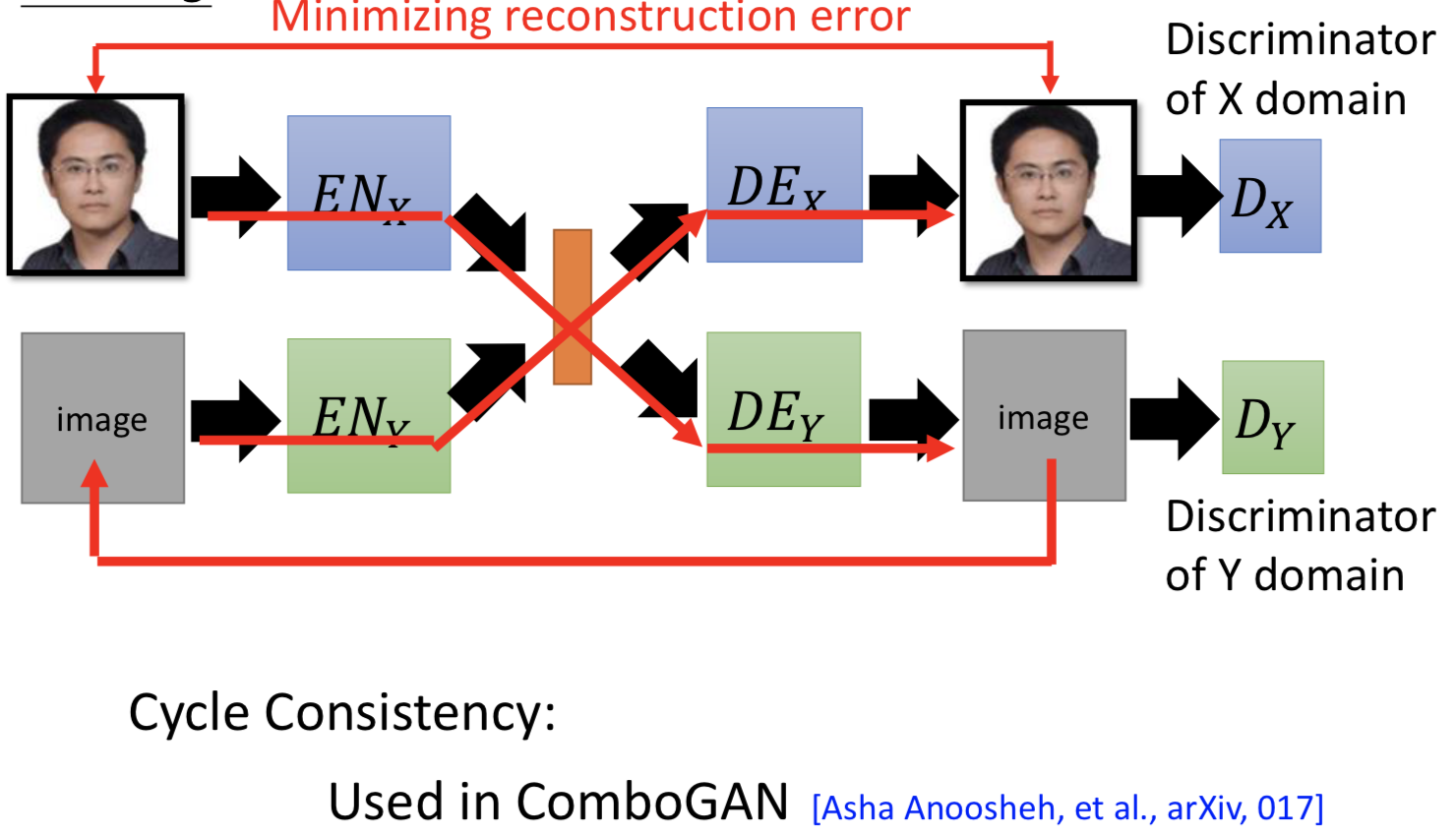
4. semantic consistency

对抗生成网络 Generative Adversarial Networks的更多相关文章
- 一文读懂对抗生成学习(Generative Adversarial Nets)[GAN]
一文读懂对抗生成学习(Generative Adversarial Nets)[GAN] 0x00 推荐论文 https://arxiv.org/pdf/1406.2661.pdf 0x01什么是ga ...
- 生成对抗网络 Generative Adversarial Networks
转自:https://zhuanlan.zhihu.com/p/26499443 生成对抗网络GAN是由蒙特利尔大学Ian Goodfellow教授和他的学生在2014年提出的机器学习架构. 要全面理 ...
- 生成对抗网络(Generative Adversarial Networks,GAN)初探
1. 从纳什均衡(Nash equilibrium)说起 我们先来看看纳什均衡的经济学定义: 所谓纳什均衡,指的是参与人的这样一种策略组合,在该策略组合上,任何参与人单独改变策略都不会得到好处.换句话 ...
- 生成对抗网络(Generative Adversarial Networks, GAN)
生成对抗网络(Generative Adversarial Networks, GAN)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的学习方法之一. GAN 主要包括了两个部分,即 ...
- Perceptual Generative Adversarial Networks for Small Object Detection
Perceptual Generative Adversarial Networks for Small Object Detection 感知生成对抗网络用于目标检测 论文链接:https://ar ...
- StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation - 1 - 多个域间的图像翻译论文学习
Abstract 最近在两个领域上的图像翻译研究取得了显著的成果.但是在处理多于两个领域的问题上,现存的方法在尺度和鲁棒性上还是有所欠缺,因为需要为每个图像域对单独训练不同的模型.为了解决该问题,我们 ...
- SAGAN:Self-Attention Generative Adversarial Networks - 1 - 论文学习
Abstract 在这篇论文中,我们提出了自注意生成对抗网络(SAGAN),它是用于图像生成任务的允许注意力驱动的.长距离依赖的建模.传统的卷积GANs只根据低分辨率图上的空间局部点生成高分辨率细节. ...
- 文献阅读报告 - Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks
paper:Gupta A , Johnson J , Fei-Fei L , et al. Social GAN: Socially Acceptable Trajectories with Gen ...
- 语音合成论文翻译:2019_MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
论文地址:MelGAN:条件波形合成的生成对抗网络 代码地址:https://github.com/descriptinc/melgan-neurips 音频实例:https://melgan-neu ...
随机推荐
- 从零开始的SpringBoot项目 ( 四 ) 整合mybatis
一.创建一个SpringBoot项目 从零开始的SpringBoot项目 ( 二 ) 使用IDEA创建一个SpringBoot项目 二.引入相关依赖 <!--mysql数据库驱动--> & ...
- Java面试题(Spring Boot/Spring Cloud篇)
Spring Boot/Spring Cloud 104.什么是 spring boot? SpringBoot是一个框架,一种全新的编程规范,他的产生简化了框架的使用,所谓简化是指简化了Spring ...
- 焦大:seo思维进化论(番外)
http://www.wocaoseo.com/thread-54-1-1.html 我已经在博客说了学seo研究算法是愚蠢的行为,但是很多人仍旧来问se的算法问题,其中最多的就是问TF-IDF算法, ...
- 大牛浅谈Web测试基于实际测试的功能测试点总结
今天跟大家讲解的是web测试在实际测试的功能测试点的一些小总结,希望对你们有帮助,有说的不好的地方,还请多多指教! 一.页面链接检查:测试每一个链接是否都有对应的页面,并且页面之前可以正确切换. ...
- csp201909-2小明种苹果续
/* 定义输入N 二维数组 输出T总数 D掉落棵树 E掉落组数 定义last记录上次掉落的编号,flag=1表示两次连续掉落,不掉落归零 spec=1表示1 2都掉落了,spec=2表示只有1掉落 对 ...
- PageObject六大原则
The public methods represent the services that the page offers 公共方法表示页面提供的服务 Try not to expose the i ...
- [HGAME] Week1 Web WriteUp
一 .Cosmos的博客 打开题目之后,首页直接给了我们提示: 版本管理工具常用的有git和svn两种,这里提示了GitHub,考虑Git信息泄露,先访问/.git/目录考虑用Githack获取泄露信 ...
- 查看CentOs6.5/7的系统版本号
在centos6.5上用 [root@msg45 ~]# lsb_release -aLSB Version: :base-4.0-amd64:base-4.0-noarch:core-4.0- ...
- 三年前买的T440p目前淘宝二手价2300左右
当时可是近六千买的,唉... 有消息说六千多电脑和四千多的区别是多了OEM Windows的价钱,如果一重装,等于把差价抹了... 看来买电脑,买车,买手机都该秉承一个够用就好的原则,不然当时的顶配不 ...
- Java数组实现随机生成N-M之间不重复的随机数
接收一个整形数组,使用Math.Random每次在规定的数字范围内随机产生数字,然后嵌套for循环依次判断是否有重复值,如果有既外循环变量减一,直到把数组装满为止. /** * 随机生成 N--M的不 ...