Graph Explore的使用介绍
我在Graph API开发中用的最多的测试工具就是Graph Explore,这个是微软开发的网页版的Graph API的测试工具,能满足我大部分需求。
访问网址是:Graph Explorer - Microsoft Graph
基本界面如下:
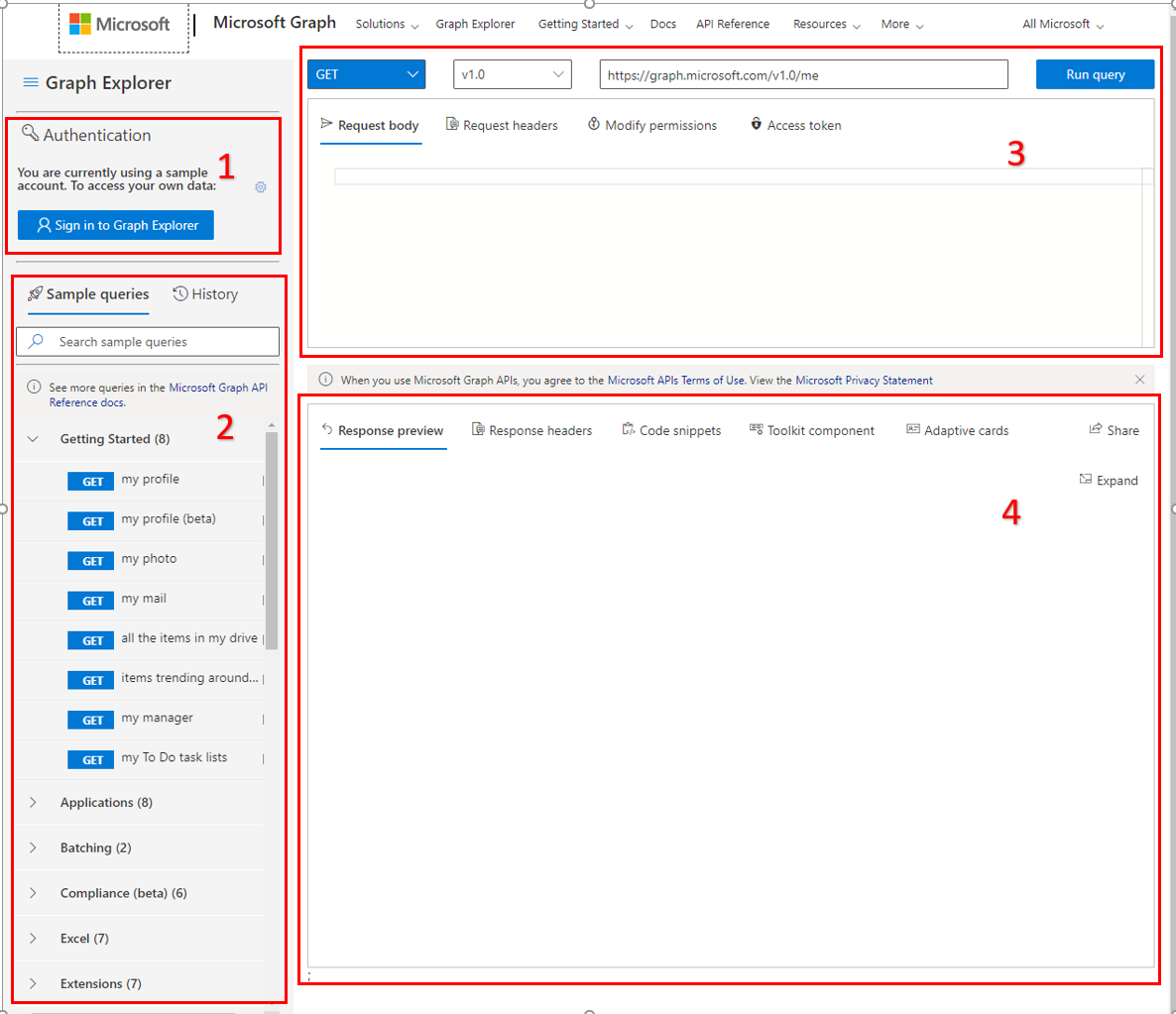
基本上分成4个区域
1.用户登录
2.Graph API查询的样例和查询历史
3.用户查询
4.返回结果
下面来一个个说明一下具体的作用。
1.用户登录
你可以用自己申请到的office 365开发者账号登录。登录后,点击登录名右边的齿轮图标,可以进行下面的一些设置。第一项会引导你去Office 365的网站导入一些测试用的用户、文档等,如果你的Office 365网站没有任何数据,使用沙箱是非常好的一个办法。第三项是设置权限,你可以在这里提前授权你需要的权限,如果没做也没关系,后面在每一条请求的时候,也可以做类似的操作。
2.查询样例和历史
这里提供了很多Graph API的查询样例,双击后就可以直接显示到右边的查询窗口,非常方便。但是这里提供的大多是最基本的一些查询,更多的还是需要自己在查询窗口自行创建。
历史tab下面可以保存你过去30天所有的查询记录,包括成功的和失败的。你也可以导出和删除所有记录。
下面来说一说最重要的两个部分。
3. 用户查询。
首先是选择HTTP请求的方法,一共有5个方法可选。
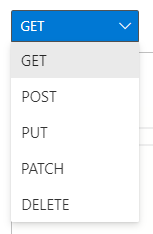
然后选择Graph API的版本,大部分情况下使用1.0就可以了。有的查询命令只在beta里面有,但是微软官方说在beta中的查询命令,可能随着新版本的发布会进入到1.0中,然后从beta里面删除,所以开发中还是尽量使用1.0版本,以免程序后续查询失败。
查询命令输入,这里测试一条查询,得到我的Office 365测试环境中所有的用户数。返回结果一会儿再看。

Request Body里面是使用Post,Put,Patch,Delete方法时,输入一些查询条件。比如下面示例,是在Office 365中新增一个用户。Request body里面就是这个用户的一些详细信息,通常是JSON格式的。

Request Header里面是填写HTTP request headers。
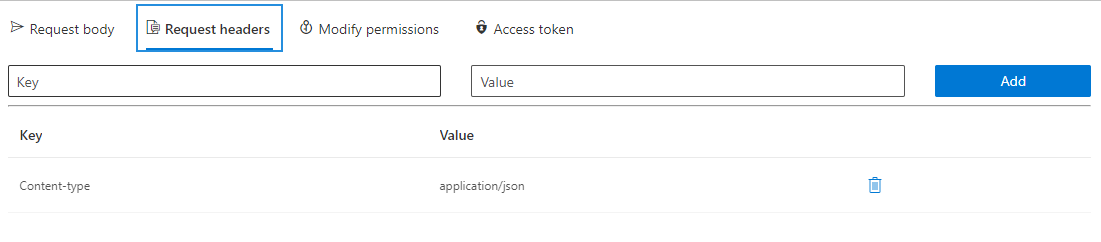
当你的查询请求返回401未授权结果时,就可以到Modify permissions下面检查你的权限。如果没授予权限的时候,status栏的consent会是一个蓝色按钮,按下即可。

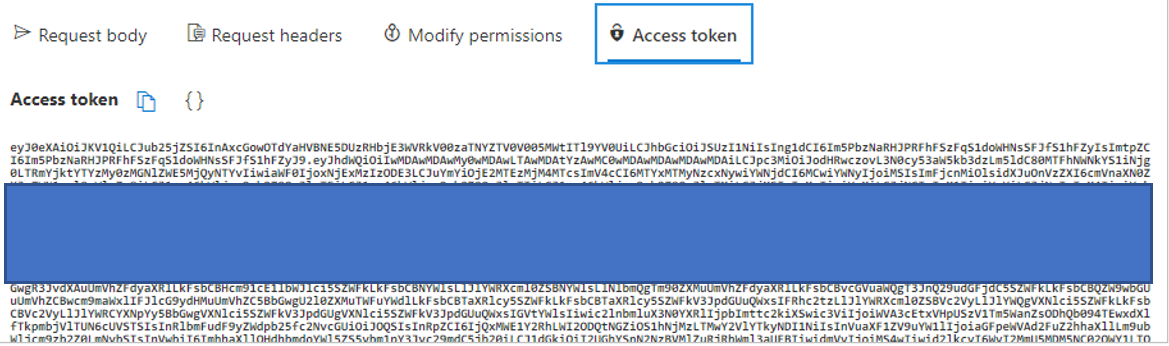
最后的Access Token,你可以复制它,用于测试,也可以点击大括号按钮,去jwt.ms网站查看token的具体内容。
4. 查询结果
首先最上面是查询返回结果的状态,常见的200,401,404.
Response preview。可以看到之前查询的返回结果是23.
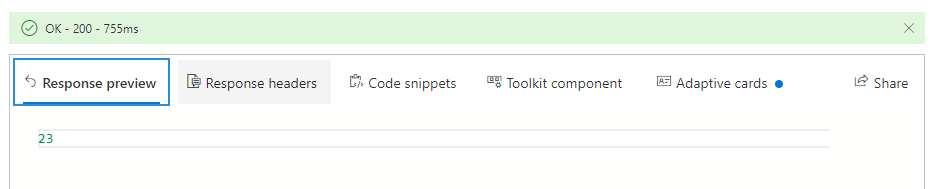
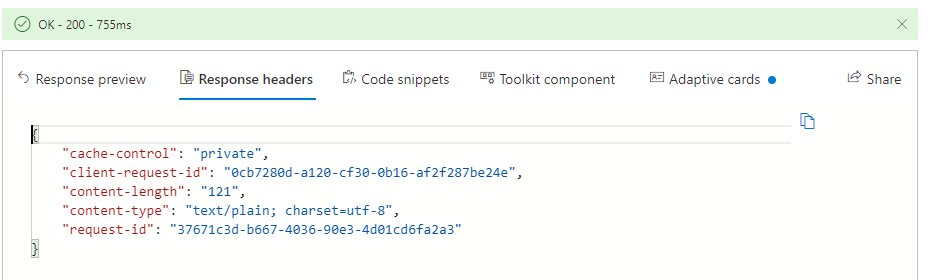
Response headers
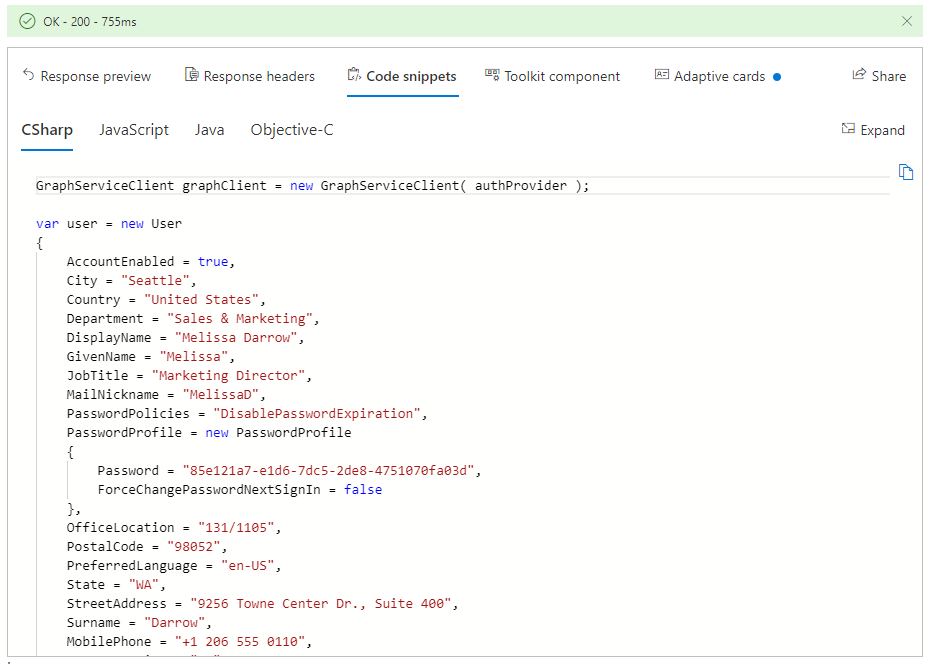
Code snippets,这里是对开发人员最有用的部分了。根据你的查询,这里会给出相应的C#,JavaScript的代码片段。但是要注意的是,不是任何查询都给出代码片段的,个人感觉应该是最常用的一些查询会有代码片段。
Toolkit component 和 Adaptive cards也不是所有查询都会有显示结果。在开发中用到的机会也不多。

以上就是Graph Explore使用介绍了,以后有机会再写写用Postman进行查询测试的方法。
Graph Explore的使用介绍的更多相关文章
- Microsoft Graph API -----起题 Graph API
最近因为工作需要,接触学习使用了Microsoft Graph API.在看完Microsoft的Graph官方文档之后,也做了一些简单的案例,在Stack Overflow上做过一些回答.整体来说, ...
- Graph database_neo4j 底层存储结构分析(1)
1 neo4j 中节点和关系的物理存储模型 1.1 neo4j存储模型 The node records contain only a pointer to their first pr ...
- Paddle Graph Learning (PGL)图学习之图游走类模型[系列四]
Paddle Graph Learning (PGL)图学习之图游走类模型[系列四] 更多详情参考:Paddle Graph Learning 图学习之图游走类模型[系列四] https://aist ...
- Facebook 爬虫
title: Facebook 爬虫 tags: [python3, facebook, scrapy, splash, 爬虫] date: 2018-06-02 09:42:06 categorie ...
- 学习python库:elasticsearch-py
一.介绍 elasticsearch-py是一个官方提供的low-level的elasticsearch python客户端库.为什么说它是一个low-level的客户端库呢?因为它只是对elasti ...
- 谱聚类(spectral clustering)原理总结
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也 ...
- C/C++ 开源库及示例代码
C/C++ 开源库及示例代码 Table of Contents 说明 1 综合性的库 2 数据结构 & 算法 2.1 容器 2.1.1 标准容器 2.1.2 Lockfree 的容器 2.1 ...
- git学习 #2:git基本操作
本文出自 http://blog.csdn.net/shuangde800 ------------------------------------------------------------ ...
- 谱聚类(Spectral Clustring)原理
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也 ...
随机推荐
- react第X单元(redux)
第X单元(redux) #课程目标 理解redux解决的问题,理解redux的工作原理 熟练掌握redux的api 熟练掌握redux和react组件之间的通信(react-redux) 把redux ...
- Eureka系列(三)获取服务Client端具体实现
获取服务Client 端流程 我们先看下面这张图片,这张图片简单描述了下我们Client是如何获取到Server已续约实例信息的流程: 从图片中我们可以知晓大致流程就是Client会自己开启一个 ...
- Python手把手教程之用户输入input函数
函数input() 函数 input() 让程序暂停运行,等待用户输入一些文本.获取用户输入后,Python将其存储在一个变量中,以方便你使用. 例如,下面的程序让用户输入一些文本,再将这些文本呈现给 ...
- 歌曲网站,教你爬取 mp3 和 lyric
从歌曲网站,获取音频和歌词的流程: 1, 输入歌曲名,查找网站中存在的歌曲 id 2, 拿歌曲 id 下载歌词 lyric 简单的 url 拼接 3, 拿歌曲 id 下载音频 mp3 先用一个 POS ...
- web项目报错 无法解析,丢失包 是缺少本地运行jre
1.通过build path 添加add Library 2.添加jre
- 远程调用post请求和get请求
/** * 获取用户 */ @RequestMapping("getUserMassages") public Map<String,Object> getuserMa ...
- 【转】PANDAS 数据合并与重塑(concat篇)
转自:http://blog.csdn.net/stevenkwong/article/details/52528616 1 concat concat函数是在pandas底下的方法,可以将数据根据不 ...
- JVM个人总结一
看了深入理解JAVA虚拟机已经有一段时间了 发现很多东西如果不总结 脑子里总是没有一条线贯穿起来,也比较模糊混乱,所以还是有必要利用逻辑思维图总结下. JVM看了下 大致比较重要的分内存区域划分 ...
- spring boot 部署到tomcat
网上很多文章描述过,当我按步骤做时会抛各种错误,最后记录下我的做法(成功发布到本地 Tomcat9 ): 1.将项目的启动类Application.java继承SpringBootServletIni ...
- vscode 安装与配置
vscode 安装与配置 安装 安装 vscode 从官网 [https://code.visualstudio.com/Download] 下载速度奇慢,可以找到下载的网址,如下图所示,将其中红色框 ...