pytorch实现MLP并在MNIST数据集上验证
写在前面
由于MLP的实现框架已经非常完善,网上搜到的代码大都大同小异,而且MLP的实现是deeplearning学习过程中较为基础的一个实验。因此完全可以找一份源码以参考,重点在于照着源码手敲一遍,以熟悉pytorch的基本操作。
实验要求
熟悉pytorch的基本操作:用pytorch实现MLP,并在MNIST数据集上进行训练
环境配置
实验环境如下:
- Win10
- python3.8
- Anaconda3
- Cuda10.2 + cudnn v7
- GPU : NVIDIA GeForce MX250
配置环境的过程中遇到了一些问题,解决方案如下:
anaconda下载过慢
使用清华镜像源,直接百度搜索即可
pytorch安装失败
这里我首先使用的是pip的安装方法,失败多次后尝试了使用anaconda,然后配置了清华镜像源,最后成功。参考的教程如下:
win10快速安装pytorch,清华镜像源当然也可以直接去pytorch官网下载所需版本的whl文件,然后手动pip安装。由于这种方式我已经学会了,为了学习anaconda,所以没有采用这种方式。具体方式可以百度如何使用whl。顺便贴下pytorch的whl的下载页面
注意:pytorch的版本是要严格对应是否使用GPU、python版本、cuda版本的,如需手动下载pytorch的安装包,需搞懂其whl文件的命名格式
另外还学习了anaconda的一些基本操作与原理,参考如下:
Anaconda完全入门指南
实验过程
最终代码见github:hit-deeplearning-1
首先设置一些全局变量,加载数据。batch_size决定了每次向网络中输入的样本数,epoch决定了整个数据集的迭代次数,具体作用与大小如何调整可参考附录中的博客。
将数据读入,如果数据不存在于本地,则可以自动从网上下载,并保存在本地的data文件夹下。
#一次取出的训练样本数
batch_size = 16
# epoch 的数目
n_epochs = 10
#读取数据
train_data = datasets.MNIST(root="./data", train=True, download=True,transform=transforms.ToTensor())
test_data = datasets.MNIST(root="./data", train=False, download=True, transform=transforms.ToTensor())
#创建数据加载器
train_loader = torch.utils.data.DataLoader(train_data, batch_size = batch_size, num_workers = 0)
test_loader = torch.utils.data.DataLoader(test_data, batch_size = batch_size, num_workers = 0)
接下来是创建MLP模型,关于如何创建一个模型,可以参考附录中的博客,总之创建模型模板,训练模板都是固定的。
其中Linear、view、CrossEntropyLoss、SGD的用法需重点关注。查看官方文档或博客解决。
这两条语句将数据放到了GPU上,同理测试的时候也要这样做。
data = data.cuda()
target = target.cuda()
class MLP(nn.Module):
def __init__(self):
#继承自父类
super(MLP, self).__init__()
#创建一个三层的网络
#输入的28*28为图片大小,输出的10为数字的类别数
hidden_first = 512
hidden_second = 512
self.first = nn.Linear(in_features=28*28, out_features=hidden_first)
self.second = nn.Linear(in_features=hidden_first, out_features=hidden_second)
self.third = nn.Linear(in_features=hidden_second, out_features=10)
def forward(self, data):
#先将图片数据转化为1*784的张量
data = data.view(-1, 28*28)
data = F.relu(self.first(data))
data = F.relu((self.second(data)))
data = F.log_softmax(self.third(data), dim = 1)
return data
def train():
# 定义损失函数和优化器
lossfunc = torch.nn.CrossEntropyLoss().cuda()
#lossfunc = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model.parameters(), lr=0.01)
# 开始训练
for epoch in range(n_epochs):
train_loss = 0.0
for data, target in train_loader:
optimizer.zero_grad()
#将数据放至GPU并计算输出
data = data.cuda()
target = target.cuda()
output = model(data)
#计算误差
loss = lossfunc(output, target)
#反向传播
loss.backward()
#将参数更新至网络中
optimizer.step()
#计算误差
train_loss += loss.item() * data.size(0)
train_loss = train_loss / len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch + 1, train_loss))
# 每遍历一遍数据集,测试一下准确率
test()
#最后将模型保存
path = "model.pt"
torch.save(model, path)
test程序不再贴出,直接调用了一个很常用的test程序。
最后是主程序,在这里将模型放到GPU上。
model = MLP()
#将模型放到GPU上
model = model.cuda()
train()
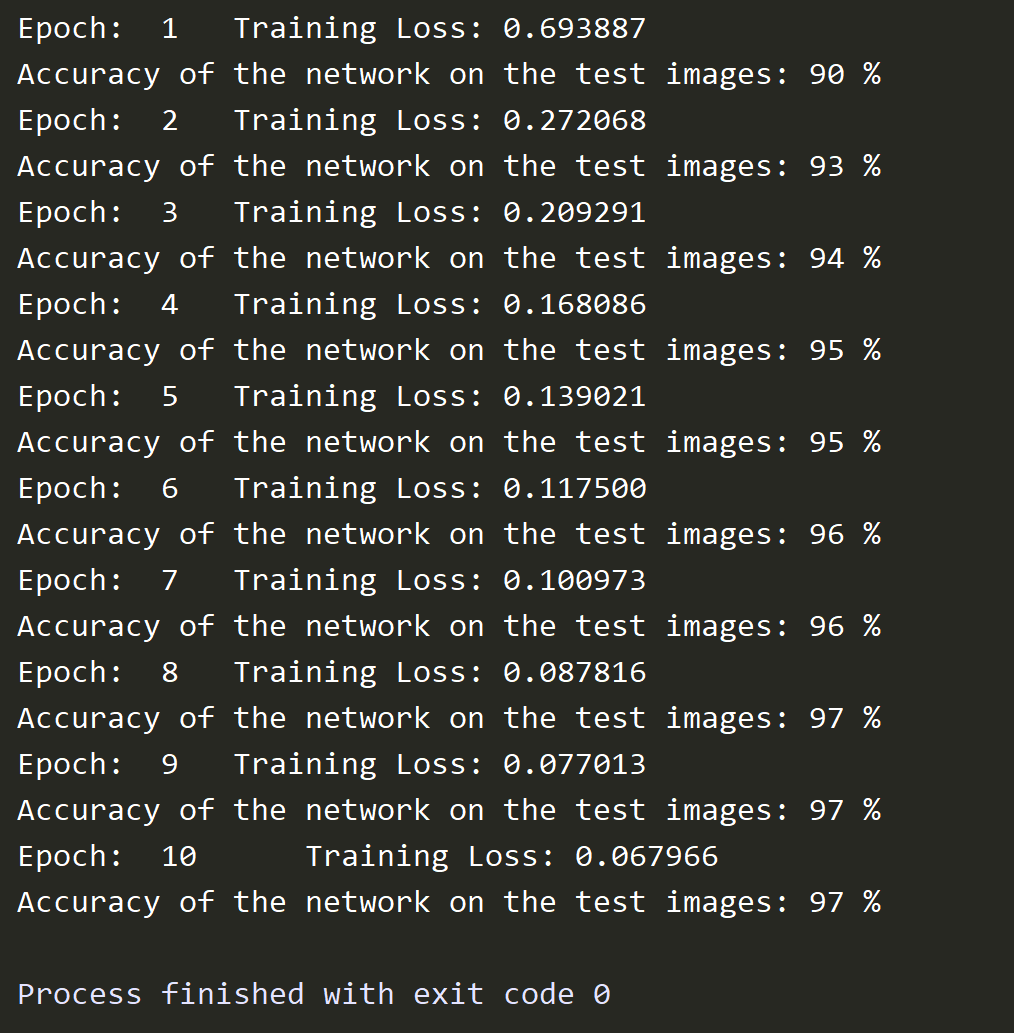
实验结果
实验结果如下,可以看到,当对数据迭代训练十次时,准确率已经可以达到97%
分别运行了两次,第一次没有使用cuda加速,第二次使用了cuda加速,任务管理器分别显示如下:
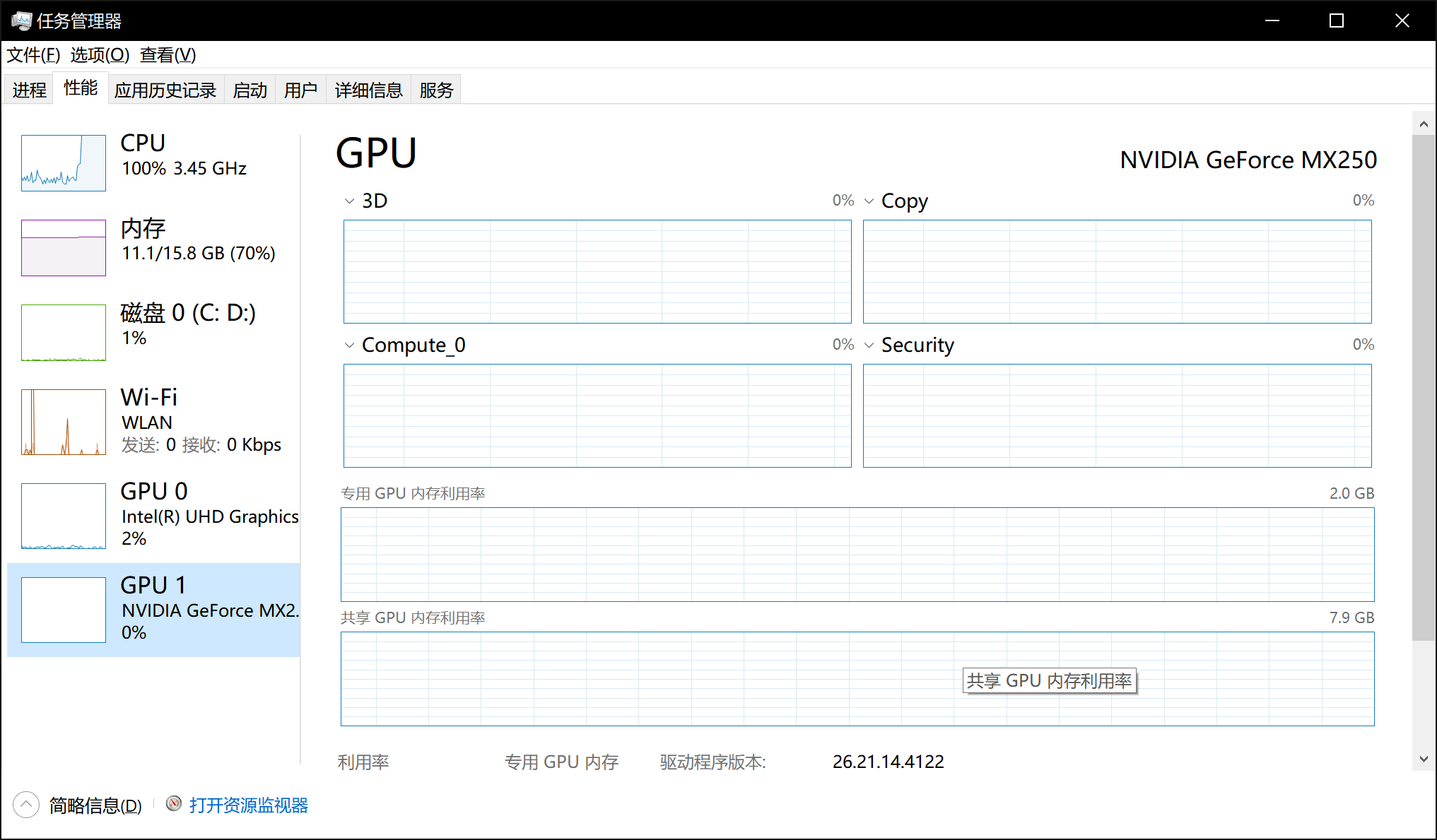
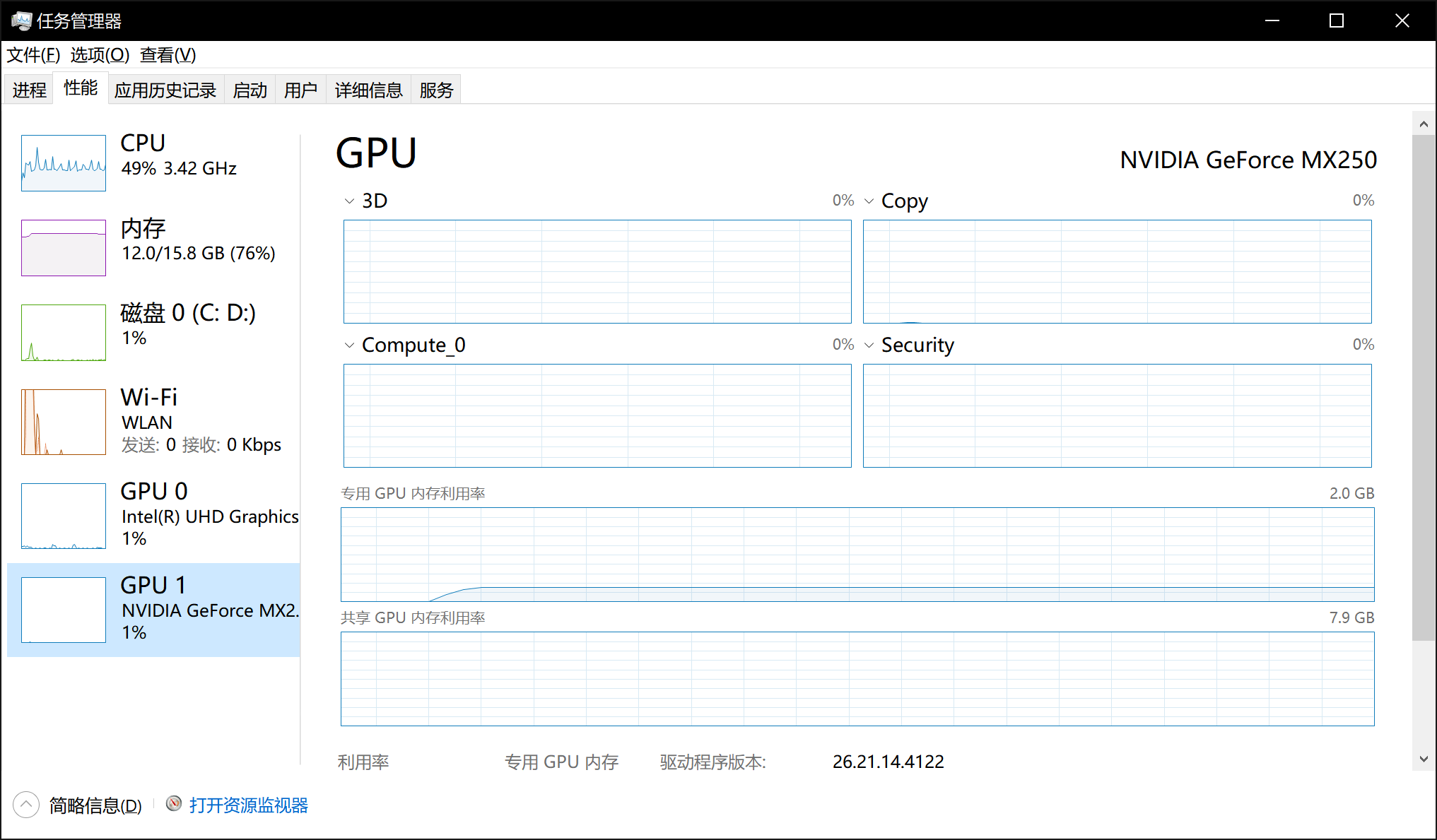
可以看到,未使用cuda加速时,cpu占用率达到了100%,而GPU的使用率为0;而使用cuda加速时,cpu占用率只有49%,而GPU使用率为1%。这里GPU使用率较低的原因很多,比如我程序中batch_size设置的较小,另外只将数据和模型放到了GPU上,cpu上仍有部分代码与数据。经简单测试,使用cuda的训练时间在2:30左右,不使用cuda的训练时间在3:40左右。
参考博客
如何创建自定义模型
pytorch教程之nn.Module类详解——使用Module类来自定义网络层
epoch和batch是什么
深度学习 | 三个概念:Epoch, Batch, Iteration
如何用GPU加速
PyTorch如何使用GPU加速(CPU与GPU数据的相互转换)
保存模型
pytorch实现MLP并在MNIST数据集上验证的更多相关文章
- MNIST数据集上卷积神经网络的简单实现(使用PyTorch)
设计的CNN模型包括一个输入层,输入的是MNIST数据集中28*28*1的灰度图 两个卷积层, 第一层卷积层使用6个3*3的kernel进行filter,步长为1,填充1.这样得到的尺寸是(28+1* ...
- caffe在windows编译project及执行mnist数据集測试
caffe在windows上的配置和编译能够參考例如以下的博客: http://blog.csdn.net/joshua_1988/article/details/45036993 http://bl ...
- TersorflowTutorial_MNIST数据集上简单CNN实现
MNIST数据集上简单CNN实现 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 Tensorflow机器学习实战指南 源代码请点击下方链接欢迎加星 Tesorflow实现基于MNI ...
- 【转载】用Scikit-Learn构建K-近邻算法,分类MNIST数据集
原帖地址:https://www.jiqizhixin.com/articles/2018-04-03-5 K 近邻算法,简称 K-NN.在如今深度学习盛行的时代,这个经典的机器学习算法经常被轻视.本 ...
- pytorch 加载mnist数据集报错not gzip file
利用pytorch加载mnist数据集的代码如下 import torchvision import torchvision.transforms as transforms from torch.u ...
- PyTorch迁移学习-私人数据集上的蚂蚁蜜蜂分类
迁移学习的两个主要场景 微调CNN:使用预训练的网络来初始化自己的网络,而不是随机初始化,然后训练即可 将CNN看成固定的特征提取器:固定前面的层,重写最后的全连接层,只有这个新的层会被训练 下面修改 ...
- 基于Keras 的VGG16神经网络模型的Mnist数据集识别并使用GPU加速
这段话放在前面:之前一种用的Pytorch,用着还挺爽,感觉挺方便的,但是在最近文献的时候,很多实验都是基于Google 的Keras的,所以抽空学了下Keras,学了之后才发现Keras相比Pyto ...
- SGD与Adam识别MNIST数据集
几种常见的优化函数比较:https://blog.csdn.net/w113691/article/details/82631097 ''' 基于Adam识别MNIST数据集 ''' import t ...
- MXNet学习-第一个例子:训练MNIST数据集
一个门外汉写的MXNET跑MNIST的例子,三层全连接层最后验证率是97%左右,毕竟是第一个例子,主要就是用来理解MXNet怎么使用. #导入需要的模块 import numpy as np #num ...
随机推荐
- Tail Call
一.什么是尾调用 尾调用(Tail Call)是函数式编程的一个重要概念. 一个函数里的最后一个动作是返回一个函数的调用结果,用简单的一句话描述就是"在函数的最后一步调用函数". ...
- iOS 页面流畅技巧(2)
一.屏幕显示图像的原理 首先从过去的 CRT 显示器原理说起.CRT 的电子枪按照上面方式,从上到下一行行扫描,扫描完成后显示器就呈现一帧画面,随后电子枪回到初始位置继续下一次扫描.为了把显示器的显示 ...
- 一篇漫画故事带你理解透HTTPS(下)
上下集知识点总结: 前情提要: 蝙蝠纪元,疫情之下.二丫欲访问京东购物,不料弹出安全提示,遂找二毛一探究竟.二毛一顿排查后,开始用通俗易懂的语言深入浅出的向二丫解释 HTTP作用及优缺点.HTTPS的 ...
- scrapy Selector用法及xpath语法
准备工作 html示例: <?xml version="1.0" encoding="UTF-8"?> <html <head> ...
- javascript实现组合列表框中元素移动效果
应用背景:在页面中有两个列表框,需要把其中一个列表框的元素移动到另一个列表框 . 实现的基本思想: (1)编写init方法对两个列表框进行初始化: (2)为body添加onload事件调用init方 ...
- 老技术新谈,Java应用监控利器JMX(1)
先聊聊最近比较流行的梗,来一次灵魂八问. 配钥匙师傅: 你配吗? 食堂阿姨: 你要饭吗? 算命先生: 你算什么东西? 快递小哥: 你是什么东西? 上海垃圾分拣阿姨: 你是什么垃圾? 滴滴司机: 你搞清 ...
- java对象clone
java克隆 为什么需要克隆 我们在很多时候需要使用一个对象去记录另外一个对象的当前状态,对象中可能会有很多属性,如果我们一个一个去设置,不仅不方便,而且效率很低,我们看一个初学者可能遇到的问题 cl ...
- 版本控制git的简单使用
0.第一次使用时配置: git config --global user.name "your_name" git config --global user.email " ...
- docker搭建可视化portainer
一.在docker中查询portainer # docker search portainer 二.下载portainer # docker pull portainer/portainer 三.运行 ...
- php 分页使用limit还是用mysql_data_seek()呢?
目前大部分教程中介绍的时LIMIT方法,使用这种方法要认识到以下几点: (1)limit不是标准的sql语句; (2)如果选择使用limit,那么您就必须首先向数据库发送一个查询语句来获取记录的总数, ...