Kafka入门学习(一)
====常用开源分布式消息系统
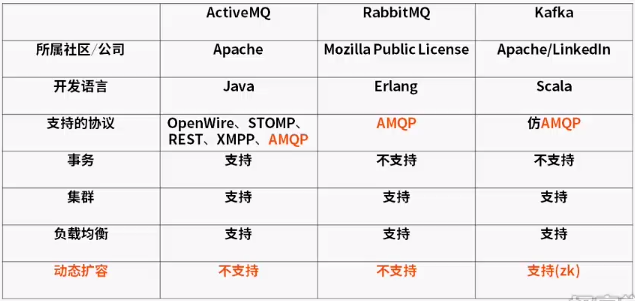
*集群:多台机器组成的系统叫集群。
*ActiveMQ还是支持JMS的一种消息中间件。
*阿里巴巴metaq,rocketmq都有kafka的影子。
*kafka的动态扩容目前是通过zookeeper来完成的。
====kafka定义及使用背景
是一个分布式消息系统,由Linkedln使用Scala编写,用作Linkedln的活动流(Activity Stream)
和运营数据处理管道(Pipeline)的基础,具有高水平扩展和高吞吐量
应用领域:已经被多家不同类型的公司作为多种类型的数据管道和消息系统使用,如:淘宝、支付宝、百度、twitter等。
目前越来越多的开元分布式处理系统都支持与Kafka集成,如
Apache flume(用于日志收集)
Apache Storm(用于实时数据处理)
Spark(用于内存数据处理)
elasticsearch(用于全文检索)
====kafka相关概念
1)AMPQ协议(即Advanced Message Queuing Protocol)
详细参考博客:http://blog.csdn.net/zhangxinrun/article/details/6411841

--消费者(Consumer):从消息队列中请求消息的客户端应用程序;
--生产者(Producer):从broker发布消息的客户端应用程序;
--APQP服务器端(broker):用来接收生产者发送的消息并将这些消息路由给服务器中的队列;
2)kafka支持的客户端语言
kafaka客户端支持当前大部分主流语言,包括:C、C++、Erlang、Java、.net、perl、PHP、Python、Ryby、Go、JavaScript。
可以使用以上任何一种语言和kafka服务器进行通信(即编写自己的consumer和producer程序)
3)kafka的架构
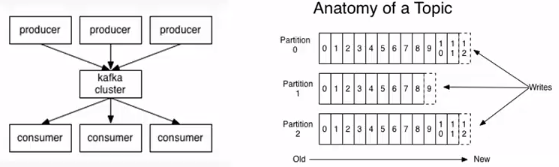
和传统的分布式消息队列一样,是由生产者向kafka集群生产消息、消费者从kafka集群订阅消息z这样的架构所组成。
kafka集群中的消息是按照主题(或者说Topic)来进行组成的。
--主题(Topic):一个主题类似新闻中的体育、娱乐、教育等分类概念,在实际工程中通常一个业务一个主题。
--分区(Partition):一个Topic中的消息数据按照多个分区组织,分区是kafka消息队列组织的最小单位,一个分区可以看做是一个FIFO(先进先出)队列;kafka分区是提高kafka性能的关键手段。
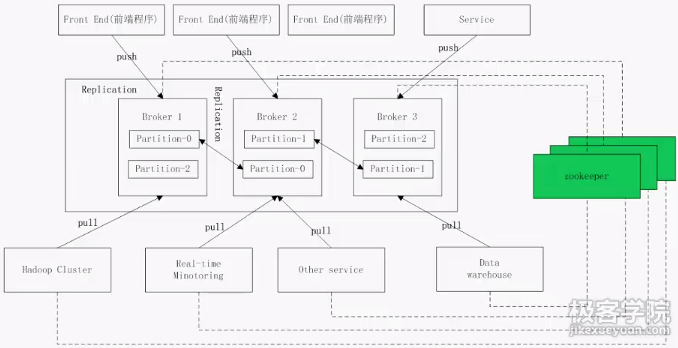
这张图在整体上对kafka集群进行了概要,途中kafka集群是由三台机器(Broker)组成,当然,实际情况可能更多。
相应的有3个分区,Partition-0~Partition-2,图中能看到每个分区的数据备份了2份。备份的数量可以通过kafka的配置参数来进行配置。在图中配置成了2.
kafka集群从前端应用程序(producer)生产消息,后端通过各种异构的消费者来订阅消息。
kafka集群和各种异构的生产者、消费者都使用zookeeper集群来进行分布式协调管理和分布式状态管理、分布式锁服务的。
*备份(Replication):为了保证分布式可靠性,kafka0.8开始对每个分区的数据进行备份(不同Broker上),防止其中一个Broker宕机造成分区数据不可用。
====zookeeper集群搭建
参考博客:http://www.cnblogs.com/ggjucheng/p/3352591.html
- 软件环境:
1)Linux服务器一台、三台、舞台(2*n+1台)。
问:是否可以用偶数台来搭建?
答:不一定,但是没有必要。根据zookeeper的工作原理,只要有超过半数以上存活,就可以对外提供服务。奇数方便判断“半数存活”。
2)JDK(我这里选择jdk-7u80-linux-x64.rpm)
3)zookeeper(我这里选择zookeeper-3.4.6.tar.gz,kafka在该版本上进行了大量测试,并修复了大量Bug)
- JDK安装
(省略)
环境变量可以修改两个文件
1)/etc/profile:对所有用户都有效的。
2)~/.bashrc:代表的是当前用户。
- zookeeper安装
1)解压缩:tar -zxvf zookeeper-3.4.6.tar.gz
2)配置文件:
--zoo.cfg文件的配置
zoo_sample.cfg是zk官方为我们提供的样本配置文件。
需要以它为副本复制一个zoo.cfg文件。zoo.cfg中需要配置以下内容:
•dataDir:存放数据
•dataLogDir:存放日志和快照
•server.1=<host>:<Master和Slave之间的通讯端口。默认为2888>:<Leader选举的端口。默认3888>。
集群中的每台机器都需要感知整个集群是由哪几台机器组成的,在配置文件中,可以按照这样的格式,每行写一个机器配置:server.id=host:port:port。
关于这个id,我们称之为Server ID,标识host机器在集群中的机器序号,在每个ZK机器上,我们需要在数据目录(数据目录就是dataDir参数指定的那个目录)下创建一个myid文件,
myid中就是这个Server ID数字。
配置之后如下:
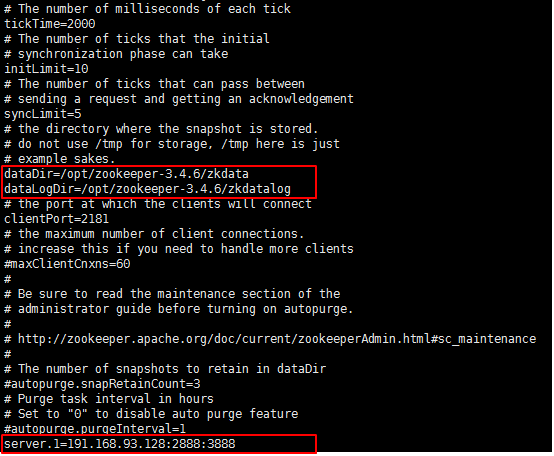
*zkdata和zkdatalog是新建的文件夹。用来存放数据和Log。
*dataLogDir这个属性如果不进行配置,将默认将zk事务日志和快照存放到dataDir下面,会严重影响性能。
*ip地址可以通过hostname -i来查看。
--myid的配置
可以通过echo命令来创建myid文件。命令:echo "1" > myid
3)启动zookeeper
启动方法:./zkServer.sh start
====kafka集群搭建
- 软件环境
Linux服务器一台或多台
已经搭建好的zookeeper集群
kafka_2.9.2-0.8.1.1
- kafka安装
1)解压缩kafka压缩包:tar -zxvf kafka_2.9.2-0.8.1.1
2)修改配置文件。kafka的配置文件很多,我们重点关注server.properties
具体配置内容请参考官方网站的配置:http://kafka.apache.org/documentation.html#brokerconfigs
以及中文博客:http://www.cnblogs.com/quchunhui/p/5356720.html
我这里配置了一下几项:
###Socket Server Settings###
port=9092
host.name=192.168.93.128
###Log Basics###
log.dirs=/opt/kafka_2.9.2-0.8.1.1/kafkalog
###Log Retention Policy###
message.max.bytes=5048576
default.replication.factor=2 //kafka集群保存消息的副本数
replica.fetch.max.bytes=5048576 //取消息的最大字节数
###Zookeeper###
zookeeper.connect=192.168.93.128:2181
- kafka启动
后台启动命令:./kafka-server-start.sh -daemon ../config/server.properties
使用jps命令查看进程是否存在,以验证是否正确启动。
- 验证是否搭建正确
(1)首先尝试创建一个topic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
(2)查看所有的topic
./kafka-topics.sh --list --zookeeper localhost:2181
(3)启动一个consumer
./kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
(4)向consumer发送消息
./kafka-console-producer.sh --broker-list 192.168.93.129:9092 --topic test
(5)查看创建的topic
./kafka-topics.sh --describe --zookeeper 192.168.93.129:2181 --topic test
Kafka入门学习(一)的更多相关文章
- Kafka入门学习随记(二)
====Kafka消费者模型 参考博客:http://www.tuicool.com/articles/fI7J3m --分区消费模型 分区消费架构图 图中kafka集群有两台服务器(Server), ...
- Kafka入门学习--基础
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就可 ...
- kafka入门学习---1 启动kakfa
1.查看kafka生产者产生的数据 kafka-console-consumer.sh --zookeeper hadoop-:,hadoop-:,hadoop-: -topic kafkademo ...
- Kafka -入门学习
kafka 1. 介绍 官网 http://kafka.apache.org/ 介绍 http://kafka.apache.org/intro 2. 快速开始 1. 安装 路径: http://ka ...
- _00017 Kafka的体系结构介绍以及Kafka入门案例(0基础案例+Java API的使用)
博文作者:妳那伊抹微笑 itdog8 地址链接 : http://www.itdog8.com(个人链接) 博客地址:http://blog.csdn.net/u012185296 博文标题:_000 ...
- 全网最通俗易懂的Kafka入门!
前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://github.com/ZhongFuCheng3y/3y 在这篇之前已经写过两篇基础文章了,强烈建议先去阅读: ...
- ElasticStack的入门学习
Beats,Logstash负责数据收集与处理.相当于ETL(Extract Transform Load).Elasticsearch负责数据存储.查询.分析.Kibana负责数据探索与可视化分析. ...
- 【转帖】全网最通俗易懂的Kafka入门
全网最通俗易懂的Kafka入门 http://www.itpub.net/2019/12/04/4597/ 前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://g ...
- Kafka入门(1):概述
摘要 在本文中,我将从为什么需要消息队列开始讲起,举两个小例子,跟你聊聊目前消息队列的一些使用场景. 比如消息队列在复杂系统中的解耦,又比如消息队列在高并发下的场景如果让流量变得更平缓. 随后我会跟你 ...
随机推荐
- win7设置防火墙允许Ping与telnet
Ping: 打开控制面板 >> 系统安全 >> windows防火墙 >> 高级设置 >> 入站规则
- 海外支付:遍布全球的Paypal
海外支付:遍布全球的Paypal 吴剑 2015-11-26 原创文章,转载必需注明出处:http://www.cnblogs.com/wu-jian 吴剑 http://www.cnblogs.co ...
- fw:学好Python必读的几篇文章
学好Python必读的几篇文章 from:http://blog.csdn.net/hzxhan/article/details/8555602 分类: python2013-01-30 11:52 ...
- Hibernate和JDBC、EJB比较
参考:http://m.blog.csdn.net/article/details?id=7228061 一.Hibernate是JDBC的轻量级的对象封装,它是一个独立的对象持久层框架,和App S ...
- Debian的一个命令
dpkg是一个Debian的一个命令行工具,它可以用来安装.删除.构建和管理Debian的软件包.下面是它的一些命令解释:1)安装软件命令行:dpkg -i <.deb file name> ...
- 浅谈如何使用代码为MP3文件写入ID3Tags
作者:郑童宇 GitHub:https://github.com/CrazyZty 1.前言 做了三年左右的Android开发,一直没写过博客,最近正好打算换工作,算是闲一些,就将以前开发所遇到的一些 ...
- Flash Air 打包安卓 ane
工具: 1.flash builder 2.adt打包工具 3.数字证书 一. 创建 jar 文件 1. 打开flash builder, 新建一个java 项目. 2.点击项目属性,选择Java构建 ...
- 二叉树之AVL树的平衡实现(递归与非递归)
这篇文章用来复习AVL的平衡操作,分别会介绍其旋转操作的递归与非递归实现,但是最终带有插入示例的版本会以递归呈现. 下面这张图绘制了需要旋转操作的8种情况.(我要给做这张图的兄弟一个赞)后面会给出这八 ...
- Django基础篇之数据库选择及相关操作
在djanjo框架中我们最常用的框架分别就是mysql和sqlit了,下面我们将分别讲述一下这俩种数据库的基础必备知识 mysql 一.利用命令创建(在终端上执行) 1.首先创建一个project项目 ...
- 华为OJ平台——求最大连续bit数
题目描述: 求一个byte数字对应的二进制数字中1的最大连续数,例如3的二进制为00000011,最大连续2个1 输入: 一个byte型的数字 输出: 对应的二进制数字中1的最大连续数 思路: ...