Kafka入门学习(一)
====常用开源分布式消息系统
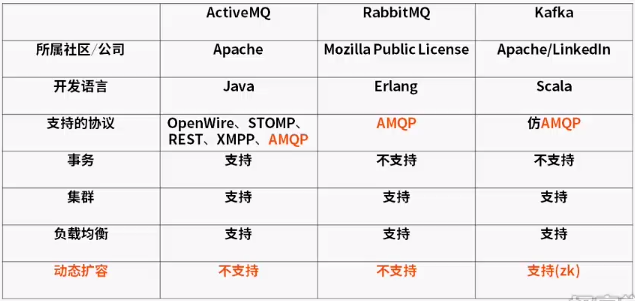
*集群:多台机器组成的系统叫集群。
*ActiveMQ还是支持JMS的一种消息中间件。
*阿里巴巴metaq,rocketmq都有kafka的影子。
*kafka的动态扩容目前是通过zookeeper来完成的。
====kafka定义及使用背景
是一个分布式消息系统,由Linkedln使用Scala编写,用作Linkedln的活动流(Activity Stream)
和运营数据处理管道(Pipeline)的基础,具有高水平扩展和高吞吐量
应用领域:已经被多家不同类型的公司作为多种类型的数据管道和消息系统使用,如:淘宝、支付宝、百度、twitter等。
目前越来越多的开元分布式处理系统都支持与Kafka集成,如
Apache flume(用于日志收集)
Apache Storm(用于实时数据处理)
Spark(用于内存数据处理)
elasticsearch(用于全文检索)
====kafka相关概念
1)AMPQ协议(即Advanced Message Queuing Protocol)
详细参考博客:http://blog.csdn.net/zhangxinrun/article/details/6411841

--消费者(Consumer):从消息队列中请求消息的客户端应用程序;
--生产者(Producer):从broker发布消息的客户端应用程序;
--APQP服务器端(broker):用来接收生产者发送的消息并将这些消息路由给服务器中的队列;
2)kafka支持的客户端语言
kafaka客户端支持当前大部分主流语言,包括:C、C++、Erlang、Java、.net、perl、PHP、Python、Ryby、Go、JavaScript。
可以使用以上任何一种语言和kafka服务器进行通信(即编写自己的consumer和producer程序)
3)kafka的架构
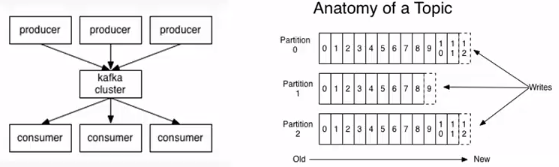
和传统的分布式消息队列一样,是由生产者向kafka集群生产消息、消费者从kafka集群订阅消息z这样的架构所组成。
kafka集群中的消息是按照主题(或者说Topic)来进行组成的。
--主题(Topic):一个主题类似新闻中的体育、娱乐、教育等分类概念,在实际工程中通常一个业务一个主题。
--分区(Partition):一个Topic中的消息数据按照多个分区组织,分区是kafka消息队列组织的最小单位,一个分区可以看做是一个FIFO(先进先出)队列;kafka分区是提高kafka性能的关键手段。
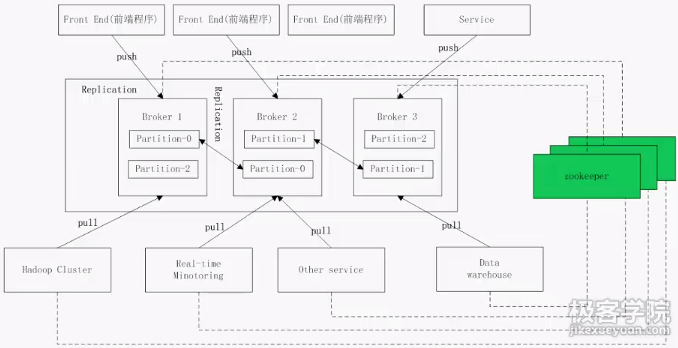
这张图在整体上对kafka集群进行了概要,途中kafka集群是由三台机器(Broker)组成,当然,实际情况可能更多。
相应的有3个分区,Partition-0~Partition-2,图中能看到每个分区的数据备份了2份。备份的数量可以通过kafka的配置参数来进行配置。在图中配置成了2.
kafka集群从前端应用程序(producer)生产消息,后端通过各种异构的消费者来订阅消息。
kafka集群和各种异构的生产者、消费者都使用zookeeper集群来进行分布式协调管理和分布式状态管理、分布式锁服务的。
*备份(Replication):为了保证分布式可靠性,kafka0.8开始对每个分区的数据进行备份(不同Broker上),防止其中一个Broker宕机造成分区数据不可用。
====zookeeper集群搭建
参考博客:http://www.cnblogs.com/ggjucheng/p/3352591.html
- 软件环境:
1)Linux服务器一台、三台、舞台(2*n+1台)。
问:是否可以用偶数台来搭建?
答:不一定,但是没有必要。根据zookeeper的工作原理,只要有超过半数以上存活,就可以对外提供服务。奇数方便判断“半数存活”。
2)JDK(我这里选择jdk-7u80-linux-x64.rpm)
3)zookeeper(我这里选择zookeeper-3.4.6.tar.gz,kafka在该版本上进行了大量测试,并修复了大量Bug)
- JDK安装
(省略)
环境变量可以修改两个文件
1)/etc/profile:对所有用户都有效的。
2)~/.bashrc:代表的是当前用户。
- zookeeper安装
1)解压缩:tar -zxvf zookeeper-3.4.6.tar.gz
2)配置文件:
--zoo.cfg文件的配置
zoo_sample.cfg是zk官方为我们提供的样本配置文件。
需要以它为副本复制一个zoo.cfg文件。zoo.cfg中需要配置以下内容:
•dataDir:存放数据
•dataLogDir:存放日志和快照
•server.1=<host>:<Master和Slave之间的通讯端口。默认为2888>:<Leader选举的端口。默认3888>。
集群中的每台机器都需要感知整个集群是由哪几台机器组成的,在配置文件中,可以按照这样的格式,每行写一个机器配置:server.id=host:port:port。
关于这个id,我们称之为Server ID,标识host机器在集群中的机器序号,在每个ZK机器上,我们需要在数据目录(数据目录就是dataDir参数指定的那个目录)下创建一个myid文件,
myid中就是这个Server ID数字。
配置之后如下:
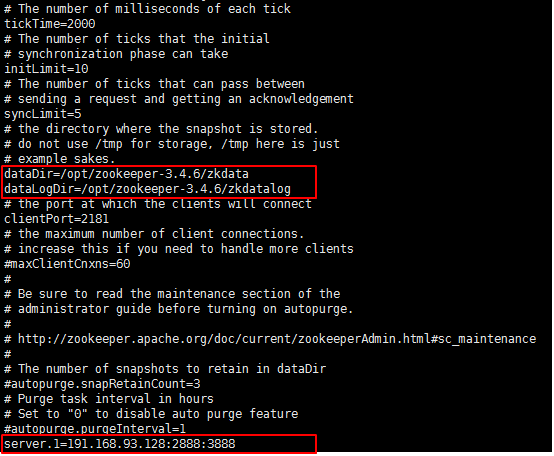
*zkdata和zkdatalog是新建的文件夹。用来存放数据和Log。
*dataLogDir这个属性如果不进行配置,将默认将zk事务日志和快照存放到dataDir下面,会严重影响性能。
*ip地址可以通过hostname -i来查看。
--myid的配置
可以通过echo命令来创建myid文件。命令:echo "1" > myid
3)启动zookeeper
启动方法:./zkServer.sh start
====kafka集群搭建
- 软件环境
Linux服务器一台或多台
已经搭建好的zookeeper集群
kafka_2.9.2-0.8.1.1
- kafka安装
1)解压缩kafka压缩包:tar -zxvf kafka_2.9.2-0.8.1.1
2)修改配置文件。kafka的配置文件很多,我们重点关注server.properties
具体配置内容请参考官方网站的配置:http://kafka.apache.org/documentation.html#brokerconfigs
以及中文博客:http://www.cnblogs.com/quchunhui/p/5356720.html
我这里配置了一下几项:
###Socket Server Settings###
port=9092
host.name=192.168.93.128
###Log Basics###
log.dirs=/opt/kafka_2.9.2-0.8.1.1/kafkalog
###Log Retention Policy###
message.max.bytes=5048576
default.replication.factor=2 //kafka集群保存消息的副本数
replica.fetch.max.bytes=5048576 //取消息的最大字节数
###Zookeeper###
zookeeper.connect=192.168.93.128:2181
- kafka启动
后台启动命令:./kafka-server-start.sh -daemon ../config/server.properties
使用jps命令查看进程是否存在,以验证是否正确启动。
- 验证是否搭建正确
(1)首先尝试创建一个topic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
(2)查看所有的topic
./kafka-topics.sh --list --zookeeper localhost:2181
(3)启动一个consumer
./kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
(4)向consumer发送消息
./kafka-console-producer.sh --broker-list 192.168.93.129:9092 --topic test
(5)查看创建的topic
./kafka-topics.sh --describe --zookeeper 192.168.93.129:2181 --topic test
Kafka入门学习(一)的更多相关文章
- Kafka入门学习随记(二)
====Kafka消费者模型 参考博客:http://www.tuicool.com/articles/fI7J3m --分区消费模型 分区消费架构图 图中kafka集群有两台服务器(Server), ...
- Kafka入门学习--基础
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就可 ...
- kafka入门学习---1 启动kakfa
1.查看kafka生产者产生的数据 kafka-console-consumer.sh --zookeeper hadoop-:,hadoop-:,hadoop-: -topic kafkademo ...
- Kafka -入门学习
kafka 1. 介绍 官网 http://kafka.apache.org/ 介绍 http://kafka.apache.org/intro 2. 快速开始 1. 安装 路径: http://ka ...
- _00017 Kafka的体系结构介绍以及Kafka入门案例(0基础案例+Java API的使用)
博文作者:妳那伊抹微笑 itdog8 地址链接 : http://www.itdog8.com(个人链接) 博客地址:http://blog.csdn.net/u012185296 博文标题:_000 ...
- 全网最通俗易懂的Kafka入门!
前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://github.com/ZhongFuCheng3y/3y 在这篇之前已经写过两篇基础文章了,强烈建议先去阅读: ...
- ElasticStack的入门学习
Beats,Logstash负责数据收集与处理.相当于ETL(Extract Transform Load).Elasticsearch负责数据存储.查询.分析.Kibana负责数据探索与可视化分析. ...
- 【转帖】全网最通俗易懂的Kafka入门
全网最通俗易懂的Kafka入门 http://www.itpub.net/2019/12/04/4597/ 前言 只有光头才能变强. 文本已收录至我的GitHub仓库,欢迎Star:https://g ...
- Kafka入门(1):概述
摘要 在本文中,我将从为什么需要消息队列开始讲起,举两个小例子,跟你聊聊目前消息队列的一些使用场景. 比如消息队列在复杂系统中的解耦,又比如消息队列在高并发下的场景如果让流量变得更平缓. 随后我会跟你 ...
随机推荐
- JS入门-慕课网
javascript是一种弱类型的数据交互语言, ch 1 数据类型 js中有六种数据类型:nunmber.string.boolean.null.undenfined.object原始类型:numb ...
- OpenGL ES学习笔记(一)——基本用法、绘制流程与着色器编译
首先声明下,本文为笔者学习<OpenGL ES应用开发实践指南(Android卷)>的笔记,涉及的代码均出自原书,如有需要,请到原书指定源码地址下载. 在Android.iOS等移动平台上 ...
- JavaScript数据结构,队列和栈
在JavaScript中为数组封装了大量的方法,比如:concat,pop,push,unshift,shift,forEach等,下面我将使用JavaScript提供的这些方法,实现队列和栈的操作. ...
- epoll在socket通信中的应用
当服务器需要服务多个客户时,需要使用并发通信,实现并发通信有以下几种方法: 1.在服务器中fork子进程来为每个客户服务 具体可参考http://www.cnblogs.com/ggjucheng/ ...
- 简单的TCPIP 客户端 服务器
// soClient.cpp : Defines the entry point for the console application. // #include "stdafx.h&qu ...
- Ossim应用体验视频
Ossim体验视频 近期,我写的有关Ossim应用的系列文章网友们非常关注,这里对大家提出有一些问题我制作了高清的视频和截图发布到网站,以让更多的人了解这款开源安全平台.在年后出版的教程中会详细讲解o ...
- 嵌入在C++程序中的extern "C"
1.extern的作用 extern是C/C++语言中表明函数和全局变量作用范围(可见性)的关键字,可以告知编译器,用extern声明的函数和变量可以在本模块或其它模块中使用. 通常,在模块的头文件中 ...
- WP8_ListBox的用法
在Windows Phone 7 Tips (5) 中曾经提到,在Windows Phone 7 中页面的布局一般分为:Panoramic.Pivot.List和Full Screen.而通常List ...
- 如何查找Mac上的USB存储设备使用痕迹
最近刚好有个案子的证物主机是MBP, OS X版本为El Capitan,案况与营业秘密外泄有关,当中要找有关USB存储设备的使用痕迹. 要提醒大家的是,不同版本的OS X,各种迹证的存放文件名称及路 ...
- Heavily reliance on forensic tools is risky
We could take advantage of forensic tools to examine and analyze the evidence, but heavily reliance ...