【猫狗数据集】使用预训练的resnet18模型
数据集下载地址:
链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw
提取码:2xq4
创建数据集:https://www.cnblogs.com/xiximayou/p/12398285.html
读取数据集:https://www.cnblogs.com/xiximayou/p/12422827.html
进行训练:https://www.cnblogs.com/xiximayou/p/12448300.html
保存模型并继续进行训练:https://www.cnblogs.com/xiximayou/p/12452624.html
加载保存的模型并测试:https://www.cnblogs.com/xiximayou/p/12459499.html
划分验证集并边训练边验证:https://www.cnblogs.com/xiximayou/p/12464738.html
使用学习率衰减策略并边训练边测试:https://www.cnblogs.com/xiximayou/p/12468010.html
利用tensorboard可视化训练和测试过程:https://www.cnblogs.com/xiximayou/p/12482573.html
从命令行接收参数:https://www.cnblogs.com/xiximayou/p/12488662.html
使用top1和top5准确率来衡量模型:https://www.cnblogs.com/xiximayou/p/12489069.html
epoch、batchsize、step之间的关系:https://www.cnblogs.com/xiximayou/p/12405485.html
之前都是从头开始训练模型,本节我们要使用预训练的模型来进行训练。
只需要在train.py中加上:
if baseline:
model =torchvision.models.resnet18(pretrained=False)
model.fc = nn.Linear(model.fc.in_features,2,bias=False)
else:
print("使用预训练的resnet18模型")
model=torchvision.models.resnet18(pretrained=True)
for i in model.state_dict():
print(i)
model.fc = nn.Linear(model.fc.in_features,2,bias=False)
print(model)
使用预训练的resnet18模型
conv1.weight
bn1.weight
bn1.bias
bn1.running_mean
bn1.running_var
bn1.num_batches_tracked
layer1.0.conv1.weight
layer1.0.bn1.weight
layer1.0.bn1.bias
layer1.0.bn1.running_mean
layer1.0.bn1.running_var
layer1.0.bn1.num_batches_tracked
layer1.0.conv2.weight
layer1.0.bn2.weight
layer1.0.bn2.bias
layer1.0.bn2.running_mean
layer1.0.bn2.running_var
layer1.0.bn2.num_batches_tracked
layer1.1.conv1.weight
layer1.1.bn1.weight
layer1.1.bn1.bias
layer1.1.bn1.running_mean
layer1.1.bn1.running_var
layer1.1.bn1.num_batches_tracked
layer1.1.conv2.weight
layer1.1.bn2.weight
layer1.1.bn2.bias
layer1.1.bn2.running_mean
layer1.1.bn2.running_var
layer1.1.bn2.num_batches_tracked
layer2.0.conv1.weight
layer2.0.bn1.weight
layer2.0.bn1.bias
layer2.0.bn1.running_mean
layer2.0.bn1.running_var
layer2.0.bn1.num_batches_tracked
layer2.0.conv2.weight
layer2.0.bn2.weight
layer2.0.bn2.bias
layer2.0.bn2.running_mean
layer2.0.bn2.running_var
layer2.0.bn2.num_batches_tracked
layer2.0.downsample.0.weight
layer2.0.downsample.1.weight
layer2.0.downsample.1.bias
layer2.0.downsample.1.running_mean
layer2.0.downsample.1.running_var
layer2.0.downsample.1.num_batches_tracked
layer2.1.conv1.weight
layer2.1.bn1.weight
layer2.1.bn1.bias
layer2.1.bn1.running_mean
layer2.1.bn1.running_var
layer2.1.bn1.num_batches_tracked
layer2.1.conv2.weight
layer2.1.bn2.weight
layer2.1.bn2.bias
layer2.1.bn2.running_mean
layer2.1.bn2.running_var
layer2.1.bn2.num_batches_tracked
layer3.0.conv1.weight
layer3.0.bn1.weight
layer3.0.bn1.bias
layer3.0.bn1.running_mean
layer3.0.bn1.running_var
layer3.0.bn1.num_batches_tracked
layer3.0.conv2.weight
layer3.0.bn2.weight
layer3.0.bn2.bias
layer3.0.bn2.running_mean
layer3.0.bn2.running_var
layer3.0.bn2.num_batches_tracked
layer3.0.downsample.0.weight
layer3.0.downsample.1.weight
layer3.0.downsample.1.bias
layer3.0.downsample.1.running_mean
layer3.0.downsample.1.running_var
layer3.0.downsample.1.num_batches_tracked
layer3.1.conv1.weight
layer3.1.bn1.weight
layer3.1.bn1.bias
layer3.1.bn1.running_mean
layer3.1.bn1.running_var
layer3.1.bn1.num_batches_tracked
layer3.1.conv2.weight
layer3.1.bn2.weight
layer3.1.bn2.bias
layer3.1.bn2.running_mean
layer3.1.bn2.running_var
layer3.1.bn2.num_batches_tracked
layer4.0.conv1.weight
layer4.0.bn1.weight
layer4.0.bn1.bias
layer4.0.bn1.running_mean
layer4.0.bn1.running_var
layer4.0.bn1.num_batches_tracked
layer4.0.conv2.weight
layer4.0.bn2.weight
layer4.0.bn2.bias
layer4.0.bn2.running_mean
layer4.0.bn2.running_var
layer4.0.bn2.num_batches_tracked
layer4.0.downsample.0.weight
layer4.0.downsample.1.weight
layer4.0.downsample.1.bias
layer4.0.downsample.1.running_mean
layer4.0.downsample.1.running_var
layer4.0.downsample.1.num_batches_tracked
layer4.1.conv1.weight
layer4.1.bn1.weight
layer4.1.bn1.bias
layer4.1.bn1.running_mean
layer4.1.bn1.running_var
layer4.1.bn1.num_batches_tracked
layer4.1.conv2.weight
layer4.1.bn2.weight
layer4.1.bn2.bias
layer4.1.bn2.running_mean
layer4.1.bn2.running_var
layer4.1.bn2.num_batches_tracked
fc.weight
fc.bias
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=2, bias=False)
)
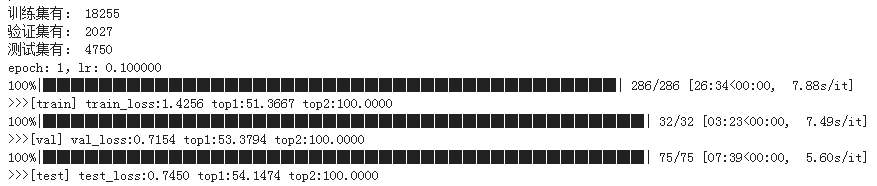
接下来来看看如何冻结某些层,不让其在训练的时候进行梯度更新。
首先我们输出下信息看看结构:
i=0
for child in model.children():
i+=1
print("第{}个child".format(str(i)))
print(child)
第1个child
Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
第2个child
BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
第3个child
ReLU(inplace=True)
第4个child
MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
第5个child
Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
第6个child
Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
第7个child
Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
第8个child
Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
第9个child
AdaptiveAvgPool2d(output_size=(1, 1))
第10个child
Linear(in_features=512, out_features=2, bias=False)
我们冻结前面的7个child,只更新第8、9、10个child的参数。可这么定义:
print("使用预训练的resnet18模型")
model=torchvision.models.resnet18(pretrained=True)
model.fc = nn.Linear(model.fc.in_features,2,bias=False)
i=0
for child in model.children():
i+=1
#print("第{}个child".format(str(i)))
#print(child)
if i<=7:
for param in child.parameters():
param.requires_grad=False
#我们打印下是否是设置成功
for name, param in model.named_parameters():
if param.requires_grad:
print("需要梯度:", name)
else:
print("不需要梯度:", name)
接下来我们还要在优化器中过滤掉不需要更新参数的层:
optimizer = torch.optim.SGD(filter(lambda p: p.requires_grad, model.parameters()), lr=0.1, momentum=0.9,
weight_decay=1*1e-4)
结果:
使用预训练的resnet18模型
不需要梯度: conv1.weight
不需要梯度: bn1.weight
不需要梯度: bn1.bias
不需要梯度: layer1.0.conv1.weight
不需要梯度: layer1.0.bn1.weight
不需要梯度: layer1.0.bn1.bias
不需要梯度: layer1.0.conv2.weight
不需要梯度: layer1.0.bn2.weight
不需要梯度: layer1.0.bn2.bias
不需要梯度: layer1.1.conv1.weight
不需要梯度: layer1.1.bn1.weight
不需要梯度: layer1.1.bn1.bias
不需要梯度: layer1.1.conv2.weight
不需要梯度: layer1.1.bn2.weight
不需要梯度: layer1.1.bn2.bias
不需要梯度: layer2.0.conv1.weight
不需要梯度: layer2.0.bn1.weight
不需要梯度: layer2.0.bn1.bias
不需要梯度: layer2.0.conv2.weight
不需要梯度: layer2.0.bn2.weight
不需要梯度: layer2.0.bn2.bias
不需要梯度: layer2.0.downsample.0.weight
不需要梯度: layer2.0.downsample.1.weight
不需要梯度: layer2.0.downsample.1.bias
不需要梯度: layer2.1.conv1.weight
不需要梯度: layer2.1.bn1.weight
不需要梯度: layer2.1.bn1.bias
不需要梯度: layer2.1.conv2.weight
不需要梯度: layer2.1.bn2.weight
不需要梯度: layer2.1.bn2.bias
不需要梯度: layer3.0.conv1.weight
不需要梯度: layer3.0.bn1.weight
不需要梯度: layer3.0.bn1.bias
不需要梯度: layer3.0.conv2.weight
不需要梯度: layer3.0.bn2.weight
不需要梯度: layer3.0.bn2.bias
不需要梯度: layer3.0.downsample.0.weight
不需要梯度: layer3.0.downsample.1.weight
不需要梯度: layer3.0.downsample.1.bias
不需要梯度: layer3.1.conv1.weight
不需要梯度: layer3.1.bn1.weight
不需要梯度: layer3.1.bn1.bias
不需要梯度: layer3.1.conv2.weight
不需要梯度: layer3.1.bn2.weight
不需要梯度: layer3.1.bn2.bias
需要梯度: layer4.0.conv1.weight
需要梯度: layer4.0.bn1.weight
需要梯度: layer4.0.bn1.bias
需要梯度: layer4.0.conv2.weight
需要梯度: layer4.0.bn2.weight
需要梯度: layer4.0.bn2.bias
需要梯度: layer4.0.downsample.0.weight
需要梯度: layer4.0.downsample.1.weight
需要梯度: layer4.0.downsample.1.bias
需要梯度: layer4.1.conv1.weight
需要梯度: layer4.1.bn1.weight
需要梯度: layer4.1.bn1.bias
需要梯度: layer4.1.conv2.weight
需要梯度: layer4.1.bn2.weight
需要梯度: layer4.1.bn2.bias
需要梯度: fc.weight
拓展:如果是我们自己定义的模型和预训练的模型不一致应该怎么加载参数呢?
这里以以resnet50为例,这里我们再新定义一个卷积神经网络:
# coding=UTF-8
import torchvision.models as models
import torch
import torch.nn as nn
import math
import torch.utils.model_zoo as model_zoo class CNN(nn.Module): def __init__(self, block, layers, num_classes=2):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
#新增一个反卷积层
self.convtranspose1 = nn.ConvTranspose2d(2048, 2048, kernel_size=3, stride=1, padding=1, output_padding=0, groups=1, bias=False, dilation=1)
#新增一个最大池化层
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
#去掉原来的fc层,新增一个fclass层
self.fclass = nn.Linear(2048, num_classes) for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_() def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
) layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes)) return nn.Sequential(*layers) def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x) x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x) x = self.avgpool(x)
#新加层的forward
x = x.view(x.size(0), -1)
x = self.convtranspose1(x)
x = self.maxpool2(x)
x = x.view(x.size(0), -1)
x = self.fclass(x) return x #加载model
resnet50 = models.resnet50(pretrained=True)
cnn = CNN(Bottleneck, [3, 4, 6, 3])
#读取参数
#取出预训练模型的参数
pretrained_dict = resnet50.state_dict()
#取出本模型的参数
model_dict = cnn.state_dict()
# 将pretrained_dict里不属于model_dict的键剔除掉
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
# 更新现有的model_dict
model_dict.update(pretrained_dict)
# 加载我们真正需要的state_dict
cnn.load_state_dict(model_dict)
# print(resnet50)
print(cnn)
下面也摘取了一些使用部分预训练模型初始化网络的方法:
方式一: 自己网络和预训练网络结构一致的层,使用预训练网络对应层的参数批量初始化
model_dict = model.state_dict() # 取出自己网络的参数字典
pretrained_dict = torch.load("I:/迅雷下载/alexnet-owt-4df8aa71.pth")# 加载预训练网络的参数字典
# 取出预训练网络的参数字典
keys = []
for k, v in pretrained_dict.items():
keys.append(k)
i = 0 # 自己网络和预训练网络结构一致的层,使用预训练网络对应层的参数初始化
for k, v in model_dict.items():
if v.size() == pretrained_dict[keys[i]].size():
model_dict[k] = pretrained_dict[keys[i]]
#print(model_dict[k])
i = i + 1
model.load_state_dict(model_dict)
方式二:自己网络和预训练网络结构一致的层,按层初始化
# 加粗自己定义一个网络叫CNN
model = CNN()
model_dict = model.state_dict() # 取出自己网络的参数 for k, v in model_dict.items(): # 查看自己网络参数各层叫什么名称
print(k) pretrained_dict = torch.load("I:/迅雷下载/alexnet-owt-4df8aa71.pth")# 加载预训练网络的参数
for k, v in pretrained_dict.items(): # 查看预训练网络参数各层叫什么名称
print(k) # 对应层赋值初始化
model_dict['conv1.0.weight'] = pretrained_dict['features.0.weight'] # 将自己网络的conv1.0层的权重初始化为预训练网络features.0层的权重
model_dict['conv1.0.bias'] = pretrained_dict['features.0.bias'] # 将自己网络的conv1.0层的偏置项初始化为预训练网络features.0层的偏置项 model_dict['conv2.1.weight'] = pretrained_dict['features.3.weight']
model_dict['conv1.1.bias'] = pretrained_dict['features.3.bias'] model_dict['conv2.1.weight'] = pretrained_dict['features.6.weight']
model_dict['conv2.1.bias'] = pretrained_dict['features.6.bias'] ... ...
下一节补充下计算数据集的标准差和方差,在数据增强时对数据进行标准化的时候用。
参考:
https://blog.csdn.net/feizai1208917009/article/details/103598233
https://blog.csdn.net/whut_ldz/article/details/78845947
【猫狗数据集】使用预训练的resnet18模型的更多相关文章
- 【猫狗数据集】pytorch训练猫狗数据集之创建数据集
猫狗数据集的分为训练集25000张,在训练集中猫和狗的图像是混在一起的,pytorch读取数据集有两种方式,第一种方式是将不同类别的图片放于其对应的类文件夹中,另一种是实现读取数据集类,该类继承tor ...
- 在 C/C++ 中使用 TensorFlow 预训练好的模型—— 直接调用 C++ 接口实现
现在的深度学习框架一般都是基于 Python 来实现,构建.训练.保存和调用模型都可以很容易地在 Python 下完成.但有时候,我们在实际应用这些模型的时候可能需要在其他编程语言下进行,本文将通过直 ...
- TensorFlow 同时调用多个预训练好的模型
在某些任务中,我们需要针对不同的情况训练多个不同的神经网络模型,这时候,在测试阶段,我们就需要调用多个预训练好的模型分别来进行预测. 调用单个预训练好的模型请点击此处 弄明白了如何调用单个模型,其实调 ...
- 在 C/C++ 中使用 TensorFlow 预训练好的模型—— 间接调用 Python 实现
现在的深度学习框架一般都是基于 Python 来实现,构建.训练.保存和调用模型都可以很容易地在 Python 下完成.但有时候,我们在实际应用这些模型的时候可能需要在其他编程语言下进行,本文将通过 ...
- TensorFlow 调用预训练好的模型—— Python 实现
1. 准备预训练好的模型 TensorFlow 预训练好的模型被保存为以下四个文件 data 文件是训练好的参数值,meta 文件是定义的神经网络图,checkpoint 文件是所有模型的保存路径,如 ...
- 【猫狗数据集】使用top1和top5准确率衡量模型
数据集下载地址: 链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw提取码:2xq4 创建数据集:https://www.cnblogs.com/xi ...
- 【猫狗数据集】利用tensorboard可视化训练和测试过程
数据集下载地址: 链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw提取码:2xq4 创建数据集:https://www.cnblogs.com/xi ...
- 【猫狗数据集】谷歌colab之使用pytorch读取自己数据集(猫狗数据集)
之前在:https://www.cnblogs.com/xiximayou/p/12398285.html创建好了数据集,将它上传到谷歌colab 在colab上的目录如下: 在utils中的rdat ...
- kaggle之猫狗数据集下载
链接:https://pan.baidu.com/s/1l1AnBgkAAEhh0vI5_loWKw 提取码:2xq4 百度网盘实在是恶心,找的别人的网盘下载不仅速度慢,还老挂掉,自己去kaggle下 ...
随机推荐
- 【Vue 学习笔记 一、Vue开发环境搭建】
搭建Vue的开发环境 1.首先安装Nodejs (因为我的系统是Windows的所以就选择第一个了,这个看个人的开发环境) 下载好后,然后一路确定,如果有更改安装目录的需求,就自己切换安装目录,由于 ...
- python2下经典爬虫(第一卷)
python2.7的爬虫个人认为比较经典在此我将会用书中的网站http://example.webscraping.com作为案例 爬虫第一步:进行背景调研 了解网站的结构资源在网站的robots.t ...
- leetcode 1.回文数-(easy)
2019.7.11leetcode刷题 难度 easy 题目名称 回文数 题目摘要 判断一个整数是否是回文数.回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数. 思路 一些一定不为回文数的 ...
- 很全很全的 JavaScript 模块讲解
模块通常是指编程语言所提供的代码组织机制,利用此机制可将程序拆解为独立且通用的代码单元.所谓模块化主要是解决代码分割.作用域隔离.模块之间的依赖管理以及发布到生产环境时的自动化打包与处理等多个方面. ...
- Apollo配置中心介绍与使用指南
转载于https://github.com/ctripcorp/apollo,by Ctrip, Inc. Apollo配置中心介绍 Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中 ...
- 使用Commons Logging
Commons Logging 和Java标准库提供的日志不同,Commons Logging是一个第三方日志库,它是由Apache创建的日志模块,需要导入commons-logging-1.2.ja ...
- 在python中使用json
在服务器和客户端的数据交互的时候,要找到一种数据格式,服务端好处理,客户端也好处理,这种数据格式应该是一种统一的标准,不管在哪里端处理起来都是统一的,现在这种数据格式非常的多,比如最早的xml,再后来 ...
- Redis 安装及入门
Redis简介 Redis是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语言的API. Docker方式安装Redis # 拉取 r ...
- paxos算法学习总结
核心思想 分布式系统架构下如何让整体尽快达成一致观点,也就是多个不同观点收敛到一个观点的过程. 难点 可能会发生少数节点故障,但绝不是大面积故障,不然系统也没法正常工作. 由于存在单点故障,因此不可能 ...
- Jupyter自定义设置详解
今天专门花时间总结梳理一下jupyter的一些高级设置,jupyter我已经介绍过一次基本内容了,Setup and Linux | James Chen's Blogs,尤其是如何在服务器运行jup ...