Debezium实现多数据源迁移(一)
背景:
某公司有三个数据库,分别为MySql、Oracle和PostgreSql。原有业务的数据都是来自于这三个DB,此处委托将原有的三个数据库整合成一个Mysql。
要求:
1.不影响原有系统的继续使用。
2.原有数据迁移至新的数据库。
3.新的Mysql中的同一张表的数据可能来自不同的数据库,举个例子:PostgreSql:User(name),Oracle:User(age)——》Mysql:User(name,age)。
架构:
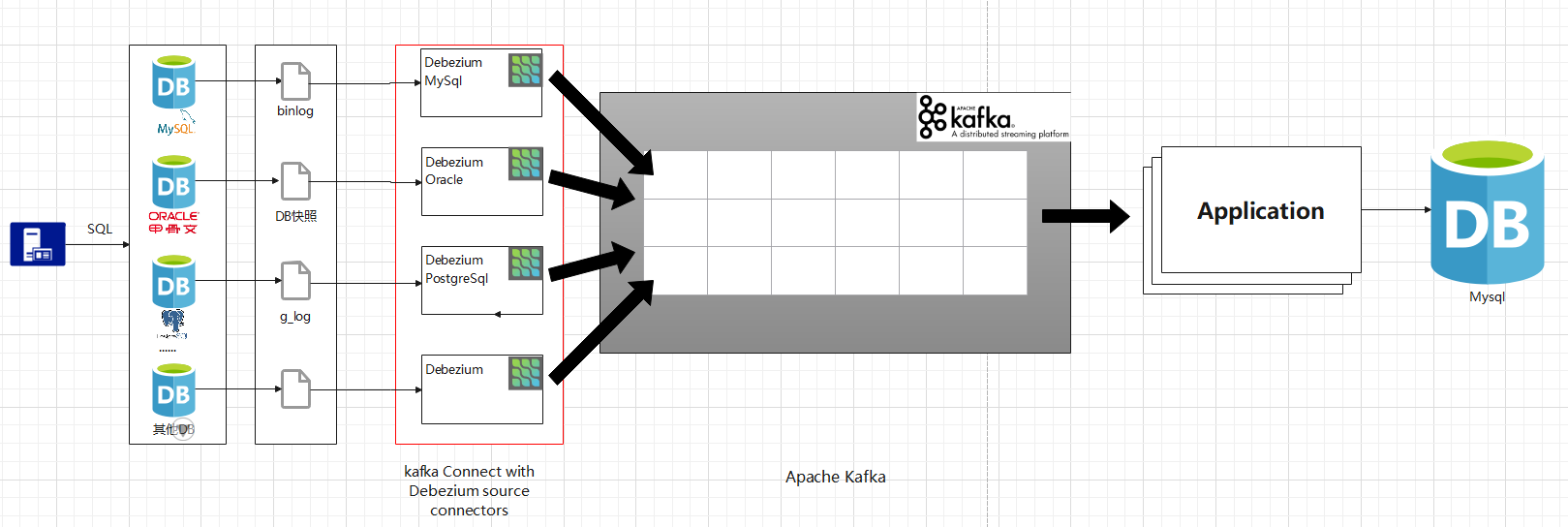
(涉及内部服务器,由本地简单搭建演示记录这一过程)
一、基于Docker搭建Debezium环境
(1).搭建zookeeper
docker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper
(2).搭建kafka
docker run -d --name kafka -p 9092:9092 -p 8083:8083 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=<IP地址>:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT:// <IP地址>:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -v C:\data_share:/home/data wurstmeister/kafka
tips:
<IP地址>全文对应同一个
1. 留8083端口为后续kafka-connect暴力Api使用。
2. -v 预留数据卷,共享kafka-connect扩展,方便上传扩展包。
3. <IP地址>保证Api可访问,zookeeper和kafka间有IP认证。如:zk和kafka用服务器内网IP,但当使用外网IP访问kafka时会认证不过,见zk官网。
(3).准备kafka-connect集群启动文件
修改/opt/kafka/config/connect-distributed.properties
#kafka集群
bootstrap.servers=<IP地址1>:9092,<IPd地址2>:9092
#Api的端口
rest.port=8083
#用于其他worker连接
rest.advertised.host.name=<IP地址>
rest.advertised.port=8083
#消息只要payload,<选择性设置>
key.converter.schemas.enable=false
value.converter.schemas.enable=false
#kafka-connect的扩展路径,指向kafka预留的 -v C:\data_share:/home/data
plugin.path=/home/data
(4).添加kafka-connect的Debezium扩展包 (以Mysql为例)
MySql本地版本5.7+,下载MySQLConnector plug-in,解压缩到为kafka预留的数据卷映射地址 C:\data_share
https://debezium.io/releases/1.5/


(5). 启动connect集群
./opt/kafka/bin/connect-distributed.sh ../config/connect-distributed.properties
检测是否成功:
./kafka-topic.sh --bootstrap-server <IP地址>:9092 --list

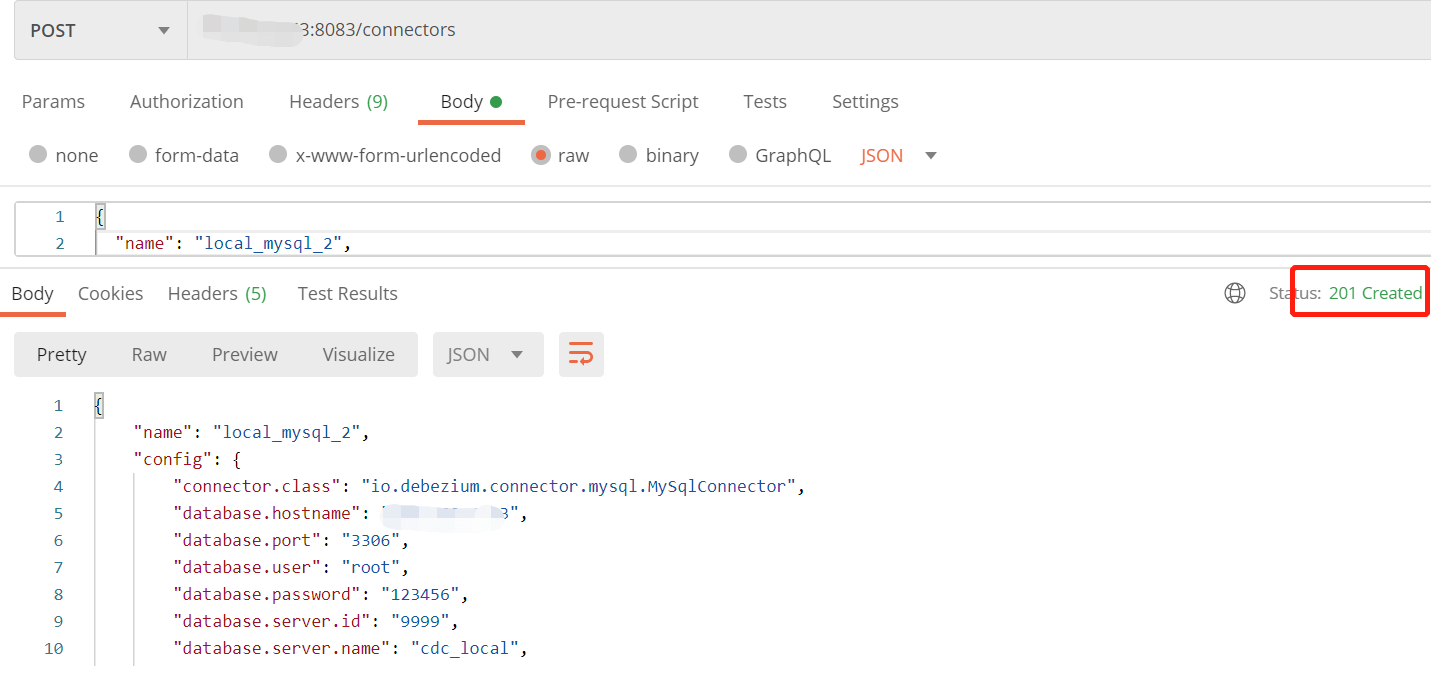
(6).调用Connect 配置连接属性
使用Postman 发送Post请求创建Connect 路径 <IP地址>:8083/connectors
(如有多个数据库源,创建多个Connect,保证name唯一)
请求体Json:
{
"name": "local_mysql",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "127.0.0.1",
"database.port": "3306",
"database.user": "root",
"database.password": "123456",
"database.server.id": "9999",
"database.server.name": "cdc_local",
"database.whitelist": "inventory",
"database.history.kafka.bootstrap.servers": "<IP地址>:9092",
"database.history.kafka.topic": "history.local.inventory",
"include.schema.changes": "true"
}}
#name 创建的连接名
#config 配置信息
#connector.class 连接器类
#database.hostname 需要捕获的数据库地址
#database.port 数据库端口
#database.server.id 服务id(保证唯一)
#database.server.name 服务名,会加在topic前面 如下:cdc_local.inventory.orders
#database.whitelist 监听的数据库 ","分割
#database.history.kafka.bootstrap.servers kafka地址
#database.history.kafka.topic 连接器将使用此代理(向其发送事件的代理)和主题名称在Kafka中存储数据库架构的历史记录。重新启动后,连接器将恢复binlog连接器应开始读取的时间点上存在的数据库的架构
#include.schema.changes 是否包含表的改变
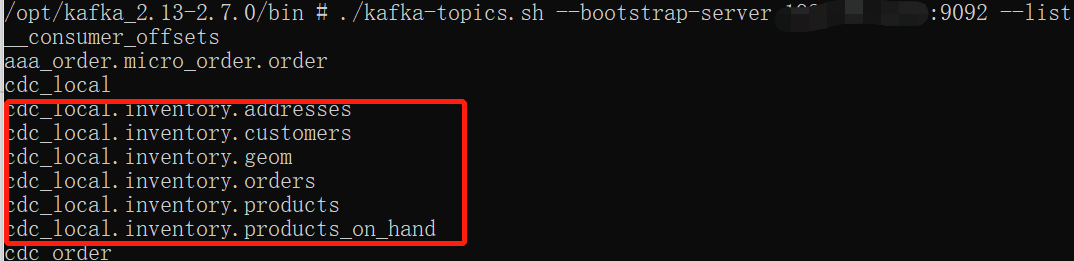
查看kafka-topic.sh
./kafka-topics.sh --bootstrap-server <IP地址>:9092 --list
Debezium实现多数据源迁移(一)的更多相关文章
- 激活、复制、使用R/3标准数据源(RSA5、RSA6、RSA1)
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- confluence6.3.1部署+数据迁移
目录: 环境准备 搭建方法 数据迁移 搭建过程中的bug 1,confluence部署 1.1,环境准备 Java:jdk1.8 mysql: 数据库编码规则选择utf8 -- UTF-8 Unico ...
- weblogic迁移总结
weblogic使用的数据库时DB2 1. 图形化安装weblogic和域,或者静默安装. 2. 查看环境变量env并修改,修改系统默认语言(根据实际情况) 3. 修改weblogic页面打开较慢问题 ...
- Amazon Redshift数据迁移到MaxCompute
Amazon Redshift数据迁移到MaxCompute Amazon Redshift 中的数据迁移到MaxCompute中经常需要先卸载到S3中,再到阿里云对象存储OSS中,大数据计算服务Ma ...
- MYSQL复制
今天我们聊聊复制,复制对于mysql的重要性不言而喻,mysql集群的负载均衡,读写分离和高可用都是基于复制实现.下文主要从4个方面展开,mysql的异步复制,半同步复制和并行复制,最后会简单聊下第三 ...
- 【MySQL】主备复制
复制对于mysql的重要性不言而喻,mysql集群的负载均衡,读写分离和高可用都是基于复制实现.下文主要从4个方面展开,mysql的异步复制,半同步复制和并行复制,最后会简单聊下第三方复制工具.由于生 ...
- BW:如何加载和生成自定义的层次结构,在不使用平面文件的SAP业务信息仓库
介绍 通常情况下,报告需要在一个类似树的结构来显示数据.通过启用此特性在SAP BW层次结构.高级数据显示的层次结构的顶层节点.更详细的数据可以向下钻取到的层次结构中的下级节点的可视化. 考虑一个例子 ...
- web中间件切换(was切tomcat)
一.数据源迁移: ①数据源配置在web容器还是在项目本身? 根据开发与生产分离原则选择配置到web容器,以免开发泄露数据库密码. ②数据库密码加密 原先was的数据源直接在console控制,密码是密 ...
- pgloader 方便的数据迁移工具
pgloader 是一个支持多种数据源迁移到pg 数据库的工具,高性能,使用灵活同时作者 也提供了docker 版本的镜像,今年3月份使用此工具的时候,发现好久都没更新了,但是 最近作者有了新版本的发 ...
随机推荐
- 洛谷 P5837 [USACO19DEC]Milk Pumping G (单源最短路,dijkstra)
题意:有一\(n\)个点,\(m\)条边的双向图,每条边都有花费和流量,求从\(1\)~\(n\)的路径中,求\(max\frac{min(f)}{\sum c}\). 题解:对于c,一定是单源最短路 ...
- 002、Python中json字符串与字典转换
1.测试用例文件TestCase.xlsx 2.编写Python文件进行读取 #!/usr/bin/env python # -*- coding:utf-8 -*- import time impo ...
- CF1466-D. 13th Labour of Heracles
CF1466-D. 13th Labour of Heracles 题意: 给出一个由\(n\)个点构成的树,每个点都有一个权值.现在你可以用\(k,k\subset\)\([1, n]\)个颜色来给 ...
- codeforce 849B
B. Tell Your World time limit per test 1 second memory limit per test 256 megabytes input standard i ...
- 2019牛客多校第五场C generator 2(BSGS)题解
题意: 传送门 已知递推公式\(x_i = a*x_{i - 1} + b\mod p\),\(p\)是素数,已知\(x_0,a,b,p\),给出一个\(n\)和\(v\),问你满足\(x_i = v ...
- 杭电多校HDU 6601 Keen On Everything But Triangle(主席树)题解
题意: 有\(n\)根长度不一的棍子,q次询问,求\([L,R]\)区间的棍子所能组成的周长最长的三角形.棍长\(\in [1, 1e9]\),n\(\in [1, 1e5]\). 思路: 由于不构成 ...
- 【算法】KMP算法
简介 KMP算法由 Knuth-Morris-Pratt 三位科学家提出,可用于在一个 文本串 中寻找某 模式串 存在的位置. 本算法可以有效降低在一个 文本串 中寻找某 模式串 过程的时间复杂度.( ...
- 产品经理进阶:如何用UML的顺序图表达思想?
当大家把UML建模语言下的各图形都有所了解后会发现,通过这些图可以全面的.立体的从各个角度表达产品,让产品的表达变得更丰富.更形象. "手中无剑.心中有剑",大多数产品人并不了解计 ...
- RT-Thread学习笔记2-互斥量与信号量
目录 1. 临界区保护 1.1 方法一:关闭系统调度保护临界区 1.2 方法二:互斥特性保护临界区 2. 信号量 2.1 信号量的定义 2.2 信号量的操作 3. 生产者.消费者问题 4. 互斥量 4 ...
- 为什么 Koa 的官方文档那么丑呀?
为什么 Koa 的官方文档那么丑呀? koa.js https://koajs.com/ 代码高亮 # $ nvm install 7, node.js v7.x.x+ $ yarn add koa ...