数据分析03 /基于pandas的数据清洗、级联、合并
数据分析03 /基于pandas的数据清洗、级联、合并
1. 处理丢失的数据
两种丢失的数据:
种类
None:None是对象类型,type(None):NoneType
np.nan(NaN):是浮点型,type(np.nan):float
两种丢失数据的区别:
object类型比float在进行运算耗时
测试两种耗时时间:
import numpy as np
%timeit np.arange(1000,dtype=object).sum()
# 结果:
63.4 µs ± 1.02 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) %timeit np.arange(1000,dtype=float).sum()
# 结果:
6.45 µs ± 84.6 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
2. pandas处理空值操作
pandas中的None和NAN
df = DataFrame(np.random.randint(0,100,size=(8,6)))
df.iloc[2,3] = np.nan
df.iloc[5,5] = None # 在内部会强转成浮点型
df.iloc[5,3] = np.nan
df.iloc[7,2] = np.nan
df

对空值对应的行数据进行删除
# 实现:Series、DataFrame都可以用isnull()
df.isnull() # 判断哪些元素为空值
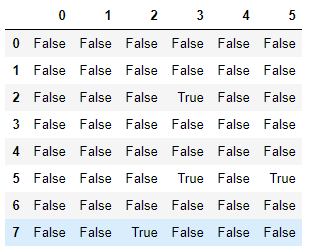
1.清洗有空值的行
# 查看哪些行存在空值数据 df.isnull().all(axis=1) # 一般结合notnull()使用
# 结果:
# 0 False
# 1 False
# 2 False
# 3 False
# 4 False
# 5 False
# 6 False
# 7 False
# dtype: bool df.isnull().any(axis=1)
# 结果:
# 0 False
# 1 False
# 2 True
# 3 False
# 4 False
# 5 True
# 6 False
# 7 True
# dtype: bool df.notnull().all(axis=1)
# 结果:
# 0 True
# 1 True
# 2 False
# 3 True
# 4 True
# 5 False
# 6 True
# 7 False
# dtype: bool # 清洗有空值的行
df.loc[df.notnull().all(axis=1)] # isnull() --> any:true表示其对应的行中存在空值
# notnull() --> all:False表示其对应的行中存在空值
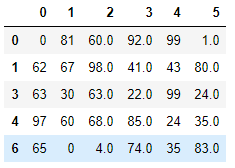
2.直接使用dropna函数过滤空值对应的行数据
# drop系列:行用axis=0,列用axis=1
df.dropna(axis=0)
将空值进行填充
# 任意填充
df.fillna(value=666) # 将空值都填充成value值 # 推荐使用空值近邻的值进行填充
df.fillna(method='ffill',axis=1) # axis轴向,method=ffill(向前),bfill(向后填充) # 如果发现还是有空值
df.fillna(method='bfill',axis=1).fillna(method='ffill',axis=1)

3. 数据清洗案例
需求:
- 数据说明:
- 数据是1个冷库的温度数据,1-7对应7个温度采集设备,1分钟采集一次。
- 数据处理目标:
- 用1-4对应的4个必须设备,通过建立冷库的温度场关系模型,预估出5-7对应的数据。
- 最后每个冷库中仅需放置4个设备,取代放置7个设备。
- f(1-4) --> y(5-7)
- 数据处理过程:
- 1、原始数据中有丢帧现象,需要做预处理;
- 2、matplotlib 绘图;
- 3、建立逻辑回归模型。
- 无标准答案,按个人理解操作即可,请把自己的操作过程以文字形式简单描述一下,谢谢配合。
- 测试数据为testData.xlsx
- 数据说明:
代码实现:
time none 1 2 3 4 none1 5 6 7 2019/1/27 17:00 -24.8 -18.2 -20.8 -18.8 NULL NULL NULL 2019/1/27 17:01 -23.5 -18.8 -20.5 -19.8 -15.2 -14.5 -16 2019/1/27 17:02 -23.2 -19.2 NULL NULL -13 NULL -14 2019/1/27 17:03 -22.8 -19.2 -20 -20.5 NULL -12.2 -9.8 2019/1/27 17:04 -23.2 -18.5 -20 -18.8 -10.2 -10.8 -8.8 # 预处理,将excel数据读取出来,将空列none、none1删除
df = pd.read_excel('./data/testData.xlsx')
df.drop(labels=['none','none1'],axis=1,inplace=True)
df # 删除空值所在的行,如果删除的代价较大,选择填充
df.dropna(axis=0) # 填充
new_df = df.fillna(axis=0,method='ffill').fillna(axis=0,method='bfill')
# 检车空值填充的情况
new_df.isnull().any(axis=0) # 结果:
# time False
# 1 False
# 2 False
# 3 False
# 4 False
# 5 False
# 6 False
# 7 False
# dtype: bool
4. 处理重复的数据
准备数据:
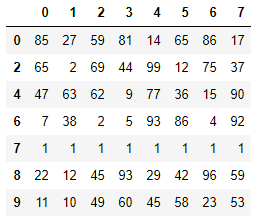
df = DataFrame(data=np.random.randint(0,100,size=(10,8)))
df.iloc[1] = [1,1,1,1,1,1,1,1]
df.iloc[3] = [1,1,1,1,1,1,1,1]
df.iloc[5] = [1,1,1,1,1,1,1,1]
df.iloc[7] = [1,1,1,1,1,1,1,1]
df
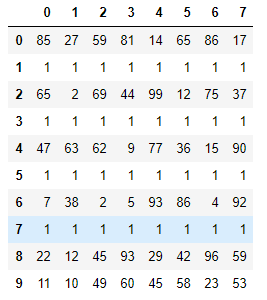
填充重复的数据
df.drop_duplicates(keep='last') # keep = 'first' 表示第一行保留
# keep = 'last' 表示最后一行保留
# keep = 'False' 表示全部都进行填充
5. 处理异常的数据
需求:自定义一个1000行3列(A,B,C)取值范围为0-1的数据源,然后将C列中的值大于其两倍标准差的异常值进行清洗
实现:
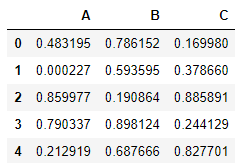
# 一个1000行3列(A,B,C)取值范围为0-1的数据源
df = DataFrame(data=np.random.random(size=(1000,3)),columns=['A','B','C'])
df.head()
# 计算两倍标准差
std_twice = df['C'].std() * 2 #判定异常值的条件
df.loc[~(df['C'] > std_twice)]
6. 级联
pd.concat:pandas使用pd.concat函数,与np.concatenate函数类似
参数说明:
objs
axis=0
keys
join='outer' / 'inner':表示的是级联的方式,outer会将所有的项进行级联(忽略匹配和不匹配),而inner只会将匹配的项级联到一起,不匹配的不级联
ignore_index=False
匹配级联
df1 = DataFrame({'employee':['Bobs','Linda','Bill'],
'group':['Accounting','Product','Marketing'],
'hire_date':[1998,2017,2018]})
pd.concat((df1,df1),axis=0)
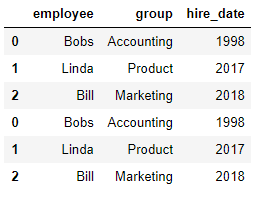
不匹配级联
- 不匹配指的是级联的维度的索引不一致。纵向级联时列索引不一致,横向级联时行索引不一致
- 有2种连接方式:
- 外连接:补NaN(默认模式)
- 内连接:只连接匹配的项
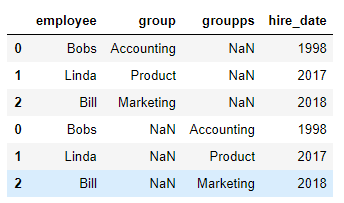
df2 = df1.copy()
df2.columns = ['employee','groupps','hire_date'] """
employee groupps hire_date
0 Bobs Accounting 1998
1 Linda Product 2017
2 Bill Marketing 2018
""" pd.concat((df1,df2),axis=0)
join
inner:只对可以匹配的项进行级联
outer:可以级联所有的项
pd.concat((df1,df2),axis=0,join='inner')
append函数的使用
append只可以进行纵向的级联
df1.append(df2)
7. 合并操作
合并概述:
- merge与concat的区别在于,merge需要依据某一共同列来进行合并
- 使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
- 注意每一列元素的顺序不要求一致
一对一合并
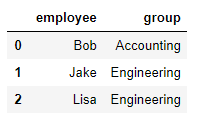
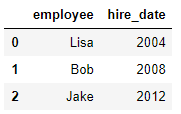
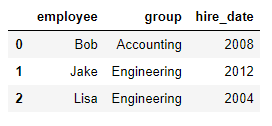
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering'],
}) df2 = DataFrame({'employee':['Lisa','Bob','Jake'],
'hire_date':[2004,2008,2012],
}) pd.merge(df1,df2,on='employee')
df1表格如下:
df2表格如下:
合并表格如下:
多对多合并
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering']}) df5 = DataFrame({'group':['Engineering','Engineering','HR'],
'supervisor':['Carly','Guido','Steve']
})
pd.merge(df1,df5,how='outer')
df1表格如下:

df5表格如下:
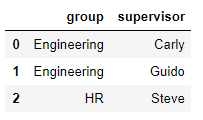
合并表格如下:

key的规范化
1.当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个列作为key,配合suffixes指定冲突列名
df1 = DataFrame({'employee':['Jack',"Summer","Steve"],
'group':['Accounting','Finance','Marketing']}) df2 = DataFrame({'employee':['Jack','Bob',"Jake"],
'hire_date':[2003,2009,2012],
'group':['Accounting','sell','ceo']}) pd.merge(df1,df2,on='group')
df1表格如下:

df2表格如下:

合并表格如下:

2.当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列
df1 = DataFrame({'employee':['Bobs','Linda','Bill'],
'group':['Accounting','Product','Marketing'],
'hire_date':[1998,2017,2018]}) df5 = DataFrame({'name':['Lisa','Bobs','Bill'],
'hire_dates':[1998,2016,2007]}) pd.merge(df1,df5,left_on='employee',right_on='name',how='outer')
df1表格如下:

df5表格如下:
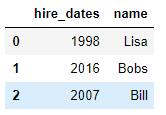
合并表格如下:

数据分析03 /基于pandas的数据清洗、级联、合并的更多相关文章
- 数据分析04 /基于pandas的DateFrame进行股票分析、双均线策略制定
数据分析04 /基于pandas的DateFrame进行股票分析.双均线策略制定 目录 数据分析04 /基于pandas的DateFrame进行股票分析.双均线策略制定 需求1:对茅台股票分析 需求2 ...
- 基于pandas python的美团某商家的评论销售数据分析(可视化)
基于pandas python的美团某商家的评论销售数据分析 第一篇 数据初步的统计 本文是该可视化系列的第二篇 第三篇 数据中的评论数据用于自然语言处理 导入相关库 from pyecharts i ...
- Python数据分析工具:Pandas之Series
Python数据分析工具:Pandas之Series Pandas概述Pandas是Python的一个数据分析包,该工具为解决数据分析任务而创建.Pandas纳入大量库和标准数据模型,提供高效的操作数 ...
- 【转载】使用pandas进行数据清洗
使用pandas进行数据清洗 本文转载自:蓝鲸的网站分析笔记 原文链接:使用python进行数据清洗 目录: 数据表中的重复值 duplicated() drop_duplicated() 数据表中的 ...
- 《数据分析实战:基于EXCEL和SPSS系列工具的实践》一1.4 数据分析的流程
本节书摘来华章计算机<数据分析实战:基于EXCEL和SPSS系列工具的实践>一书中的第1章 ,第1.4节,纪贺元 著 更多章节内容可以访问云栖社区"华章计算机"公众号查 ...
- 数据分析:基于Python的自定义文件格式转换系统
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- python – 基于pandas中的列中的值从DataFrame中选择行
如何从基于pandas中某些列的值的DataFrame中选择行?在SQL中我将使用: select * from table where colume_name = some_value. 我试图看看 ...
- Python数据分析入门之pandas基础总结
Pandas--"大熊猫"基础 Series Series: pandas的长枪(数据表中的一列或一行,观测向量,一维数组...) Series1 = pd.Series(np.r ...
- OpenCV中基于Haar特征和级联分类器的人脸检测
使用机器学习的方法进行人脸检测的第一步需要训练人脸分类器,这是一个耗时耗力的过程,需要收集大量的正负样本,并且样本质量的好坏对结果影响巨大,如果样本没有处理好,再优秀的机器学习分类算法都是零. 今年3 ...
随机推荐
- Eureka加了secsecurity后注册失败
报错信息: com.netflix.discovery.shared.transport.TransportException: Cannot execute request on any known ...
- DML_The OUTPUT Clause
DML_The OUTPUT Clause /**/ ------------------------------------------------------------------------- ...
- Jmeter基础003----Jmeter组件之测试计划和线程组
一.测试计划 1.界面展示 测试计划是测试脚本的容器,主要是对测试脚本做总体设置.它定义了测试要执行什么,怎么执行(执行的).其界面如下图所示: 2.设置用户定义变量 在测试计划中定义的变量是在整 ...
- vulstack红队评估(四)
一.环境搭建: ①根据作者公开的靶机信息整理 虚拟机密码: ubuntu: ubuntu:ubuntu win7: douser:Dotest123 Win2008 DC: administr ...
- 基于node的前端项目编译时内存溢出问题
解决方法: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory JavaScript堆内存不足,这里说的 Jav ...
- Java工程中各种带有O的对象分类笔记
在Java工程里面,我们总会碰到各种不同的带有O的对象, 对于一个小白来说,经常会混淆这些对象的使用场景,所以在这里mark一下,让自己的代码更加规范,但这个也是Java被诟病的地方,不同的业务需要给 ...
- SpringCloud 入门(三)
前文我们介绍了简单的创建一个客户端,并介绍了它是如何提供服务的,接下来介绍它的另外一个组件:zuul. zuul 提供了微服务的网关功能,通过它提供的接口,可以转发不同的服务,可以当作一个中转站. 搭 ...
- 前端笔记(关于解决打包时报node-sass错误的问题)
这个问题之前反复出现,试过重新从其他同事将node_modules拿过来用,但是过了几天又出同样的问题 去网上百度了好久,大多数都说是node-sass重装一下就行.可是我这边卸载都无法卸载,何谈重装 ...
- String类基础知识
1.String类的构造方法 (1)String(String original) //把字符串数据封装成字符串对象 (2)String(char[] c) //把字符数组的数据封装成字符串对象 ...
- 动态追踪技术之SystemTap
SystemTap SystemTap是一个深入检查Linux系统活动的工具,使用该工具编写一些简单的代码就可以轻松的提取应用或内核的运行数据,以诊断复杂的性能或者功能问题.有了它,开发者不再需要重编 ...