要不是真的喜欢学技术,谁会来用Python爬小姐姐啊
养成习惯,先赞后看!!!
不用于任何商业价值,只是自己娱乐。
否则 爬虫爬的好,牢饭吃到饱。
这是我们这次爬取的网址:https://www.vmgirls.com/
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:101677771
爬取并下载唯美女生
1.准备工作
这次我们主要运用四个模块分别是
BeautifulSoup:主要用于我们来分析网页信息
requests:主要是用于我们来请求网页
re:正则表达式,帮组我们来匹配实际需要的信息
os:主要负责帮我们下载图片
2.分析网页+实际操作
一开始我们先分析单个页面进行爬取下载,之后我们在分析首页获取到所有页面的链接,最后对我们之前的代码进行整合规范化。
2.1分析页面1
页面网址:https://www.vmgirls.com/9384.html
![]()
我们通过鼠标定位到我们需要爬取的图片的信息就在上图红色方框中,并且通过观察页面的格式我们发现大体格式基本一样,基本都是下面这种样式:
<img alt="酸酸的,甜甜的-唯美女生" width="2904" height="4356"
class="alignnone size-full loaded"
data-src="data:image/2018/08/2018-08-10_13-52-47.jpg"
data-nclazyload="true" data-pagespeed-url-hash="1859759222"
onload="pagespeed.CriticalImages.checkImageForCriticality(this);"
data-pagespeed-lsc-url="https://www.vmgirls.com/image/2018/08/2018-08-10_13-52-47.jpg"
src="data:image/2018/08/2018-08-10_13-52-47.jpg" data-was-processed="true">
![]()
并且通过分析我们可以得到图片的链接其实就在img的data-pagespeed-lsc-url属性之中,那么我们就来尝试先将所有的img空间爬取下来
import requests
from bs4 import BeautifulSoup
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"
}
response=requests.get('https://www.vmgirls.com/9384.html',headers=headers)
html=response.text
"""解析网页"""
findImgsrc=re.compile(r'data-src="(.*?)"')
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all("img", class_="alignnone size-full"):
print(item)
![]()

![]() 但是当我们爬取下来之后发现img控件中并没有data-pagespeed-lsc-url这个属性,那么我们怎么办呢?别急继续看我们发现虽然没有data-pagespeed-lsc-url但是data-src属性和data-pagespeed-lsc-url也差不多,只是缺少了部分请求头,这个我们完全可以通过后续的字符串操作进行修改得到,所以我们编写正则表达式进行匹配获取到我们需要的信息
但是当我们爬取下来之后发现img控件中并没有data-pagespeed-lsc-url这个属性,那么我们怎么办呢?别急继续看我们发现虽然没有data-pagespeed-lsc-url但是data-src属性和data-pagespeed-lsc-url也差不多,只是缺少了部分请求头,这个我们完全可以通过后续的字符串操作进行修改得到,所以我们编写正则表达式进行匹配获取到我们需要的信息
findImgsrc=re.compile(r'data-src="(.*?)"')
![]()
就这简单一句就行了,获取到了还不行,因为他还不符合我们图片链接的规范,所以我们还需要对该字符进行处理。
datas = []
for item in soup.find_all("img", class_="alignnone size-full"):
print(item)
item = str(item)
link = re.findall(findImgsrc, item)[0]
datas.append("https://www.vmgirls.com/"+link[0:38])
![]()
- 们便能够获取到该页面所有的图片链接了

 获取到图片链接之后我们就需要来下载图片,这里我们主要运用的就是os模块
获取到图片链接之后我们就需要来下载图片,这里我们主要运用的就是os模块
"""创建文件夹名称"""
dir_name=re.findall('<h1 class="post-title h3">(.*?)</h1>',html)[0]
if not os.path.exists(dir_name):
os.mkdir(dir_name)
print(dir_name)
"""保存图片"""
for data in datas:
# 图片名称
time.sleep(0.5)
file_name=data.split("/")[-1]
response=requests.get(data,headers=headers)
with open(dir_name+'/'+file_name,'wb') as f:
f.write(response.content)
print(file_name+"下载成功")
![]()
到此我们的第一个页面就分析结束了
2.2分析页面2
页面网址:https://www.vmgirls.com/12985.html
按道理其实每个页面的布局以及设计基本上都应该是一样的,但是这个网站有点奇怪。他的页面之间有一些不同像下面这个: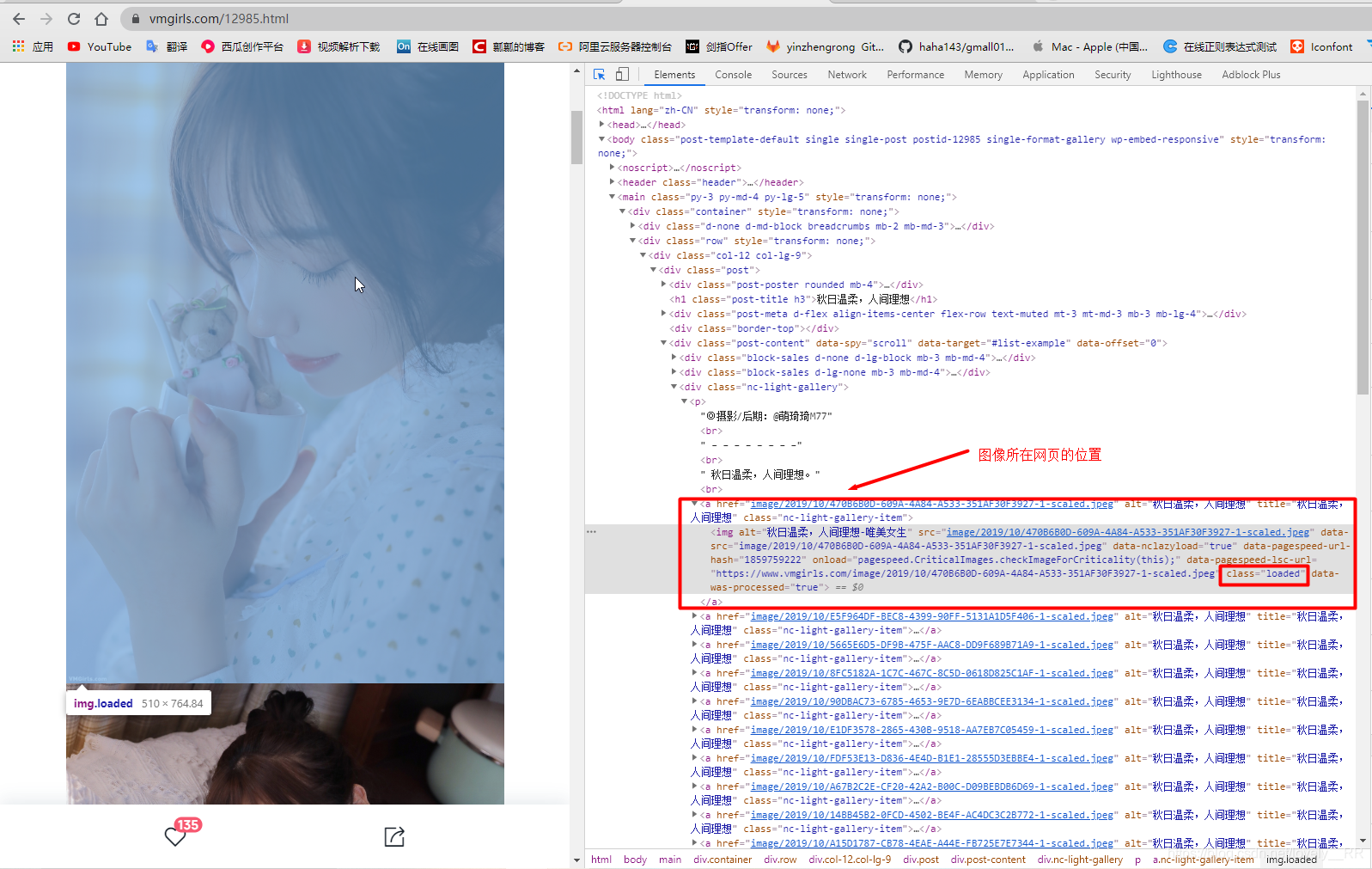
![]() 可能乍看上去大家觉得可能是一样的,但是通过对比图大家就能看出来了
可能乍看上去大家觉得可能是一样的,但是通过对比图大家就能看出来了
![]() 我选择的另一种方式就是直接通过他的a标签来获取图片的链接,我们分析它的a标签的结构,设计下面的正则表达式来进行匹配:
我选择的另一种方式就是直接通过他的a标签来获取图片的链接,我们分析它的a标签的结构,设计下面的正则表达式来进行匹配:
re.findall('<a href="(.*?)" alt=".*?" title=".*?">',html)
![]()
接下来我们爬取看看是不是我们需要的
for item in re.findall('<a href="(.*?)" alt=".*?" title=".*?">',html):
print(item)
![]()

![]() 显然爬出来的和上述的情况一样,我们还需要为他添加请求头
显然爬出来的和上述的情况一样,我们还需要为他添加请求头
for item in re.findall('<a href="(.*?)" alt=".*?" title=".*?">',html):
print("https://www.vmgirls.com/" + item)
![]()
这样我们再看看如何
![]() 这样就已经变成链接了。
这样就已经变成链接了。
到这里第二个页面我们也已经分析完毕了。
2.3分析首页
如果只是单个页面的爬取,显然还是不能满足博主,毕竟只有一个小姐姐。博主我选择
![]() 那么既然这样我们就需要来分析首页的网页结构,但是看完首页的网页结构,我们发现
那么既然这样我们就需要来分析首页的网页结构,但是看完首页的网页结构,我们发现
![]() 他整个页面上并不存在任何分页的控件,所以像之前豆瓣那样的爬取是不行了,接着我们看
他整个页面上并不存在任何分页的控件,所以像之前豆瓣那样的爬取是不行了,接着我们看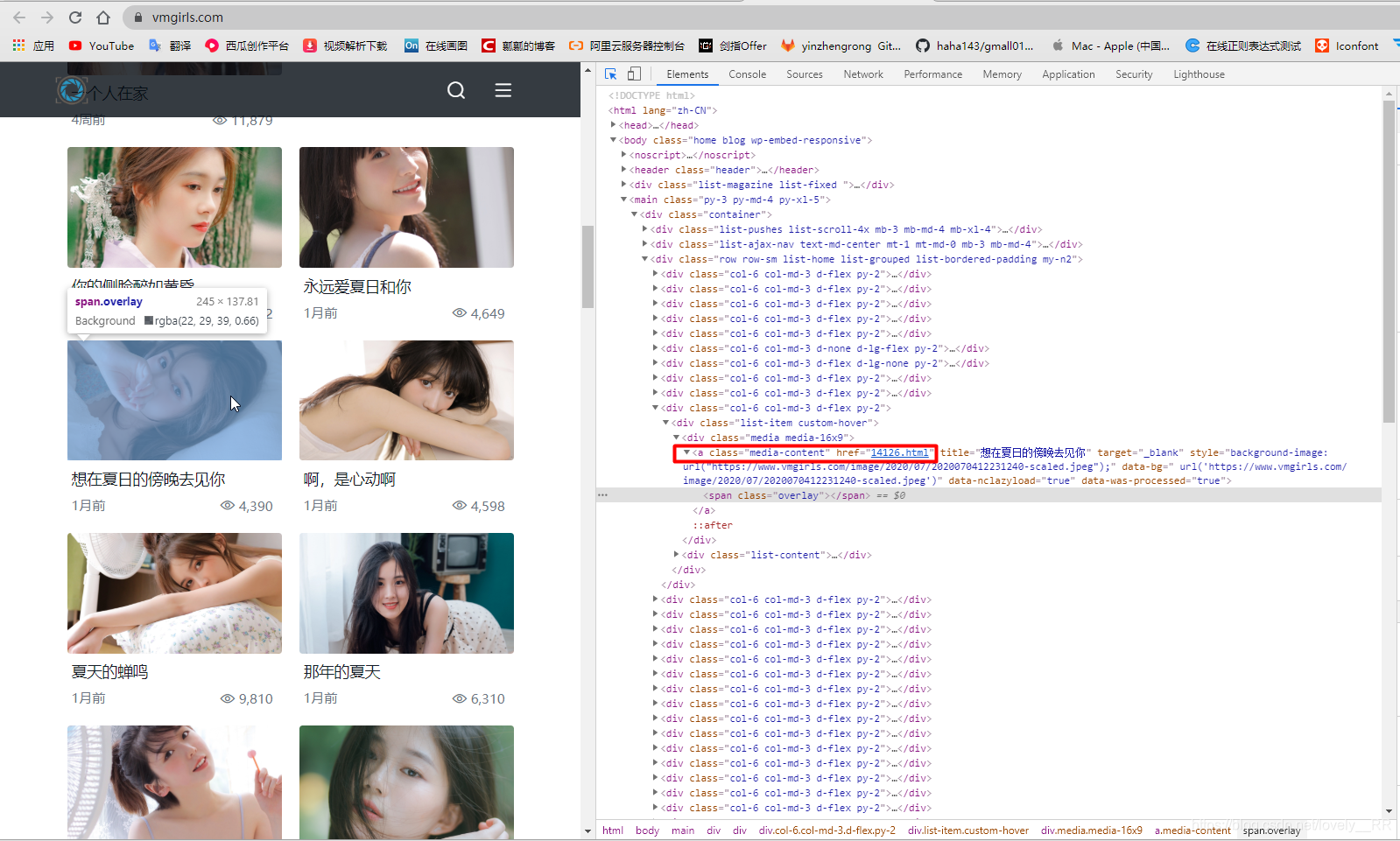
![]() 这里不就是我们需要的链接,所以我们可以分析整个网页,将他所有的链接全部保存下来,之后我们再去一个一个访问不就行了
这里不就是我们需要的链接,所以我们可以分析整个网页,将他所有的链接全部保存下来,之后我们再去一个一个访问不就行了
"""解析网页获取到所有页面的URL"""
def getlink(html):
soup = BeautifulSoup(html, "html.parser")
datas = []
for item in soup.find_all("a", class_="media-content"):
item = str(item)
//判断是否含有元素
if len(re.findall(findLink, item))!=0:
link = re.findall(findLink, item)[0]
//重新构造成我们需要的网页链接
newlink="https://www.vmgirls.com/" + link
//并且进行去重操作
if newlink not in datas:
datas.append(newlink)
![]()
之后我们来看结果
![]() 这样我们就爬取到了页面上的所有网址链接了。
这样我们就爬取到了页面上的所有网址链接了。
2.4整合代码,准备起飞
上面的准备工作已经全部完成了,接下来我们就将各个模块的代码进行封装,方便我们调用,并且使代码更加的规范化。
8月13日更新一次代码,由于之前的请求头模拟的不够彻底,导致网站认定我们是爬虫,下载能下载,但是会出现图片打不开的情况,所以添加了部分请求头的信息
8月25日更新一次代码,原因还是上面的原因,这次主要是针对请求头中的COOKIE数据,建议做好复制浏览器中自己的cookie,并且主要是针对下载文件时请求网页的请求头
整体流程;
1.获取首页的所有页面链接
"""解析网页获取到所有页面的URL"""
def getlink(html):
soup = BeautifulSoup(html, "html.parser")
datas = []
for item in soup.find_all("a", class_="media-content"):
item = str(item)
if len(re.findall(findLink, item))!=0:
link = re.findall(findLink, item)[0]
newlink="https://www.vmgirls.com/" + link
if newlink not in datas:
datas.append(newlink)
# print(datas)
return datas
![]()
2.循环爬取各个页面的图片链接
"""解析网页获取到该页面的所有图片链接"""
def getdata(html):
soup = BeautifulSoup(html, "html.parser")
datas = []
for item in soup.find_all("img", class_="alignnone size-full"):
# print(item)
item = str(item)
link = re.findall(findImgsrc, item)[0]
datas.append("https://www.vmgirls.com/" + link[0:38])
for item in re.findall('<a href="(.*?)" alt=".*?" title=".*?">', html):
# print(item)
datas.append("https://www.vmgirls.com/" + item)
# print(datas)
return datas
![]()
3.根据链接创建相应的文件夹
"""创建文件夹名称"""
def createdir(html):
dir_name=re.findall('<h1 class="post-title h3">(.*?)</h1>',html)[0]
if not os.path.exists(dir_name):
os.mkdir(dir_name)
return dir_name
![]()
4.在相应的文件夹中下载图片
"""保存图片"""
def download(datas,dir_name):
for data in datas:
time.sleep(0.25)
file_name=data.split("/")[-1]
response=requests.get(data,headers=headers)
with open(dir_name+'/'+file_name,'wb') as f:
f.write(response.content)
print(file_name+"下载成功")
![]()
修改后的完整代码:
import time
import requests
import re
from bs4 import BeautifulSoup
import os
findImgsrc=re.compile(r'data-src="(.*?)"')
findLink=re.compile(r'href="(.*?)"')
headers={
"cookie": "_ga=GA1.2.1285440638.1596454858; verynginx_sign_javascript=9afce94d2a1677e47daf110997b372be; _gid=GA1.2.2085095474.1597149513; xcat_sign_cookie=2bf90ba8c55955f8cb9db86e256cf3f6; Hm_lvt_a5eba7a40c339f057e1c5b5ac4ab4cc9=1597149513,1597193455,1597218065,1597295111; _GPSLSC=; Hm_lpvt_a5eba7a40c339f057e1c5b5ac4ab4cc9=1597308777",
"if-none-match": 'W/"5dff458a-212202"',
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"}
headers2={
"cookie": "_ga=GA1.2.1285440638.1596454858; verynginx_sign_javascript=9afce94d2a1677e47daf110997b372be; xcat_sign_cookie=cfd666fa7ecf4e4a515ba54ea928d4b9; Hm_lvt_a5eba7a40c339f057e1c5b5ac4ab4cc9=1597218065,1597295111,1597374224,1598267245; _gid=GA1.2.1757491204.1598267245; _GPSLSC=; Hm_lpvt_a5eba7a40c339f057e1c5b5ac4ab4cc9=1598267370",
"if-none-match": 'W/"5dff458a-212202"',
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36",}
def main():
print("主程序入口")
urls = getlink(askURL('https://www.vmgirls.com/'))
# print(urls)
for url in urls:
html = askURL(url)
dir_name = createdir(html)
print("开始爬取" + dir_name)
data = getdata(html)
# print(data)
download(data, dir_name)
print(dir_name + "已经下载完毕")
"""请求网页信息"""
def askURL(url):
response=requests.get(url,headers=headers)
html=response.text
return html
# print(html)
"""解析网页获取到该页面的所有图片链接"""
def getdata(html):
soup = BeautifulSoup(html, "html.parser")
datas = []
for item in soup.find_all("img", class_="alignnone size-full"):
# print(item)
item = str(item)
link = re.findall(findImgsrc, item)[0]
datas.append("https://www.vmgirls.com/" + link[0:38])
for item in re.findall('<a href="(.*?)" alt=".*?" title=".*?">', html):
# print(item)
datas.append("https://www.vmgirls.com/" + item)
# print(datas)
return datas
"""解析网页获取到所有页面的URL"""
def getlink(html):
soup = BeautifulSoup(html, "html.parser")
datas = []
for item in soup.find_all("a", class_="media-content"):
item = str(item)
if len(re.findall(findLink, item))!=0:
link = re.findall(findLink, item)[0]
newlink="https://www.vmgirls.com/" + link
if newlink not in datas:
datas.append(newlink)
# print(datas)
return datas
"""创建文件夹名称"""
def createdir(html):
dir_name=re.findall('<h1 class="post-title h3">(.*?)</h1>',html)[0]
if not os.path.exists(dir_name):
os.mkdir(dir_name)
return dir_name
"""保存图片"""
def download(datas,dir_name):
for data in datas:
time.sleep(1)
file_name=data.split("/")[-1]
# print(data)
response=requests.get(data,headers=headers2)
with open(dir_name+'/'+file_name,'wb') as f:
f.write(response.content)
print(file_name+"下载成功")
if __name__ == '__main__':
main()
# init_db("movietest.db")
print("爬取完毕")
![]()
3.效果展示

![]()
都看到这里了,如果觉得对你有帮助的话,可以关注博主的公众号,新人up需要你的支持。
要不是真的喜欢学技术,谁会来用Python爬小姐姐啊的更多相关文章
- 工作8年对技术学习过程的一些 总结 与 感悟 为什么有时迷茫、无奈 学习编程语言的最高境界最重要的是编程思想 T 字发展 学技术忌讳”什么都会“ 每天进步一点等式图 时间管理矩阵
工作这些年对技术学习过程的一些 总结 与 感悟(一) 引言 工作了8年,一路走来总有些感触时不时的浮现在脑海中.写下来留个痕迹,也顺便给大家一点参考.希望能给初学者一点帮助. 入门 进入计算机行业,起 ...
- 《学技术练英语》PPT分享
之前做的一个PPT,分享给博客园的同学. 下载地址: 学技术练英语.pdf 技术是靠自己去学的,学技术不能仅仅是看书看博客,最好是有实践,不管是做实验去验证,还是写各种代码去玩各种特性,还是造轮子都是 ...
- MIP技术进展月报第3期:MIP小姐姐听说,你想改改MIP官网?
一. 官网文档全部开源 MIP 是一项永久的开源的项目,提供持续优化的解决方案,当然官网也不能例外.从现在开始,任何人都可以在 MIP 官网贡献文档啦! GitHub 上,我们已经上传了 <官网 ...
- 小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码)
小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码) Python 被称为是最接近 AI 的语言.最近一位名叫Anna-Lena Popkes的小姐姐在GitHub上分享了自己如何使用P ...
- WebGL小姐姐教我学画画之起手式
初次接触WebGL,如有错误之处欢迎留言,共同学习进步. v WebGL的自画像 我,WebGL,全名Web Graphics Library,是为了让死宅程序猿们(摊手)能在浏览器上为所欲为的画女朋 ...
- <小白学技术>将python脚本导出为exe可执行程序
1.简介(为啥需要导出为exe可执行程序) python写完的程序靠命令来执行,显得太专业,不符合python简单的特点(好吧,主要是太low) 代码给别人执行,别人没有你的python库也没法用(双 ...
- 国外线下技术俱乐部建设(1) - Belgrade Python技术俱乐部2019-01-25活动感悟
这是<国外线下技术俱乐部建设>系列文章之一. 虽然之前接触过Belgrade的.NET技术俱乐部,但是它最近活动要春节后了. 出于观摩别人是怎么搞线下社区的心态,还有自己也有在用Pyt ...
- python学完可以做什么?Python就业方向最全面的解析
乔布斯说过:“每一个人都应该学习如何编程,因为编程会教会你如何思考.”下一个时代是人机交互的时代,学习编程不是要让你成为程序员,而让你理解这个时代. 点击免费领取:全网最全python学习导图+14张 ...
- 无语——真的好用到不行的7个Python小技巧
本文总结了我几个我在学习python过程中,用到的几个超好用的操作,这里分享给大家,我相信你们也会非常喜欢,目录如下.这里提前索要再看,记得点一点再看哦.这只是其中一些技巧,以后会慢慢和大家分享. 1 ...
随机推荐
- luogu P3223 [HNOI2012]排队
LINK:排队\ 原谅我没学过组合数学 没有高中数学基础水平... 不过凭着隔板法的应用还是可以推出来的. 首先考虑女生 发现一个排列数m! 两个女生不能相邻 那么理论上来说存在无解的情况 而这道题好 ...
- python程序设计PDF高清完整版免费下载|百度云盘
百度云盘:python程序设计PDF高清完整版免费下载 提取码:bvsz Python 程序设计基础难易程度适中.除Python应用开发基础知识之外,还适当介绍了Python标准库以及内置对象的工作原 ...
- 数据结构C语言实现----快速排序
快速排序算法 首先看下面这个例子: 我们取第一个元素为基准元素: 之后,从右边开始与基准元素挨个比较,如果比基准元素大,右指针往左移,如果比基准元素小,就与左指针指的元素交换(因为左指针永远停留在一 ...
- hashCode竟然不是根据对象内存地址生成的?还对内存泄漏与偏向锁有影响?
起因 起因是群里的一位童鞋突然问了这么问题: 如果重写 equals 不重写 hashcode 会有什么影响? 这个问题从上午10:45 开始陆续讨论,到下午15:39 接近尾声 (忽略这形同虚设的马 ...
- “随手记”开发记录day13
今天继续对我们的项目进行更改. 今天我们需要做的是增加“修改”功能.对于已经添加的记账记录,长按可以进行修改和删除的操作. 但是今天并没有完成……
- node根据excel批量更名
程序预览 index.js var xlsx = require('node-xlsx'); var fs = require('fs'); process.stdin.setEncoding('ut ...
- 全程干货,requests模块与selenium框架详解
requests模块 前言: 通常我们利用Python写一些WEB程序.webAPI部署在服务端,让客户端request,我们作为服务器端response数据: 但也可以反主为客利用Python的re ...
- 有用的20个Python代码段
Python是一种非BS编程语言.设计简单和易读性是它广受欢迎的两大原因.正如Python的宗旨:美丽胜于丑陋,显式胜于隐式. 记住一些帮助提高编码设计的常用小诀窍是有用的.在必要时刻,这些小诀窍能够 ...
- Pytorch_第九篇_神经网络中常用的激活函数
神经网络中常用的激活函数 Introduce 理论上神经网络能够拟合任意线性函数,其中主要的一个因素是使用了非线性激活函数(因为如果每一层都是线性变换,那有啥用啊,始终能够拟合的都是线性函数啊).本文 ...
- MyBatisPlus性能分析插件,条件构造器,代码自动生成器详解
性能分析插件 我们在平时的开发中,会遇到一些慢sql,测试,druid MP(MyBatisPlus)也提供性能分析插件,如果超过这个时间就停止 不过官方在3.2版本的时候取消了,原因如下 条件构造器 ...