在单机Hadoop上面增加Slave
之前的文章已经介绍了搭建单机Hadoop, HBase, Hive, Spark的方式:link
现在希望在单机的基础上,加一个slave。
首先需要加上信任关系,加信任关系的方式,见前一篇文章:link
把05和06这两台机器,分别和对方添加上信任关系。
把05上面的目录 /home/work/data/installed/hadoop-2.7.3/ 拷贝到06机器,
把 etc/hadoop 里面的 IP 10.117.146.12 都改成 11
然后06机器 要安装 jumbo 和 Java1.8
安装好之后,JAVA_HOME应该和05机器上配置的一样:
export JAVA_HOME=/home/work/.jumbo/opt/sun-java8
另外要创建这个目录 /home/work/data/hadoop/dfs
然后启动下面这些服务:
首先格式化hdfs:
./bin/hdfs namenode -format myclustername // :: INFO util.ExitUtil: Exiting with status
在slave上面要部署的服务有 datanode, node_manager(没有namenode)
启动datanode
$ ./sbin/hadoop-daemon.sh --script hdfs start datanode
starting datanode, logging to /home/work/data/installed/hadoop-2.7./logs/hadoop-work-datanode-gzns-ecom-baiduhui--m42n06.gzns.baidu.com.out
启动node manager
$ ./sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /home/work/data/installed/hadoop-2.7./logs/yarn-work-nodemanager-gzns-ecom-baiduhui--m42n06.gzns.baidu.com.out
在master上面增加slave (etc/hadoop/slaves) :
localhost
10.117.146.11
然后看下master的几个管理平台:
Overview: http://10.117.146.12:8305
Yarn: http://10.117.146.12:8320
Job History: http://10.117.146.12:8332/jobhistory
Spark:http://10.117.146.12:8340/
上网搜了一个,用root帐号将两台机器的 /etc/hosts都改成了
127.0.0.1 localhost.localdomain localhost
10.117.146.12 master.Hadoop
10.117.146.11 slave1.Hadoop
以下一样:
127.0.0.1 localhost.localdomain localhost
10.117.146.12 master.Hadoop
10.117.146.11 slave1.Hadoop
然后把 etc/hadoop/slaves里的内容都改成:
slave1.Hadoop
加了一个文件 etc/hadoop/masters
master.Hadoop
但是,还是始终发现master和slave是各自独立的,然后在slave上起了namenode 和 yarn之后,slave就知看到自己一个live node了。
看了一下,把所有的服务都停掉,看是否能用 ./sbin/start-all.sh ,跑了一下,发现有提示输入 work@localhost密码的,然后grep了一下localhost,发现在core-site.xml有localhost的配置:
<name>fs.defaultFS</name>
<value>hdfs://localhost:8390</value>
感觉需要把slave的这里也改掉。然后试了一下,把master和slave的这个地方都改成如下:
<name>fs.defaultFS</name>
<value>hdfs://master.Hadoop:8390</value>
然后,在slave启动datanode报错,错误日志:
-- ::, WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/home/work/data/hadoop/dfs/data/
java.io.IOException: Incompatible clusterIDs in /home/work/data/hadoop/dfs/data: namenode clusterID = CID-9808571a-21c3-4aeb-a114-19b99b4722d2; datanode clusterID = CID-c2a59c40-0a4b-4aba-bbab-31ec15b8d64d
貌似是namenode和datanode冲突了。用 rm -rf /home/work/data/hadoop/dfs/data/ 把data node目录整体删掉。
重新启动master上面的所有服务。
然后在slave上面重新启动datanode:
./sbin/hadoop-daemon.sh --script hdfs start datanode 在日志里能看到heartbeat的内容,看起来通信成功了。
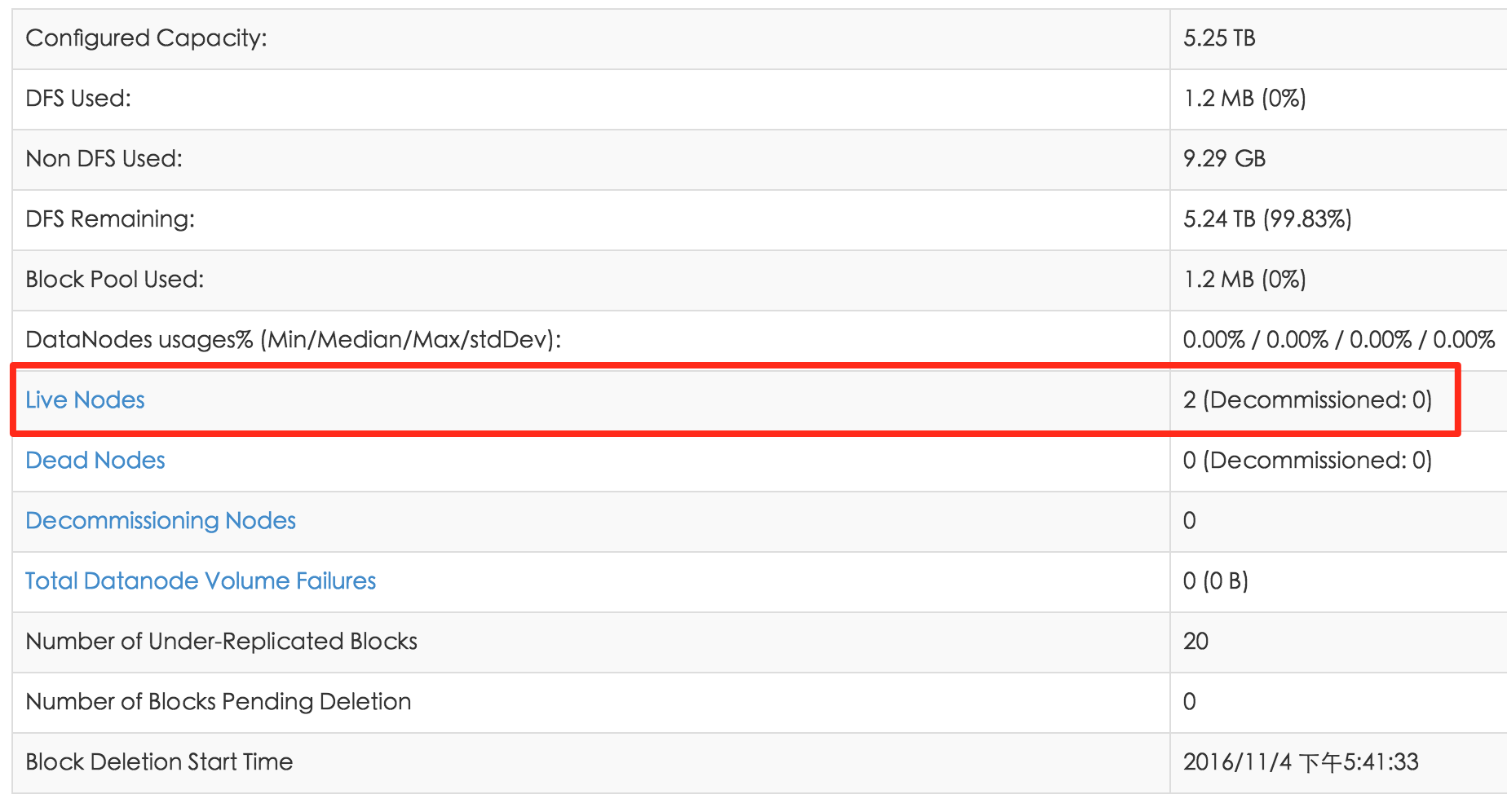
再打开master的管理界面:
http://10.117.146.12:8305/dfshealth.html 能够看到两台node了:
现在再把slave的node manager也启动:
$ ./sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /home/work/data/installed/hadoop-2.7./logs/yarn-work-nodemanager-gzns-ecom-baiduhui--m42n06.gzns.baidu.com.out
然后观察下管理界面的各个指标。
发现yarn里面还是只看到一台机器。感觉还是配置的地方有问题。
首先master和slave的配置应该是一样的。改了如下的地方:
hdfs-site.xml
<property>
<name>dfs.namenode.http-address</name>
<value>master.Hadoop:</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master.Hadoop:</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>master.Hadoop:</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master.Hadoop:</value>
</property>
yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master.Hadoop</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master.Hadoop:</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master.Hadoop:8325/jobhistory/logs/</value>
</property>
然后重启master和slave的所有服务。
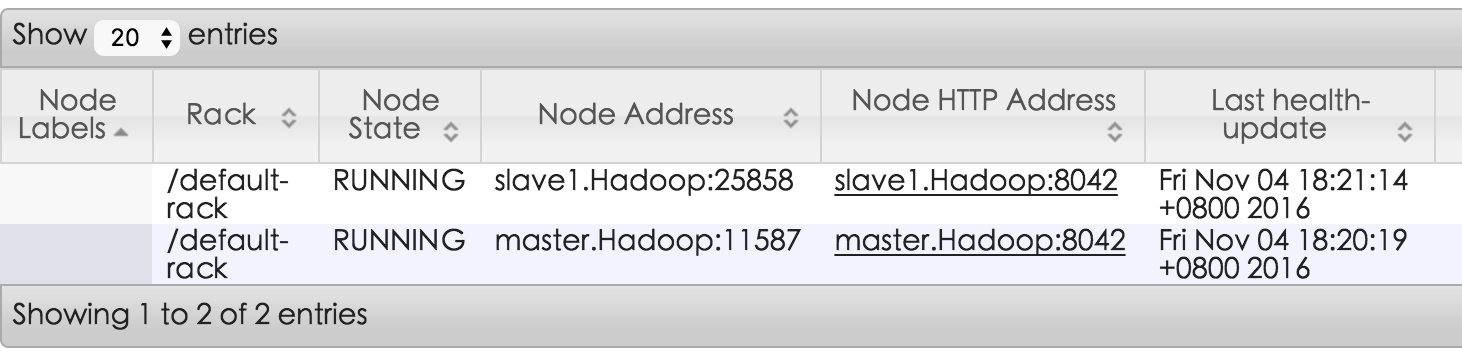
启动完成之后,在以上各个管理界面能够正常看到两个节点啦。
http://10.117.146.12:8305/dfshealth.html#tab-overview
http://10.117.146.12:8332/jobhistory
http://10.117.146.12:8320/cluster/nodes
跑一条命令试试:
$ ./bin/hadoop jar ./share/hadoop/tools/lib/hadoop-streaming-2.7..jar -input /input -output /output -mapper cat -reducer wc
packageJobJar: [/tmp/hadoop-unjar8343786587698780884/] [] /tmp/streamjob8627318309812657341.jar tmpDir=null
// :: INFO client.RMProxy: Connecting to ResourceManager at master.Hadoop/10.117.146.12:
// :: INFO client.RMProxy: Connecting to ResourceManager at master.Hadoop/10.117.146.12:
// :: ERROR streaming.StreamJob: Error Launching job : Output directory hdfs://master.Hadoop:8390/output already exists
Streaming Command Failed!
发现失败。要删除output目录,但是像以前那样删不行,要加上hdfs的前缀:
$ ./bin/hadoop fs -rm output
rm: `output': No such file or directory $ ./bin/hadoop fs -rm -r hdfs://master.Hadoop:8390/output
// :: INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = minutes, Emptier interval = minutes.
Deleted hdfs://master.Hadoop:8390/output
然后重新跑:
$ ./bin/hadoop jar ./share/hadoop/tools/lib/hadoop-streaming-2.7..jar -input /input -output /output -mapper cat -reducer wc 命令成功 $ ./bin/hadoop fs -ls hdfs://master.Hadoop:8390/output
Found items
-rw-r--r-- work supergroup -- : hdfs://master.Hadoop:8390/output/_SUCCESS
-rw-r--r-- work supergroup -- : hdfs://master.Hadoop:8390/output/part-00000 $ ./bin/hadoop fs -cat hdfs://master.Hadoop:8390/output/part-00000
得到了结果。也不太看的出来是哪台机器上跑的。
在单机Hadoop上面增加Slave的更多相关文章
- 单机Hadoop搭建
通过一段时间的学习,我在我的centos上安装了单机hadoop,如果这对你有帮助,就进来探讨学习一下 Hadoop伪分布式配置 Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以 ...
- Hadoop,master和slave简单的分布式搭建
搭建过程中配置免密钥登录为了以后方便使用 [提醒]安装Hadoop中会遇到新建文件夹,配置路径等问题,这个不能生搬硬套,要使用自己配置的路径,灵活使用. Hadoop的部署配置文件在http://bl ...
- 单机Hadoop的安装与使用
第一步:安装操作系统并创建Hadoop用户 OS:RHEL6.5 [root@hadoop ~]# useradd hadoop [root@hadoop ~]# passwd hadoop 第二步: ...
- Centos 7 配置单机Hadoop
Centos 7 配置单机Hadoop 2018年10月11日 09:48:13 GT_Stone 阅读数:82 系统镜像:CentuOS-7-x86_64-Everything-1708 Jav ...
- Hadoop单机Hadoop测试环境搭建
Hadoop单机Hadoop测试环境搭建: 1. 安装jdk,并配置环境变量,配置ssh免密码登录 2. 下载安装包hadoop-2.7.3.tar.gz 3. 配置/etc/hosts 127.0. ...
- Hadoop 添加删除Slave
Hadoop 添加删除Slave @(Hadoop) 在hdfs-site.xml文件中添加如下配置: <property> <name>dfs.hosts</name& ...
- 1、大数据 Hadoop配置和单机Hadoop系统配置
#查看服务器ip ip add #设置主机名称 hostnamectl set-hostname master bash #查看 hostname #绑定ip vi /etc/hosts 添加 服务器 ...
- 【3】测试搭建成功的单机hadoop环境
1.关闭防火墙service iptables stop,(已经设置开机关闭的忽略) 2.进入hadoop目录,修改hadoop配置文件(4个) core-site.xml(核心配置,fs.defau ...
- 安装单机Hadoop系统(完整版)——Mac
在这个阴雨绵绵的下午,没有睡午觉的我带着一双惺忪的眼睛坐在了电脑前,泡上清茶,摸摸已是略显油光的额头(笑cry),,奋斗啊啊啊啊!!%>_<% 1.课程回顾. 1.1 Hadoop系统运行 ...
随机推荐
- PowerDesigner(二)-项目和框架矩阵(转)
项目和框架矩阵 项目是PowerDesigner 15的新概念,通过项目系统分析/设计人员可以对模型以及各类文档进行分组.项目也可以包含框架矩阵,以表格的形式体现各个模型之间的关系. 项目和框架矩阵解 ...
- HTML5中表单验证的8种方法(转)
在深人探讨表单验证之前,让我们先思考一下表单验证的真实含义.就其核心而言,表单验证是一套系统,它为终端用户检测无效的控件数据并标记这些错误.换言之,表单验证就是在表单提交服务器前对其进行一系列的检查并 ...
- Asp.net页面无刷新请求实现
Asp.net页面无刷新请求实现 <%@ Page Language="C#" AutoEventWireup="true" CodeBehind=&qu ...
- logback日志项目使用方法 - 150205交易模块添加日志信息logback,orderNo订单号为log主键便于跟踪,数字常量化,解决取消支付BUG,弱网络环境原因
1.项目里面的日志,便于跟踪数据的变更和异常错误信息产生.生产环境的日志级别是INFO,测试环境日志级别DEBUG,如果生产环境的日志级别是DEBUG,虽然方便查询问题,可以看到SQL语句等信息,但是 ...
- What does addScalar do?
The JavaDoc says: SQLQuery org.hibernate.SQLQuery.addScalar(String columnAlias, Type type) Declare a ...
- AIZU 2251
Merry Christmas Time Limit : 8 sec, Memory Limit : 65536 KB Problem J: Merry Christmas International ...
- POJ 1523 SPF(求割点)
题目链接 题意 : 找出图中所有的割点,然后输出删掉他们之后还剩多少个连通分量. 思路 : v与u邻接,要么v是u的孩子,要么u是v的祖先,(u,v)构成一条回边. //poj1523 #includ ...
- error LNK2019: 无法解析的外部符号 ___glutInitWithExit@12,该符号在函数 _glutInit_ATEXIT_HACK@8 中被引用 1>GEARS.obj : er
转: http://blog.csdn.net/bill_ming/article/details/8150111 opengl的高级菜鸟问题 看了一本书<OpenGL三维图形系统开发与应用技术 ...
- 使用var声明的变量 和 直接赋值并未声明的变量的区别
在看JS高级程序设计时忽然想到这个问题,众所周知,直接赋值一个变量而为声明,会产生一个全局变量(或者说是全局对象的属性),但用var声明的变量 和 直接赋值而并未声明的变量 都有哪些区别呢,这是我在百 ...
- 540C: Ice Cave
题目链接 题意: n*m的地图,'X'表示有裂痕的冰块,'.'表示完整的冰块,有裂痕的冰块再被踩一次就会碎掉,完整的冰块被踩一次会变成有裂痕的冰块, 现在告诉起点和终点,问从起点能否走到终点并且使终点 ...