最大熵模型(Maximum Etropy)—— 熵,条件熵,联合熵,相对熵,互信息及其关系,最大熵模型。。
引入1:随机变量函数的分布
给定X的概率密度函数为fX(x), 若Y = aX, a是某正实数,求Y得概率密度函数fY(y).
解:令X的累积概率为FX(x), Y的累积概率为FY(y).
则 FY(y) = P(Y <= y) = P(aX <= y) = P(X <= y/a) = FX(y/a),
则 fY(y) = d(FX(y/a)) / dy = 1/a * fX(x/a)
引入2:如何定义信息量
- 某事件发生的概率小,则该事件的信息量大;
- 如果两个事件X和Y独立,即p(xy) = p(x)p(y),假定X和Y的信息量分别为h(X)和h(Y),则二者同时发生的信息量应该为h(XY) = h(X) + h(Y).
- 定义事件X发生的概率为:p(x),则X的信息量为:h(p(x)) = -lnp(x)
- 那么,事件X的信息量的期望如何计算呢?
一句话总结最大熵模型:
1. 我们的假设应当满足全部已知条件;
2. 对未知的情况不做任何主观假设。
(一)熵
对随机事件的信息量求期望,得熵的定义:
H(X) = -Σp(x)lnp(x)
- 经典熵的定义,底数是2,单位为bit;
- 为了方便计算可以使用底数e,则单位为nat(奈特)。
可以得到,当一个变量X服从均匀分布时,它所包含的信息熵是最大的。
计算如下:
p(xi) = 1/N, 则熵为:H(p) = -Σpi * lnpi = -Σ1/N * ln(1/N) = lnN
所以,我们可以得到如下结论:
- 0 <= H(X) <= ln|X|
- 熵是随机变量不确定性的度量,不确定性越大,熵值越大;
- 若随机变量退化为定值,则熵最小,为0;
- 锁随机分布为均匀分布,熵最大。
- 这是无条件的最大熵分布,那如果是有条件的,该怎么做呢?
- 使用最大熵模型
- 若只给定期望和方差的前提下,最大熵的分布形式是什么?
引理:根据函数的形式判断概率分布
例如:

所以,我们可以得到,正态分布的对数是关于随机变量x的二次函数:
根据计算过程的可逆性,若某对数分布能够写成随机变量二次形式,则该分布必然是正态分布。
再回到我们的问题上来,给定某随机变量的期望与方差,它的最大熵的分布形式是什么?
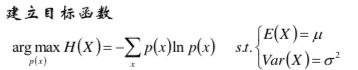
已知Var(X) = E(X2) - E(X)2 ,则 E(X2) = Var(X) - E(X)2 = σ2 - μ2,
所以我们将上述目标函数改写为:
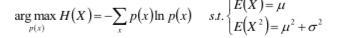
然后,建立Lagrange函数并求驻点:

由于P(x)的对数是关于随机变量x的二次形式,我们可以根据函数的形式判断概率分布,所以该分布p(x)必然是正态分布。
如果没有约束条件,最大熵对应的的分布为均匀分布;
如果给出了一定期望和方差,则最大熵对应的分布为正态分布。
(二)联合熵和条件熵
- 两个随机变量X,Y的恋歌分布,可以形成联合熵(Joint Entropy),用H(X, Y)表示。
- 即:H(X, Y) = -Σp(x, y) lnp(x, y)
- H(X, Y) - H(Y)
- 表示(X, Y)发生所包含的熵,减去Y单独发生包含的熵:在Y发生的前提下,X发生新带来的熵。
- 条件熵:H(X|Y)
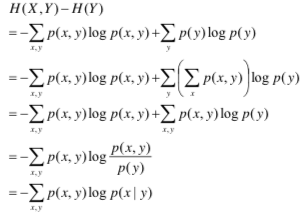
(三)相对熵/交叉熵/K-L散度
相对熵,又称互熵,交叉熵,鉴别信息,Kullback-Leible散度等。
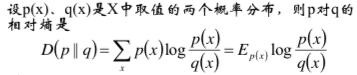
相对熵具有如下性质:
- 相对熵可以度量两个随机变量的距离;
- 一般不具有对称性,即D(p||q) ≠ D(q||p),当且仅当p = q, 则相对熵为0,二者相等;
- D(p||q) >= 0, D(q||p) >= 0.
那么,我们应该使用D(p||q) 还是 D(q||p)呢?
假定已知随机变量P,求一个随机变量Q,使得Q尽量接近于P,这样我们可以使用P和Q的K-L来度量他们的距离。
- 假定使用KL(Q || P),为了让距离最小,则要求P为0的地方,Q尽量为0。这样会得到比较瘦高的分布曲线;
- 假定使用KL(P || Q),为了让距离最小,则要求P不为0 的地方,Q也尽量不为0。这样会得到比较矮胖的分布曲线。
(四)互信息
两个随机变量X,Y的互信息,定义为X,Y的联合分布和独立分布乘积的相对熵。
即: I(X, Y) = D(P(X, Y) || P(X)P(Y))
即: 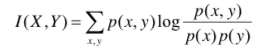
可以通过简单的计算得到:
H(X|Y) = H(X) - I(X, Y),
互信息为0,则随机变量X和Y是互相独立的。
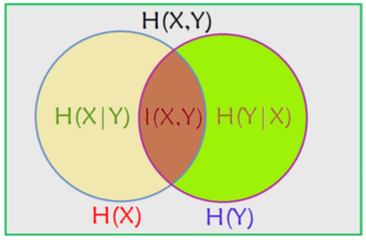
(五)各种熵之间的关系
- H(X|Y) = H(X, Y) - H(Y); H(Y|X) = H(X, Y) - H(X) —— 条件熵的定义
- H(X|Y) = H(X) - I(X, Y); H(Y|X) = H(Y) - I(X, Y)
- I(X, Y) = H(X) - H(X|Y) = H(X) + H(Y) - H(X, Y) —— 也可以作为互信息的定义
- H(X|Y) <= H(X):
- H(X)表示X的不确定度;H(X|Y)表示给定Y的情况下,X的不确定度。
- 如果X与Y完全独立,则二者相等(给不给Y对X能给出多少信息无关);
- 而如果X与Y不是独立的,则给定Y之后会降低X的熵,即X的不确定性会降低。
用Venn图帮助记忆:
(六)最大熵模型
最大熵模型的原则:
- 承认已知事物(知识);
- 对未知事物不做任何假设,没有任何偏见。
对一个随机事件的概率分布进行预测时,我们的预测应当满足全部已知条件,而对未知的情况不要做任何主观假设。在这种情况下,概率分布最均匀,预测的风险最小。
因为这时概率分布的信息熵最大,所以人们把这种模型叫做“最大熵模型”(Maximum Entropy)。
最大熵模型一般是在给定条件下求条件熵,所以我们可以使用Lagrange乘子法来解决。
1)最大熵的一般模型
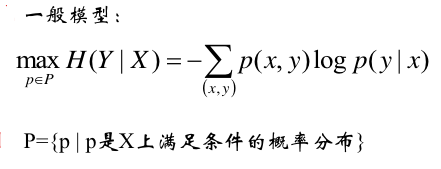
2)Lagrange函数为:
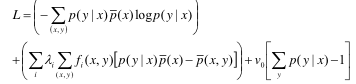
其中,含λi的第一个约束项表示我们的模型要能够很好的解释初始数据集,fi(x, y)表示我们选取的第i个特征;含ν0的第二个约束项表示概率加和为1.
p(x, y) = p(y | x) * p(x),而p(x)是已知的,所以我们用p(x)_bar来表示已知量。
3)对p(y|x)求偏导
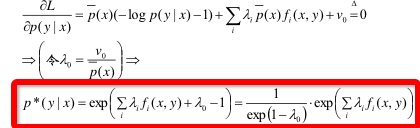
其中,为了计算方便,我们令ν0 = λ0 * p(x). 然后得到其最优解形式,如红框内所示。
4)归一化
上面通过求偏导得到的p*是没有经过归一化的,加上归一化因子zλ(x)。
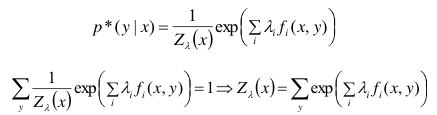
5)与Logistic/SoftMax回归的对比
- Logistic/SoftMax回归的后验概率形式:
- 最大熵模型的后验概率形式:
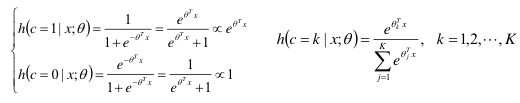

Logistic回归是统计学习中的经典分类方法,可以用于二类分类也可以用于多类分类。
最大熵模型由最大熵原理推导出来,最大熵原理是概率模型学习或估计的一个准则,最大熵原理认为在所有可能的概率模型的集合中,熵最大的模型是最好的模型,最大熵模型也可以用于二类分类和多类分类。
Logistic回归模型与最大熵模型都属于对数线性模型。
逻辑回归跟最大熵模型没有本质区别。逻辑回归是最大熵对应类别为二类时的特殊情况
指数簇分布的最大熵等价于其指数形式的最大似然。
二项式分布的最大熵解等价于二项式指数形式(sigmoid)的最大似然;
多项式分布的最大熵等价于多项式分布指数形式(softmax)的最大似然。
求最大熵的问题最后可以化成MLA的问题做,两者的出发点不同,但是最终的形式是一样的。
中心极限定理:一组有确定方差的独立随机变量的和趋近于高斯分布。即给定随机变量X和Y,则X+Y比X或Y更接近于高斯分布。
【总结】
- 根据最大似然估计的正确性可以断定:最大熵的解(无偏的对待不确定性)是最符合样本数据分布的解,即最大熵模型的合理性;
- 信息熵可以作为概率分布集散程度的度量,使用熵的近似可以推导出gini系数,在统计问题、决策树等问题中有重要应用;
- 熵:不确定性的度量;
- 似然:与知识的吻合程度;
- 最大熵模型:对不确定度的无偏分配;
- 最大似然估计:对知识的无偏理解。
最大熵模型(Maximum Etropy)—— 熵,条件熵,联合熵,相对熵,互信息及其关系,最大熵模型。。的更多相关文章
- 人工智能论文解读精选 | PRGC:一种新的联合关系抽取模型
NLP论文解读 原创•作者 | 小欣 论文标题:PRGC: Potential Relation and Global Correspondence Based Joint Relational ...
- 熵(Entropy),交叉熵(Cross-Entropy),KL-松散度(KL Divergence)
1.介绍: 当我们开发一个分类模型的时候,我们的目标是把输入映射到预测的概率上,当我们训练模型的时候就不停地调整参数使得我们预测出来的概率和真是的概率更加接近. 这篇文章我们关注在我们的模型假设这些类 ...
- [转]熵(Entropy),交叉熵(Cross-Entropy),KL-松散度(KL Divergence)
https://www.cnblogs.com/silent-stranger/p/7987708.html 1.介绍: 当我们开发一个分类模型的时候,我们的目标是把输入映射到预测的概率上,当我们训练 ...
- 树状结构Java模型、层级关系Java模型、上下级关系Java模型与html页面展示
树状结构Java模型.层级关系Java模型.上下级关系Java模型与html页面展示 一.业务原型:公司的组织结构.传销关系网 二.数据库模型 很简单,创建 id 与 pid 关系即可.(pid:pa ...
- DL4NLP——词表示模型(一)表示学习;syntagmatic与paradigmatic两类模型;基于矩阵的LSA和GloVe
本文简述了以下内容: 什么是词表示,什么是表示学习,什么是分布式表示 one-hot representation与distributed representation(分布式表示) 基于distri ...
- Flask-ORM-数据库的对象关系映射模型-备忘
ORM对象关系映射模型的特点: 优点 : 只需要面向对象编程, 不需要面向数据库编写代码. 对数据库的操作都转化成对类属性和方法的操作. 不用编写各种数据库的sql语句. 实现了数据模型与数据库的解耦 ...
- 最大熵模型 Maximum Entropy Model
熵的概念在统计学习与机器学习中真是很重要,熵的介绍在这里:信息熵 Information Theory .今天的主题是最大熵模型(Maximum Entropy Model,以下简称MaxEnt),M ...
- 通俗理解决策树中的熵&条件熵&信息增益
参考通俗理解决策树算法中的信息增益 说到决策树就要知道如下概念: 熵:表示一个随机变量的复杂性或者不确定性. 假如双十一我要剁手买一件衣服,但是我一直犹豫着要不要买,我决定买这件事的不确定性(熵)为2 ...
- 逻辑斯特回归(logistic regression)与最大熵模型(maximum entropy model)
随机推荐
- [经典php视频]构建正则表达式解析网页中的图像标记<img>
这是高洛峰php视频中的一段,视频中一边分析需要的功能,一边构建greg_match函数的参数,边讲解边实战,是非常好的一种构建功能的演示. 你不可能把浩瀚的IT资料都记在脑袋里,也不可能随时随地透过 ...
- JavaWeb开发实例---Servlet
1.页面转发:form表单的action属性值为Servlet类再web.xml中配置的URL. 2.重定向:sendRedirect() 只是 简单的页面跳转 转发:request.getRequ ...
- 【python cookbook】【字符串与文本】14.字符串连接及合并
问题:将许多小字符串合并成一个大的字符串 解决方案: 1.针对少数量的字符串:+ 2.针对大量的字符串对象的连接,更高效的方法:join() 3.更加复杂的字符串:format() >>& ...
- composer未升级报错
错误: Cannot adopt OID in SQUID-MIB: cacheClients ::= { cacheProtoAggregateStats 15 } Cannot adopt OID ...
- Java编译那些事儿【转】
转自:http://blog.csdn.net/lincyang/article/details/8553481 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[-] 命令行编译 使 ...
- 数字转表格标题 Excel Sheet Column Title
#include<string>using namespace std;class Solution {public: string convertToTitle(int n) { ...
- 【Pro ASP.NET MVC 3 Framework】.学习笔记.10.SportsStore:上传图片
1 扩展数据库 打开表定义,新增两列可空 ) 2 增强领域模型 为Products类添加如下属性 publicstring ImageMimeType { get; set; } 第一个属性不会在界面 ...
- WKWebView新特性及JS交互
引言 一直听说WKWebView比UIWebView强大许多,可是一直没有使用到,今天花了点时间看写了个例子,对其API的使用有所了解,为了日后能少走弯路,也为了让大家更容易学习上手,这里写下这篇文章 ...
- ftp服务的搭建及调用
首先是搭建 ftp server: 下载:http://archive.apache.org/dist/mina/ftpserver/1.0.6/ 下载到本地, 如下图:
- jquery与服务器交换数据的利器--ajax(异步javascript and xml)
load() 方法从服务器加载数据,并把返回的数据放入被选元素中. 一.下面的例子把 "demo_test.txt" 文件中 id="p1" 的元素的内容,加载 ...