ElasticSearch之映射常用操作

本文案例操作,建议先阅读我之前的文章《ElasticSearch之安装及基本操作API》
Mapping (映射)类似关系型数据库中的表的结构定义。我们将数据以 JSON 格式存入到 ElasticSearch 中后,在搜索引擎中 JSON 字段映射对应的类型,这时需要 mapping 来定义内容的类型。
字段类型
JSON 数据类型映射到 ElasticSearch 定义的类型,常用的简单类型有:
| JSON类型 | ElasticSearch 类型 |
|---|---|
| 文本类型 | Text/Keyword |
| 整数类型 | long/integer |
| 浮点类型 | float/double |
| 时间类型 | date |
| 布尔值 | boolean |
| 数组 | Text/Keyword |
上面要注意的是时间类型,JSON 中并没有时间类型,这里主要指时间格式数据的类型。
定义映射
在关系型数据库中,存储数据之前,我们会先创建表结构,给字段指定一个存在的类型。同样 ElasticSearch 在进行数据存储前,也可以先定义好存储数据的 Mapping 结构。
先定义一个简单的 person Mapping:
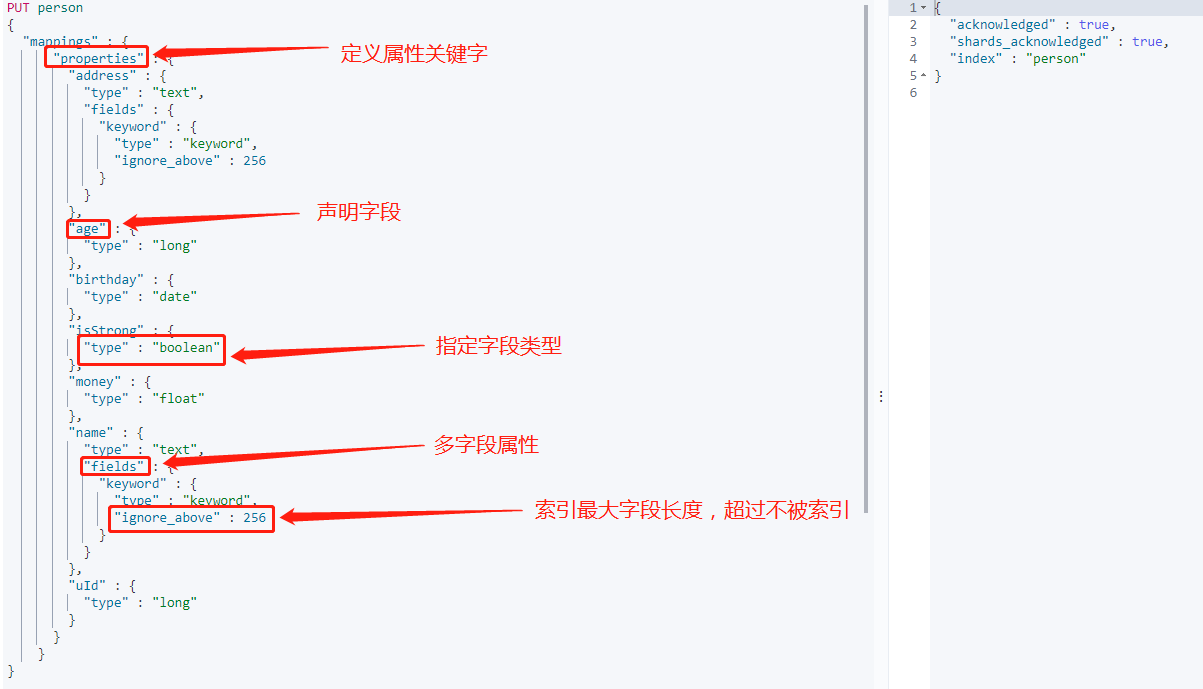
上图中就是一个 Mapping 的定义,如果是在 ElasticSearch7 之前,mappings 里还有 _type 属性。
动态映射
当没有事先定义好 Mapping,添加数据时,ElasticSearch 会自动根据字段进行换算出对应的类型,但是换算出来的类型并不一定是我们想要的字段类型,还是需要人为的干预进行修改成想要的 Mapping。
更新映射
使用 dynamic 控制映射是否可以被更新。
dynamic-true
设置 dynamic 为true是默认 dynamic 的默认值,新增字段数据可以写入,同时也可以被索引,Mapping 结构也会被更新。

添加数据,同时多添加一个没被定义的 gender 字段。
# 向 person 中添加数据
PUT person/_doc/1
{
"uId": 1,
"name": "ytao",
"age": 18,
"address": "广东省珠海市",
"birthday": "2020-01-15T12:00:00Z",
"money": 108.2,
"isStrong": true,
"gender": "男" # Mapping 中未定义的字段
}
添加成功,搜索 gender 字段:
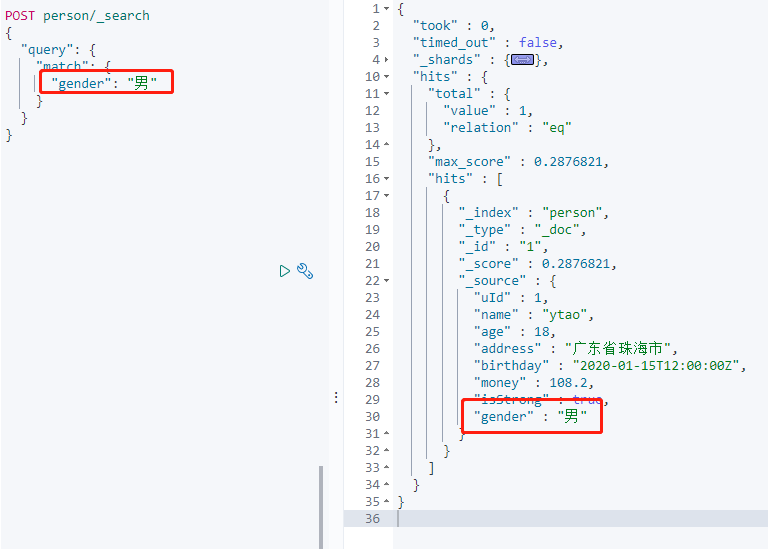
查看 Mapping 结构:
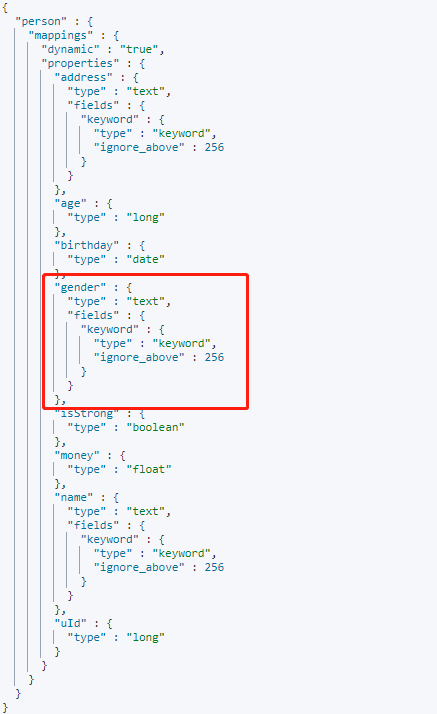
新添加的字段值,在添加过程中 Mapping 已自动添加字段。
dynamic-false
设置 dynamic 为false时,新增字段数据可以写入,不可以被索引,Mapping 结构会被更新。
同样先将 dynamic 设置为 false,然后向里面添加数据,其他步骤和上面 true 操作一样。定义 Mapping,添加数据。
搜索 gender 字段:

此时新增字段数据无法被索引,但数据可以写入。
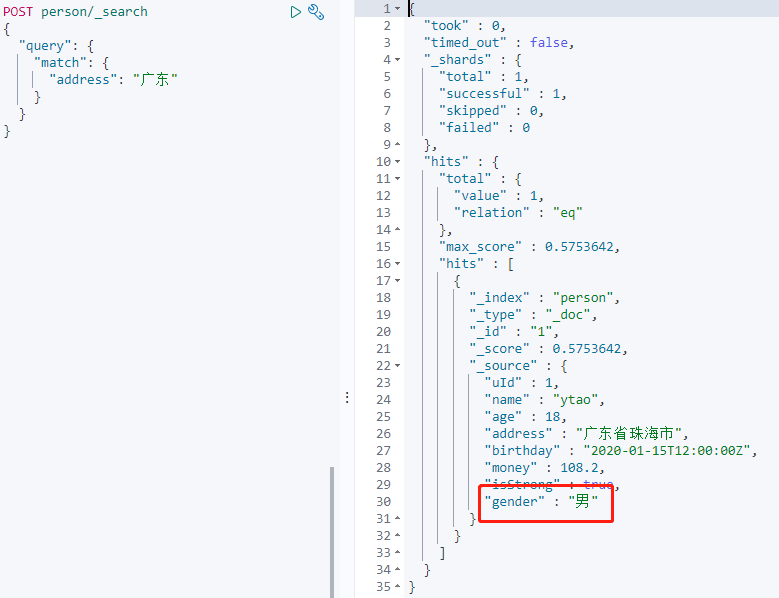
Mappnig 也不会添加新增的字段:
dynamic-strict
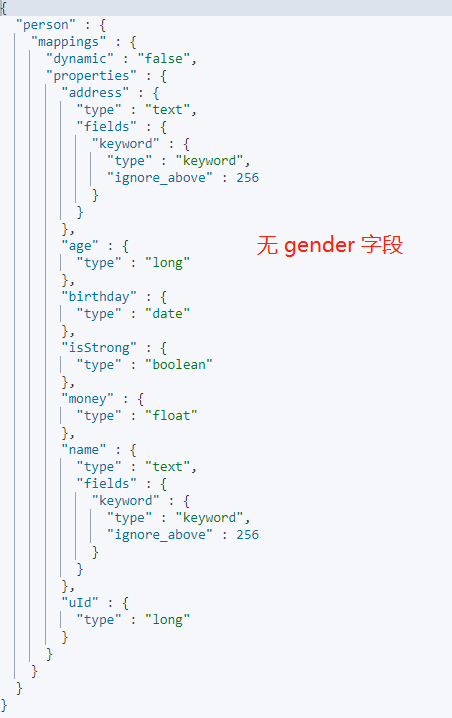
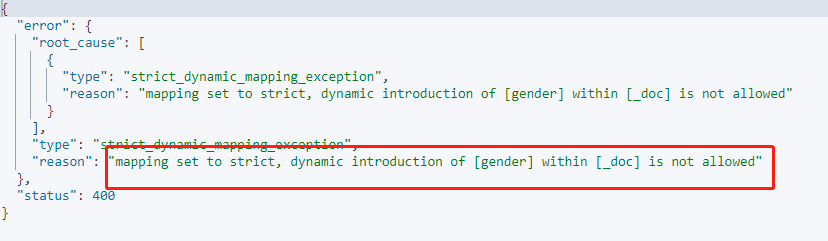
设置 dynamic 为strict时,从字面上意思也可以看出,对于动态映射是较严格的,新增字段数据不可以写入,不可以被索引,Mapping 结构不会被更新。只能按照定义好的 Mapping 结构添加数据。
在添加新字段数据时,就马上会抛出异常:
自动识别日期类型
上文中,当 dynamic 设置为 true 时,添加新字段数据自动识别类型更新 Mapping,如果是日期类型的话,我们是可以指定识别的类型。
指定 person 的 dynamic_date_formats 格式:
PUT person/_mapping
{
"dynamic_date_formats": ["yyyy/MM/dd"]
}
这里是可以指定多个时间格式。
向 person 添加新数据,分别是 today 和 firstDate:
PUT person/_doc/2
{
"today": "2020-01-15",
"firstDate": "2020/01/15"
}
添加新字段数据后的 Mapping:
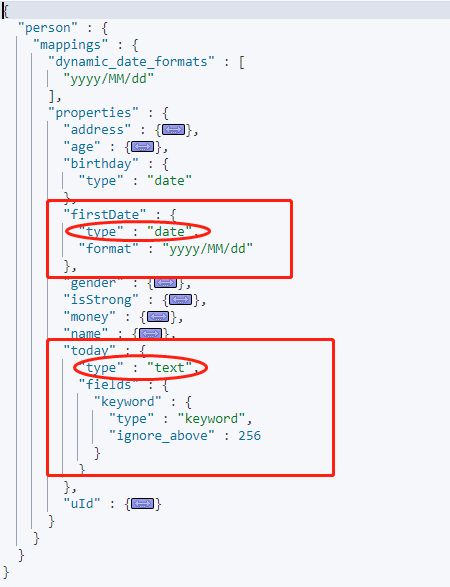
由于上面我们指定了时间格式为 yyyy/MM/dd 时是可以识别为时间格式,所以 today 字段的值为 yyyy-MM-dd 格式无法识别为时间类型,判为 text 类型。
多字段
Mapping 中可以定义 fields 多字段属性,以满足不同场景下的实现。比如 address 定义为 text 类型,fields 里面又有定义 keyword 类型,这里主要是区分两个不同不同使用场景。
text会建立分词倒排索引,用于全文检索。keyword不会建立分词倒排索引,用于排序和聚合。
添加数据:
# 向 person 中添加数据
PUT person/_doc/1
{
"uId": 1,
"name": "ytao",
"age": 18,
"address": "广东省珠海市",
"birthday": "2020-01-15T12:00:00Z",
"money": 108.2,
"isStrong": true
}
查询address数据。

查询address.keyword数据。
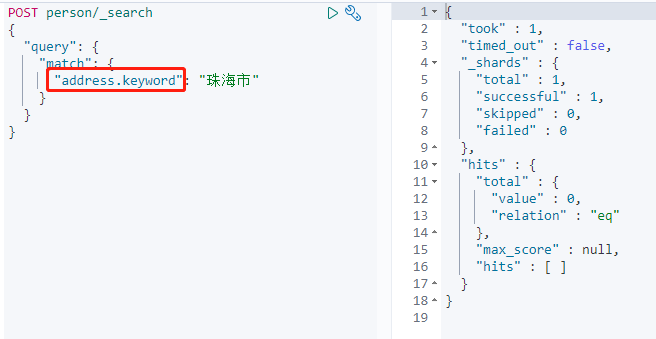
通过keyword检索时,由于不会建立分词索引,并没有获取到数据。
控制索引
在字段中使用 index 指定当前字段索引是否能被搜索到。指定类型为 boolean 类型,false 为不可搜索到,true 为可以搜索到。
先删除之前的 Mapping:
DELETE person
创建 Mapping,设置name属性的 index 为 false。
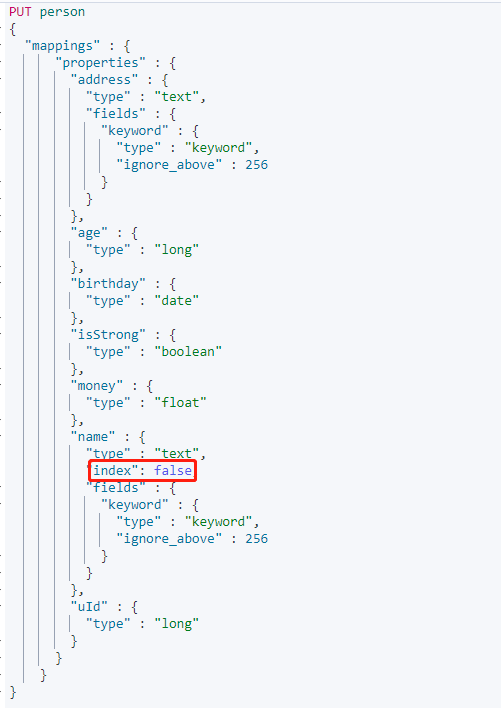
再次添加上面的数据后搜索name字段:
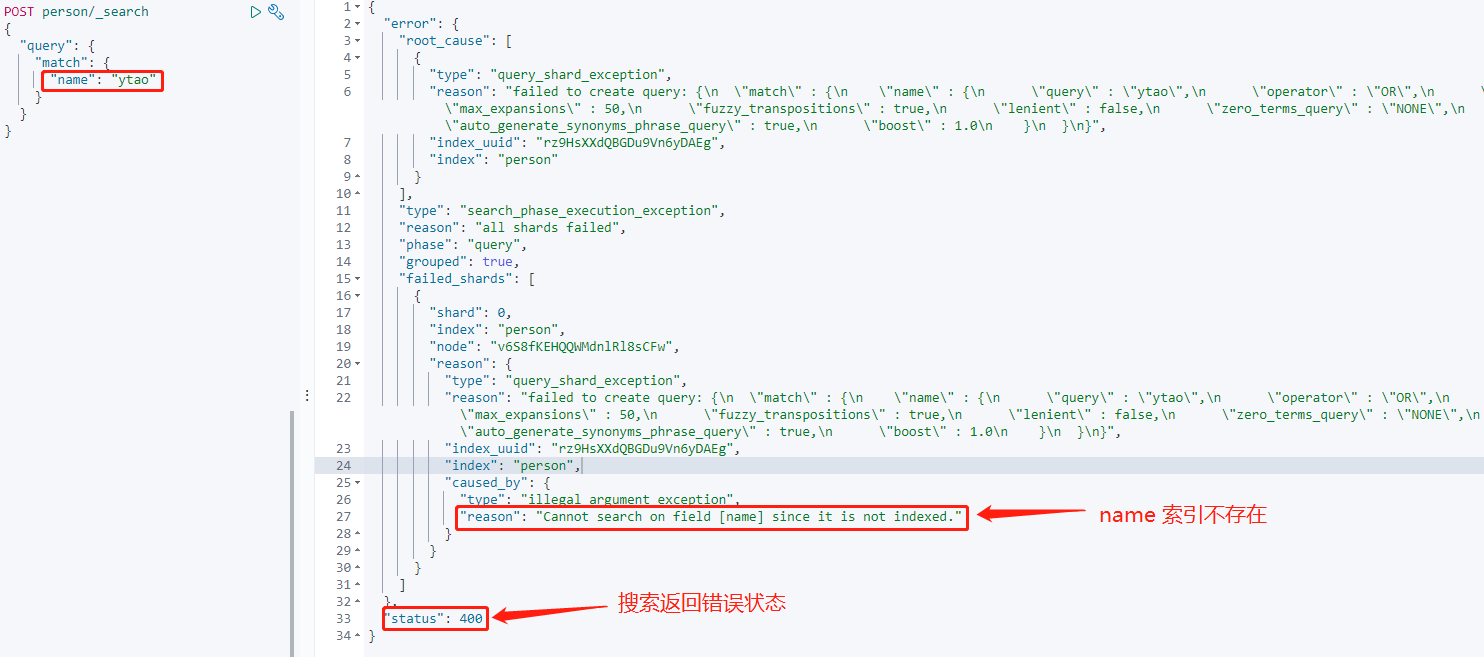
字段 index 设置 false 后,由于没有被索引,所以搜索无法获取到索引。
空值处理
现在向 ElasticSearch 中添加一条 address 为空的数据:
PUT person/_doc/2
{
"uId": 2,
"name": "Jack",
"age": 22,
"address": null,
"birthday": "2020-01-15T12:00:00Z",
"money": 68.7,
"isStrong": true
}
搜索 address.keyword 为空的数据:
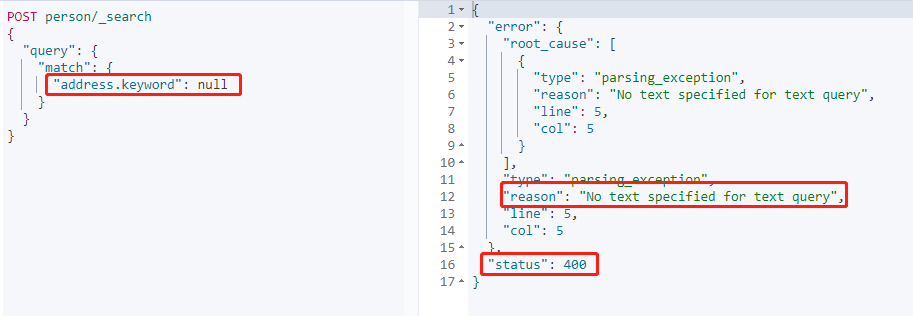
搜索返回异常,默认是不被允许搜索 NUll。
这是需要在 Mapping 指定 null_value 属性,并且不能在text类型中声明。
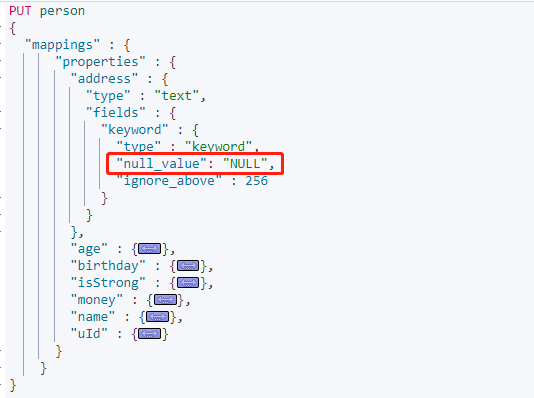
搜索 address.keyword 为空的数据:
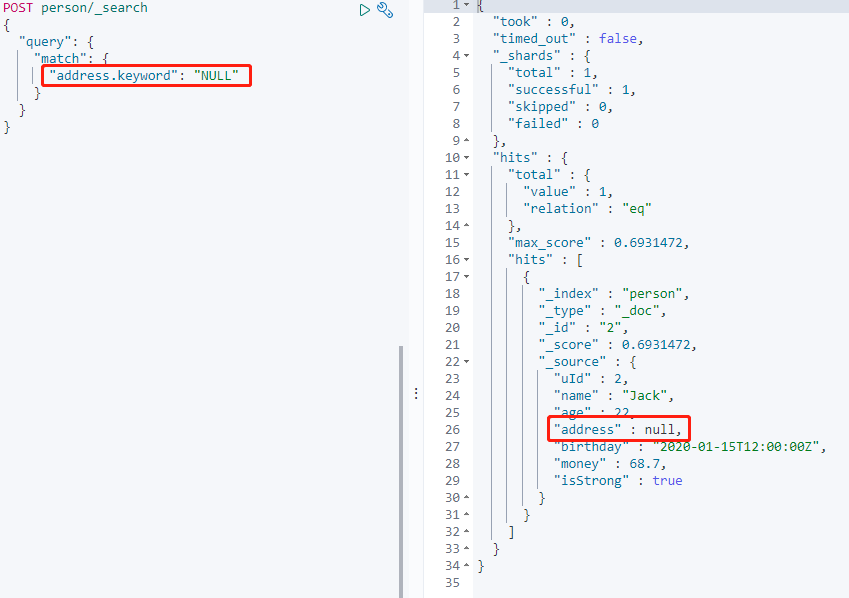
设置 "null_value": "NULL" 后,空值可以处理搜索。
聚合多个字段
聚合多个字段放到一个索引中,使用 copy_to 进行聚合。例如我们在多字段查询中,这是不需要对每个字段进行过滤筛选,只需对聚合字段即可。
在使用 copy_to 时,是通过指定聚合的名称实现。
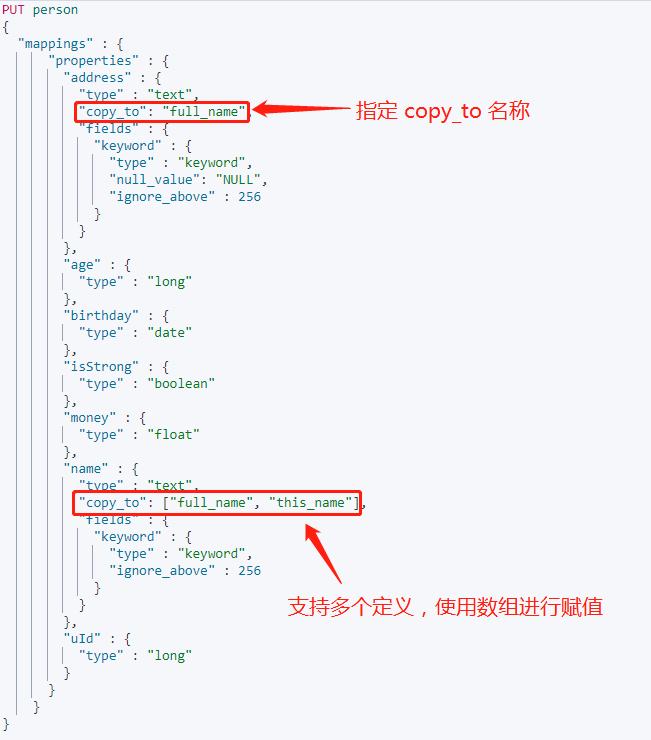
实际上,copy_to 不使用数组格式添加名称,也会自动转换成数据格式。
添加两条数据,待校验搜索:
# 向 person 中添加数据
PUT person/_doc/1
{
"uId": 1,
"name": "ytao",
"age": 18,
"address": "广东省珠海市",
"birthday": "2020-01-15T12:00:00Z",
"money": 108.2,
"isStrong": true
}
PUT person/_doc/2
{
"uId": 2,
"name": "杨广东",
"age": 22,
"address": null,
"birthday": "2020-01-15T12:00:00Z",
"money": 68.7,
"isStrong": true
}
查询 full_name 的值,会返回 name 和 address 相关的值的对象。
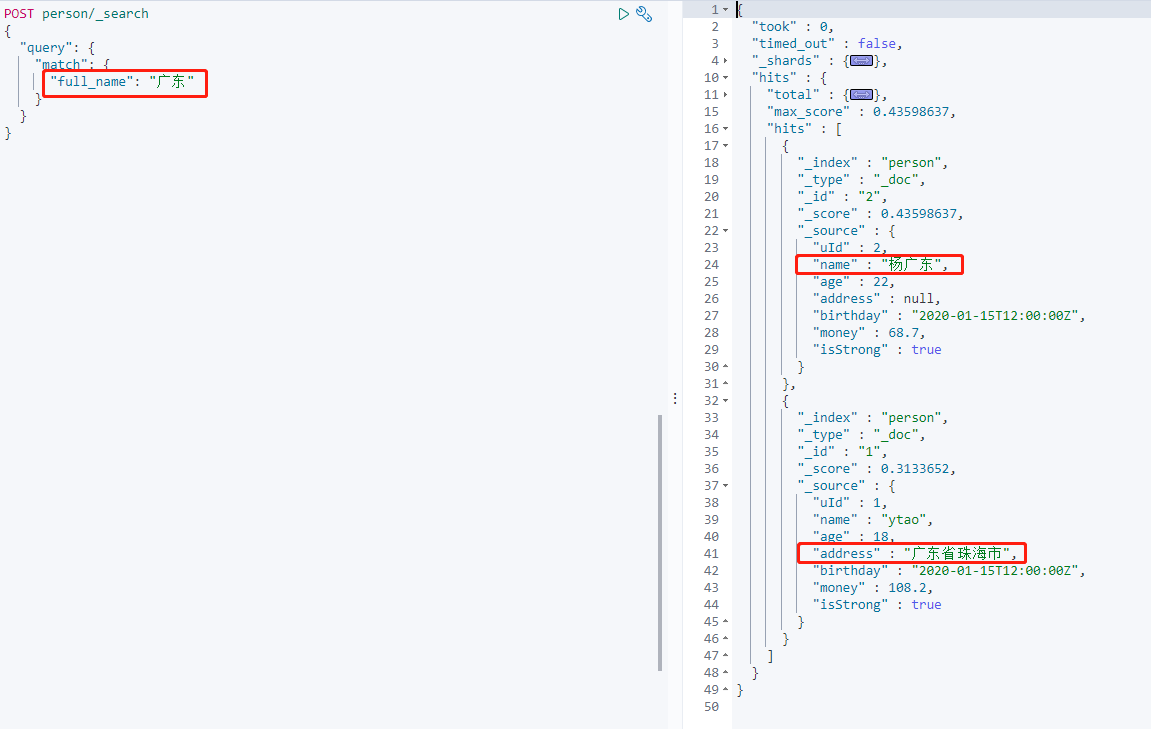
从上面返回结果看到,_source 中的字段没有增加相应的 copy_to 字段名,所以 copy_to 只会拷贝字段内容至索引,并不会改变包含的字段。
总结
通过本文对创建 Mapping 文件的常用并且实用的操作介绍,也基本能掌握这些日常的使用。了解 Mapping 的功能操作,相信对存储时的设计也有一定帮助。
个人博客: https://ytao.top
关注公众号 【ytao】,更多原创好文

ElasticSearch之映射常用操作的更多相关文章
- Elasticsearch(Transport Client)常用操作
这里描述操作elasticsearch采用TransportClient这种方式,官方明确表示在ES 7.0版本中将弃用TransportClient客户端,且在8.0版本中完全移除它. 记录一些常用 ...
- Elasticsearch本地环境安装和常用操作
本篇文章首发于我的头条号Elasticsearch本地环境安装和常用操作,欢迎关注我的头条号和微信公众号"大数据技术和人工智能"(微信搜索bigdata_ai_tech)获取更多干 ...
- Elasticsearch(ES)API 增删查改常用操作
常用操作 查询所有数据 POST http://192.168.97.173:27009/logstash_test_2018/doc/_search { "query": { & ...
- elasticsearch要点及常用查询
目录 elasticsearch要点及常用查询 查询与过滤 明确查询和过滤各自的优缺点,以及适用场景. 性能上的差异 适用场景 1.kibana 中操作es-查询 Mapping映射基础 mappin ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作(二)
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作
http://www.cnblogs.com/wgp13x/p/4934521.html 内容一样,样式好的版本. 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据 ...
- vim常用操作技巧与配置
vi是linux与unix下的常用文本编辑器,其运行稳定,使用方便,本文将分两部分对其常用操作技巧和配置进行阐述,其中参考了网上的一些文章,对作者表示感谢 PART1 操作技巧 说明: 以下的例子中 ...
- python数据类型:字典dict常用操作
字典是Python语言中的映射类型,他是以{}括起来,里面的内容是以键值对的形式储存的: Key: 不可变(可哈希)的数据类型.并且键是唯一的,不重复的. Value:任意数据(int,str,boo ...
- 关于vim的常用操作
vim常用操作和使用技巧 vi是linux与unix下的常用文本编辑器,其运行稳定,使用方便,本文将分两部分对其常用操作技巧和配置进行阐述,其中参考了网上的一些文章,对作者表示感谢 PART1 操作技 ...
随机推荐
- inventor安装未完成,某些产品无法安装的解决方法
inventor提示安装未完成,某些产品无法安装该怎样解决呢?,一些朋友在win7或者win10系统下安装inventor失败提示inventor安装未完成,某些产品无法安装,也有时候想重新安装inv ...
- yum命令不能使用的解决办法
以前yum命令一直是可用的,今天使用它安装命令时一直提示,如下图: 百度了一圈说是网络问题: 然后我就ping www.baidu.com 可以ping通啊 最后在同事的帮助下找到了解决办法: vi ...
- IOS下的safari下localStorage不起作用的问题
我们的一个小应用,使用百度地图API获取到用户的坐标之后用localStorage做了下缓存,测试上线之后有运营同学反馈页面数据拉取不到, 测试的时候没有发现问题,而且2台相同的iphone一台可以一 ...
- MySQL数据类型(DATA Type)与数据恢复与备份方法
一.数据类型(DATA Type)概述 MySQL支持多种类型的SQL数据类型:数字类型,日期和时间类型,字符串(字符和字节)类型以及空间类型 数据类型描述使用以下约定: M表示整数类型的最大显示宽度 ...
- MyBatis连接MySQL8配置
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</a ...
- Linux IO多路复用
监听文件描述符的状态来进行相应的读写操作,3个函数: 123 selectpollepoll 123456789 int (int nfds, fd_set *readfds, fd_set *wri ...
- Gnome Ubuntu16安装Nvidia显卡396驱动,CUDA9.2以及cudnn9.2
深度学习环境配置,安装Nvidia显卡驱动,CUDA以及cudnn OS:ubuntu 16.04;driver: nvidia 396;CUDA: 9.2cudnn: 9.2 卸载原有Nvidia驱 ...
- 神侃:反向激励能救活多少APP?
在很多宣扬互联网企业成功的宣传文案中,为了将其包装地更大高大上和有逼格,总是会将各种心理学术名词用上,以显示自己对市场.用户群体的观察入微.当然事实上所谓的心理学术名词,都是"马后炮&q ...
- ZYNQ自定义AXI总线IP应用——PWM实现呼吸灯效果
一.前言 在实时性要求较高的场合中,CPU软件执行的方式显然不能满足需求,这时需要硬件逻辑实现部分功能.要想使自定义IP核被CPU访问,就必须带有总线接口.ZYNQ采用AXI BUS实现PS和PL之间 ...
- Spring常见注解
@Autowired @Resource @Component:类加上@Component注解,即表明此类是bean @Aspect 注解表示这是一个切面 @Around(value = " ...