Redis基础(一)数据结构与数据类型
Redis数据结构
Redis一共有六种数据结构,分别是简单动态字符串、链表、字典、跳表、整数集合、压缩列表。
简单动态字符串(SDS)
Redis只会使用C字符串作为字面量,在大多数情况下,Redis使用SDS(Simple Dynamic String,简单动态字符串)作为字符串表示。
SDS的数据结构:
struct sdshdr {
// 记录buf数据中已使用字节的数量
// 等于SDS所保存字符串的长度
int len;
// 记录buf数组中未使用字节的数量
int free;;
// 字节数组,用于保存字符串
char buf[];
}
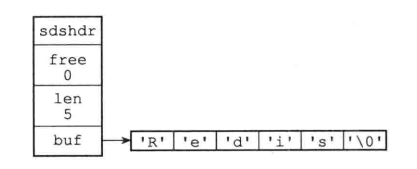
比起C字符串,SDS具有以下优点:
- 常数复杂度获取字符串长度
- 杜绝缓冲区溢出
- 减少修改字符串时带来的内存重分配次数
- 二进行安全
- 兼容部分C字符串函数
链表(list)
链表的数据结构:
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
}listNode;
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值复制函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr,void *key);
}list;
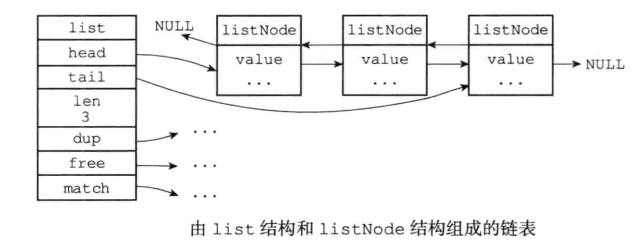
- 链表被广泛用于实现Redis的各种功能,比如列表键、发布与订阅、慢查询、监视器等。
- 每个链表节点由一个listNode结构来表示,每个节点都有一个指向前置节点和后置节点的指针,所以Redis的链表实现是双端链表。
- 每个链表使用一个list结构来表示,这个结构带有表头节点指针、表尾节点指针,以及链表长度等信息。
- 因为链表表头节点的前置节点和表尾节点的后置节点都指向NULL,所以Redis的链表实现是无环链表。
- 通过为链表设置不同的类型特定函数,Redis的链表可以用于保存各种不同类型的值。
字典(dict)
字典的数据结构:
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
}dictht;
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_tu64;
int64_ts64;
}v;
// 指向下一个哈希表节点,形成键表
struct dictEntry *next;
}dictEntry;
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdate;
// 哈希表
dictht ht[2];
// rehash索引
// 当rehash不在进行时,值为-1
in trehashidx; /* rehashing not in progress if rehashidx == -1 */
}dict;
typedef struct dictType {
// 计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
}dictType;
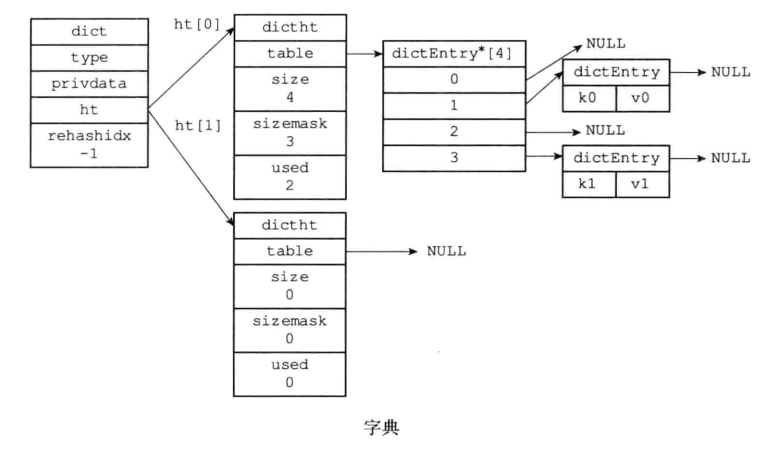
- 字典被广泛用于实现Redis的各种功能,其中包括数据库和哈希键。
- Redis中的字典使用哈希表作为底层实现,每个字典带有两个哈希表,一个平时使用,另一个仅在进行rehash时使用。
- 当字典被用作数据库的底层实现,或者哈希键的底层实现时,Redis使用MurmurHash2算法来计算键的哈希值。
- 哈希表使用键地址法来解决键冲突,被分配到同一个索引上的多个键值对会连接成一个单向链表。
- 在对哈希表进行扩展或者收缩操作时,程序需要将现有哈希表包含的所有键值对rehash到新哈希表里面,并且这个rehash过程并不是一次性地完成的,而是渐进式地完成的。
跳表(skiplist)
跳表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。跳表查询的时间复杂度O(logN)、最坏情况是O(N),还可以通过顺序操作来指处理节点。
跳表的数据结构:
typedef struct zskiplistNode {
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode * forward;
// 跨度
unsigned int span;
} level[];
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
} zskiplistNode;
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;
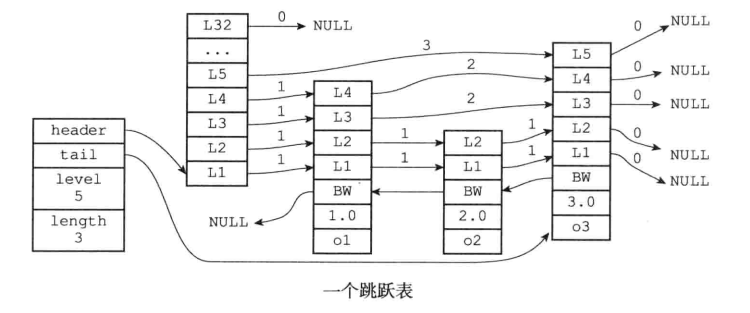
- 跳表是有序集合的底层实现之一。
- Redis的跳表实现由zskiplist和zskiplistNode两个结构组成,其中zskiplist用于保存跳表信息(比如表头节点、表尾节点、长度),而zskiplistNode则用于表示跳表节点。
- 每个跳表节点的层高都是1至32之间的随机数。
- 在同一个跳表中,多个节点可以包含相同的分值,但每个节点的成员对象必须是唯一的。
- 跳表中的节点按照分值大小进行排序,当分值相同时,节点按照成员对象的大小进行排序。
整数集合(intset)
整数集合(intset)是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用整数集合作为集合键的底层实现。
整数集合的数据结构:
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
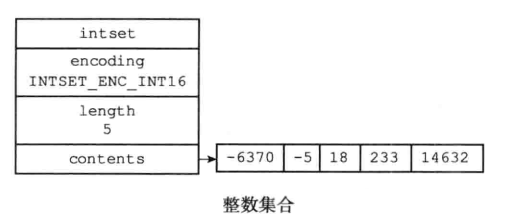
- 整数集合是集合键的底层实现之一。
- 整数集合的底层实现为数组,这个数组以有序、无重复的方式保存集合元素,在有需要时,程序会根据新添加元素的类型,改变这个数组的类型。
- 升级操作为整数集合带来了操作上的灵活性,并且尽可能地节约了内存。
- 整数集合只支持升级操作,不支持降级操作。
压缩列表(ziplist)
压缩列表(ziplist)是列表键和哈希键的底层实现之一。当一个列表链只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做列表键的底层实现。

- 压缩列表是一种为节约内存而开发的顺序型数据结构。
- 压缩列表被用作列表键和哈希键的底层实现之一。
- 压缩列表可以包含多个节点,每个节点可以保存一个字节数组或者整数值。
- 添加新节点到压缩列表,或者从压缩列表中删除节点,可能会引发连锁更新操作,但这种操作出现的几率并不高。
Redis数据类型
Redis中,键的数据类型是字符串,但提供了丰富的数据存储方式,方便开发者使用,值的数据类型有很多,常用的数据类型有五种,分别是字符串(string)、列表(list)、字典(hash)、集合(set)、有序集合(sortedset)。
字符串(string)
“字符串(string)”这种数据结构类型非常简单,对应到数据结构里,就是Redis里的简单动态字符串(SDS)。
列表(list)
列表这种数据类型支持存储一组数据。这种数据类型对应两种实现方法,一种是压缩列表(ziplist),另一种是双向循环链表。
当列表中存储的数据量比较小的时候,列表就可以采用压缩列表的方式实现。具体需要同时满足下面两个条件:
- 列表中保存的单个数据(有可能是字符串类型的)小于64字节;
- 列表中数据个数少于512。
字典(hash)
字典类型用来存储一组数据对。每个数据对又包含键值两部分。字典类型也有两种实现方式。一种是压缩列表,另一种是散列表。
同样,只有当存储的数据量比较小的情况下,Redis才使用压缩列表来实现字典类型。具体需要满足两个条件:
- 字典中保存的键和值的大小都要小于64字节;
- 字典中键值对的个数要小于512个。
集合(set)
集合这种数据类型用来存储一组不重复的数据。有两种实现方式:一种是基于有序数组,另一种是基于散列表。
当要存储的数据,同时满足下面这样两个条件的时候,Redis就采用有序数组,来实现集合这种数据类型。
- 存储的数据都是整数;
- 存储的数据元素个数不超过512个。
有序集合(sortedset)
有序集合用来存储一组数据,并且每个数据会附带一个得分。通过得分的大小,我们将数据组织成跳表这种数据结构,以支持快速地按照得分值、得分区间获得数据。
有序集合也有两种实现方式:跳表和压缩列表。使用压缩列表来实现有序集合的前提:
- 所有数据的大小都要小于64字节;
- 元素个数要小于128个。
参考资料
Redis基础(一)数据结构与数据类型的更多相关文章
- redis基础二----操作set数据类型
set集合是无序的,不能存在重复元素 bbb吃重复元素,是不能添加成功的 2 接下来分析zset,是有序的,你在添加的时候要指定元素的序列号 上面的 3 4 5 6 就是指定的元素的序列号 withs ...
- redis 基础数据结构实现
参考文献 redis数据结构分析 Skip List(跳跃表)原理详解 redis 源码分析之内存布局 Redis 基础数据结构与对象 Redis设计与实现-第7章-压缩列表 在redis中构建了自己 ...
- redis基础02-redis的5种对象数据类型
表格引用地址:http://www.cnblogs.com/xrq730/p/8944539.html 参考书籍:<Redis设计与实现>,<Redis运维与开发> 1.对象 ...
- Redis基础——剖析基础数据结构及其用法
这是一个系列的文章,打算把Redis的基础数据结构.高级数据结构.持久化的方式以及高可用的方式都讲一遍,公众号会比其他的平台提前更新,感兴趣的可以提前关注,「SH的全栈笔记」,下面开始正文. 如果你是 ...
- Redis 基础数据类型重温
有一天你突然收到一条线上告警:Redis 内存使用率 85%.你吓坏了赶紧先进行扩容然后再去分析 big key.等你进行完这一系列操作之后老板叫你去复盘,期间你们聊到了业务的数据存储在 Redis ...
- 浅析Redis基础数据结构
Redis是一种内存数据库,所以可以很方便的直接基于内存中的数据结构,对外提供众多的接口,而这些接口实际上就是对不同的数据结构进行操作的算法,首先redis本身是一种key-value的数据库,对于v ...
- Redis 02: redis基础知识 + 5种数据结构 + 基础操作命令
Redis基础知识 1).测试redis服务的性能: redis-benchmark 2).查看redis服务是否正常运行: ping 如果正常---pong 3).查看redis服务器的统计信息: ...
- 1.基础: 万丈高楼平地起——Redis基础数据结构 学习记录
<Redis深度历险:核心原理和应用实践>1.基础: 万丈高楼平地起——Redis基础数据结构 学习记录http://naotu.baidu.com/file/b874e2624d3f37 ...
- Redis基础01-redis的数据结构
参考书:<redis设计与实现> Redis虽然底层是用C语言写的,但是底层的数据结构并不是直接使用C语言的数据结构,而是自己单独封装的数据结构: Redis的底层数据结构由,简单动态字符 ...
随机推荐
- session、闪现、请求扩展
session 除请求对象之外,还有一个session对象.它允许你在不同请求储存特定用户的信息.它是在Cookies的基础上实现的,并且对,Cookies进行密钥签名要使用会话,你需要设置一个密钥. ...
- 容器云平台No.8~kubernetes负载均衡之ingress-nginx
Ingress 是什么? Ingress 公开了从集群外部到集群内服务的 HTTP 和 HTTPS 路由. 流量路由由 Ingress 资源上定义的规则控制. 可以将 Ingress 配置为服务提供外 ...
- 八皇后问题(n-皇后问题)
JAVA 作为一道经典的题目,那必然要用经典的dfs来做 dfs:深度优先搜索----纵向搜索符合条件的内容,走到底时回到上一个路口再走到底再回去,套娃至结束. 条件:在一个n*n的国际棋盘上摆放n个 ...
- NodeJS沙箱逃逸&&vm
NodeJS沙箱逃逸 关于nodejs的沙箱 使用场景 在线代码编辑器 第三方js代码 jsonp,like百度搜索框 https://www.baidu.com/s?wd=nodejs&mi ...
- JDK动态代理详解
JDK动态代理是代理模式的一种,且只能代理接口.spring也有动态代理,称为CGLib,现在主要来看一下JDK动态代理是如何实现的? 一.介绍 JDK动态代理是有JDK提供的工具类Proxy实现的, ...
- Spring源码系列(四)--spring-aop是如何设计的
简介 spring-aop 用于生成动态代理类(底层是使用 JDK 动态代理或 cglib 来生成代理类),搭配 spring-bean 一起使用,可以使 AOP 更加解耦.方便.在实际项目中,spr ...
- ser 序列化的使用
2.序列化(serializers.Serializer) 1)序列化(正向查找) from rest_framework import serializers from users.models i ...
- Python面向对象基础变量
In [1]: class A: ...: NAME = 'A' # 类的直接下级作用域 叫做类变量 ...: def init(self, name): ...: self.name = name ...
- Error: Module did not self-register报错解决
最近在做node升级过程中发现拉起一个引用到底层c++ addon动态库时,报如下错误 [root@Test dynamiclibs]# node test-all.js module.js:664 ...
- SDK测试操作文档
准备所需材料 先把下列所需压缩包和文件传到虚拟机中. crypto-config压缩包存放order和peer节点所需要的证书文件(需要的是申请联盟链中的order和peer的证书文件) m2压缩包是 ...