032.核心组件-kube-proxy
一 kube-proxy原理
1.1 kube-proxy概述
二 kube-proxy模式
2.1 userspace模式
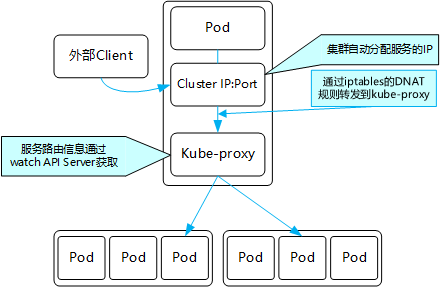
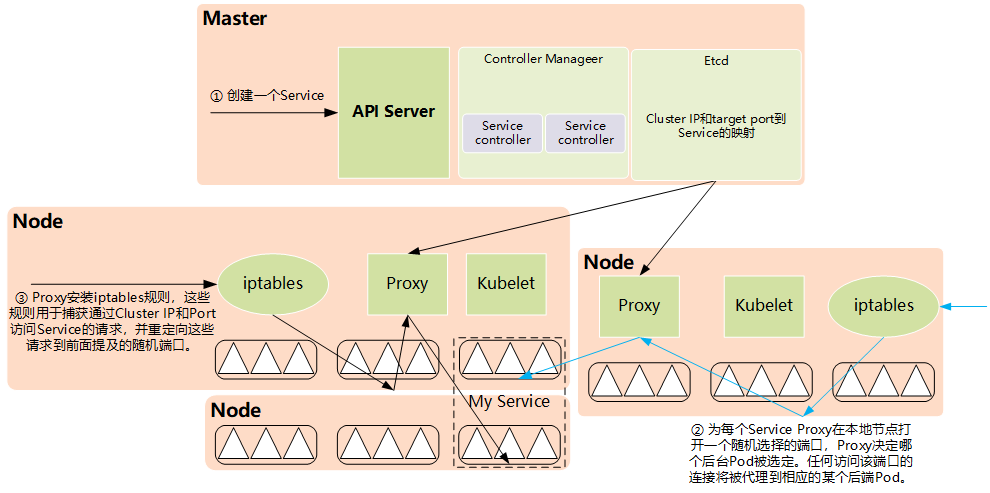
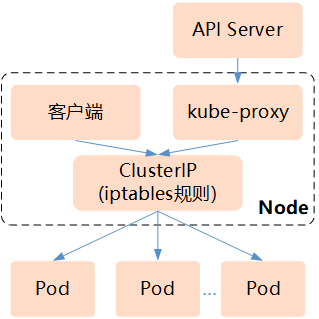
2.2 iptables模式
- KUBE-CLUSTER-IP:在masquerade-all=true或clusterCIDR指定的情况下对ServiceClusterIP地址进行伪装,以解决数据包欺骗问题。
- KUBE-EXTERNAL-IP:将数据包伪装成Service的外部IP地址。
- KUBE-LOAD-BALANCER、KUBE-LOAD-BALANCERLOCAL:伪装LoadBalancer类型的Service流量。
- KUBE-NODE-PORT-TCP、KUBE-NODE-PORT-LOCALTCP、KUBE-NODE-PORTUDP、KUBE-NODE-PORT-LOCAL-UDP:伪装NodePort类型的Service流量。
2.3 IPVS模式
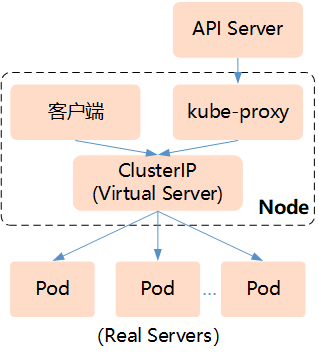
- 为大型集群提供了更好的可扩展性和性能;
- 支持比iptables更复杂的复制均衡算法(最小负载、最少连接、加权等);
- 支持服务器健康检查和连接重试等功能;
- 可以动态修改ipset的集合,即使iptables的规则正在使用这个集合。
032.核心组件-kube-proxy的更多相关文章
- [转帖]kubeadm 实现细节
kubeadm 实现细节 http://docs.kubernetes.org.cn/829.html 1 核心设计原则 2 常量和众所周知的值和路径 3 kubeadm init 工作流程内部设计 ...
- 026.[转] 基于Docker及Kubernetes技术构建容器云平台 (PaaS)
[编者的话] 目前很多的容器云平台通过Docker及Kubernetes等技术提供应用运行平台,从而实现运维自动化,快速部署应用.弹性伸缩和动态调整应用环境资源,提高研发运营效率. 本文简要介绍了与容 ...
- 【转载】浅析从外部访问 Kubernetes 集群中应用的几种方式
一般情况下,Kubernetes 的 Cluster Network 是属于私有网络,只能在 Cluster Network 内部才能访问部署的应用.那么如何才能将 Kubernetes 集群中的应用 ...
- k8s部署01-----what is k8s?
简介 1.Kubernetes代码托管在GitHub上:https://github.com/kubernetes/kubernetes/. 2.Kubernetes是一个开源的,容器集群管理系统,K ...
- K8S简介
简介 Kubernetes是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规 ...
- kubernetes 基础知识
1. kubernetes 包含几个组件 Kubernetes是什么:针对容器编排的一种分布式架构,是自动化容器操作的开源平台. 服务发现.内建负载均衡.强大的故障发现和自我修复机制.服务滚动升级和在 ...
- 2.k8s的架构
之前了解了k8s到底是什么,接下来看看k8s的组成. 一.Kubernetes架构 学习k8s,最终目的是为了部署应用,部署一个完整的k8s, 就要知道k8s的组成.k8s主要包含两大部分: 中间包含 ...
- 基于Kubernetes/K8S构建Jenkins持续集成平台(上)-2
基于Kubernetes/K8S构建Jenkins持续集成平台(上)-2 Kubernetes实现Master-Slave分布式构建方案 传统Jenkins的Master-Slave方案的缺陷 Mas ...
- 【k8s连载系列】2. k8s整体架构
# 一.Kubernetes的整体架构 学习k8s,最终目的是为了部署应用,部署一个完整的k8s, 就要知道k8s的组成.k8s主要包含两大部分: 中间包含三个绿色包的是master服务器. 下面是n ...
随机推荐
- 吴裕雄--天生自然python学习笔记:WEB数据抓取与分析
Web 数据抓取技术具有非常巨大的应用需求及价值, 用 Python 在网页上收集数据,不仅抓取数据的操作简单, 而且其数据分析功能也十分强大. 通过 Python 的时lib 组件中的 urlpar ...
- 关于前端使用JavaScript无法实现canvas打印问题的解决
当使用浏览器的打印功能window.print()无法打印网页上的canvas图像,但是可以通过转换canvas成一个图片的形式来实现canvas的打印. 解决方法 getElementById获取c ...
- 《hdu 4540 威威猫打地鼠》
威威猫系列故事——打地鼠 Time Limit: 300/100 MS (Java/Others) Memory Limit: 65535/32768 K (Java/Others)Total ...
- SSM 生成mapper中xml文件:未能解析映射资源:“文件嵌套异常
错误日记我就网上随便找个贴着: 错误一: org.springframework.beans.factory.BeanCreationException: Error creating bean wi ...
- 吴裕雄--天生自然 人工智能机器学习实战代码:ELASTICNET回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄--天生自然 PHP开发学习:在centos7操作系统下使用命令安装ThinkPHP 5框架
前提条件是系统已经安装好了php,一般来说安装好的php根目录是:/var/www/html 系统安装composer(我使用的系统是centos7) .使用命令下载 curl -sS https:/ ...
- 微软推出中文学习AI助手Microsoft Learn Chinese
编者按:美国总统特朗普访华期间,他6岁的外孙女阿拉贝拉用中文普通话演唱和背诵传统诗歌的视频在中国社交媒体上引起广泛关注,可以感受得到,越来越多的人对中文学习充满了兴趣.智能私教微软小英帮助很多中国 ...
- 安全测试——利用Burpsuite密码爆破(Intruder入侵)
本文章仅供学习参考,技术大蛙请绕过. 最近一直在想逛了这么多博客.论坛了,总能收获一堆干货,也从没有给博主个好评什么的,想想着实有些不妥.所以最近就一直想,有时间的时候自己也撒两把小米,就当作是和大家 ...
- e代驾狂野裁员 O2O逐渐恢复理智?
O2O逐渐恢复理智?" title="e代驾狂野裁员 O2O逐渐恢复理智?"> 近段时间以来,O2O行业堪称"哀鸿遍野",十分凄惨.巨头 ...
- 第二章 表与指针Pro SQL Server Internal (Dmitri Korotkev)
聚集索引 聚集索引就是表中数据的物理顺序,它是按照聚集索引分类的.表只能定义一个聚集索引. 如果你要在一个有数据的堆表中创建一个聚集索引,如2-5所示,第一步要做的就是SQL服务器创建另一个根据聚集索 ...