粒子群优化算法(PSO)之基于离散化的特征选择(FS)(二)
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习、深度学习的知识!
作者:Geppetto
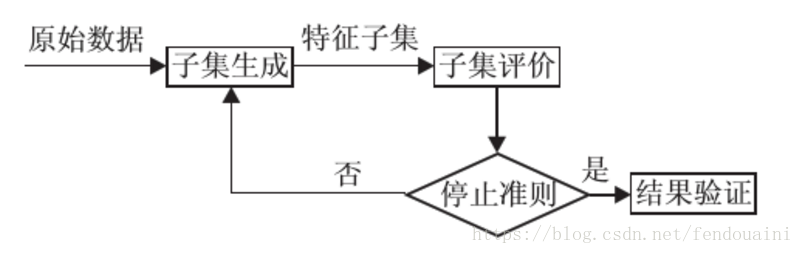
前面我们介绍了特征选择(Feature Selection,FS)与离散化数据的重要性,总览的介绍了PSO在FS中的重要性和一些常用的方法。今天讲一讲FS与离散化的背景,介绍本文所采用的基于熵的切割点和最小描述长度原则(MDLP)。
A.特征选择
特征选择是一个组合优化问题,因为在具有N个特征的数据集上有2N个可能的不同特征子集。FS方法通常有两个重要的部分组成,即搜索技术和特征评估方法。
在特征评估方面,FS方法通常可以分为过滤(filter)和包装(wrapper)方法。过滤法基于它们的内在特性来评估特性。过滤措施的例子有距离、信息增益、一致性和相关性。另一方面,包装法使用一种学习算法来度量所选特性的分类性能。在这个过程中可以使用不同的学习算法,比如k近邻(KNN)、决策树和支持向量机。一般来说,过滤器方法比包装器方法更快,然而,它们通常比包装器获得更低的分类精度。
在FS方法中搜索技术可以分为穷举搜索、启发式搜索、随机搜索和随机搜索。虽然穷举搜索保证找到最好的解决方案,但是由于它的计算时间太高,对大多数实际应用程序来说是不可行的。序列搜索如线性正向选择(LFS)和贪婪逐步逆向选择(GSBS)是启发式搜索的典型方法。这两种方法分别是序列正向选择(SFS)和序列逆向选择的派生版本。LFS通过限制每个步骤中考虑的特性的数量来提高SFS的有效性和效率。虽然向后选择可以考虑特性交互,而不是向前选择,但是对具有大量特性的数据集应用是不切实际的。GSBS不能在一个星期内完成,它运行在具有数百个特征的数据集上。另外,前后策略通常都要面对局部最优的问题。
随机搜索可能会以一种完全随机的方式生成子集,使用Las Vegas算法,比如LVW,在一个大的搜索空间中,它的收敛速度太慢。与随机生成不同,EC是一种随机的方法,它应用进化原理或群智能来从当前的子集生成更好的子集。PSO是一种应用于FS的群体智能技术,并显示了其有效性。大家可以通过使用EC技术对FS的不同策略进行更全面的调查。虽然PSO已经成功地应用于不同的优化问题,包括FS,但它还没有应用于离散化。
B.特征离散化
特征离散化是一个研究历史悠久的话题。在此领域提出了许多不同策略的离散化方法。但是,它们都具有相同的目的,即确定将特征值分割为离散值的分割点。在特征值的范围内,分割点或分点是真正的值,这些值被用来分割这个范围到若干个间隔。现有的离散化方法可以使用不同的标准进行分类。在直接方法中,间隔是基于预定义的参数生成的。另一方面,增量方法递归地分离(或合并)间隔,直到满足一些标准,从而产生分裂(或合并)方法。它们也被称为自顶向下或自底向上的方法。根据是否在离散化过程中使用类标签,对离散化方法进行监督或无监督。如果在每个离散化步骤中使用整个实例空间,或者如果每个离散步骤只使用一个实例子集,那么它将是全局的。一种方法也属于单变量或多变量,这取决于特征是离散的还是多个特性的离散化,同时考虑特征之间的交互。
等宽和等频是两种简单的无监督方法。它们将特性离散为一个预定义的m间隔,具有相同的宽度或相同数量的值。这些简单的方法易于实现,但对m的值敏感,通常很难确定,尤其是当特性不是均匀分布或包含异常值时。
使用类标签作为搜索切割点的引导,监督离散化通常比无监督的匹配要好。在不同的类的边界上定义了切点的特征值。除了不同的搜索技术,还有分类错误率、信息增益和统计度量等不同的评价方法。
在受监督的方法中,Fayyad和Irani提出的最小描述长度(MDL)是最常用的方法之一。它是一种基于熵的增量分割离散化方法。利用信息增益来评价候选点。MDL递归地选择最佳的切点,将一个间隔分割为两个,直到实现MDLP。受此策略启发,我们建议使用由MDLP所接受的基于熵的切点作为BBPSO的初始或候选切入点。
C.基于熵的切割点
基于熵的离散化的目的是找到最佳的分割,以便离散化的特性在类标签上尽可能的纯粹。这意味着在一个区间内的大多数值都更倾向于具有相同的类标签。如果用熵E(S)来衡量集合S的纯度,那么根据这一标准,获得最高信息增益的切点是最好的。以下公式用于计算特征A的切点T的信息增益,作为特征值的集合。S1和S2是S分区的子集。
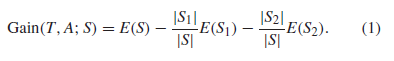
D.通过离散化来进行特征选择
虽然FS和离散化是近几十年来新兴的领域,但是结合这些任务的方法并没有引起足够的重视。Chi2是通过离散化提出FS的第一个方法。它是一种自下而上的方法,从只有一个特征值的间隔开始。然后相邻间隔χ2最低的测试结果将合并后的递归,直到χ2值对超过一个阈值。此阈值是通过试图维护数据的预定义一致性级别来确定的。通过释放这个一致性级别,Chi2可以提出只有一个间隔的特征,可以为FS移除。结果表明,在两个合成数据集上,Chi2有效地消除了相关特征,消除了所有的噪声特征。然而,用户定义的不一致率很难预先定义,也可能导致离散化过程的不准确。改进的Chi2 (MChi2)是一种完全自动的离散化方法,解决了Chi2的缺点。
另一种通过离散化的方法是基于离散化过程中计算出的一些度量方法进行排序。然后,将选择一些级别最高的特征。这个方法的一个例子是PEAR,其中的特性是从最小的切点数量到最大的。顶级的特征被认为是相关的,并被选择形成最终的子集。结果表明,该算法具有与原特性集相似的性能,且效果较好。但是,很难为PEAR选择合适的参数,以及应该选择哪些特性来形成最终子集。同样,特征根据原始连续值的方差和用于编码离散特征的比特数的比值进行排序。
综上所述,通过离散化的特征选择在两个不同的阶段。但是,将他们整合到同一个阶段的研究目前还没有。
E.粒子群优化算法
具体可参考本人文章“计算智能(CI)之粒子群优化算法(PSO)”。本篇文章将不再赘述。
参考文献:
文章:“A New Representation in PSO for Discretization-Based Feature Selection”
作者:Binh Tran, Student Member, IEEE, Bing Xue, Member, IEEE, and Mengjie Zhang, Senior Member, IEEE
本篇文章出自http://www.tensorflownews.com,对深度学习感兴趣,热爱Tensorflow的小伙伴,欢迎关注我们的网站!
粒子群优化算法(PSO)之基于离散化的特征选择(FS)(二)的更多相关文章
- 粒子群优化算法(PSO)之基于离散化的特征选择(FS)(一)
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 作者:Geppetto 在机器学习中,离散化(Discretiza ...
- 粒子群优化算法(PSO)之基于离散化的特征选择(FS)(三)
作者:Geppetto 前面我们介绍了特征选择(Feature Selection,FS)与离散化数据的重要性,总览的介绍了PSO在FS中的重要性和一些常用的方法,介绍了FS与离散化的背景,介绍本文所 ...
- 粒子群优化算法(PSO)之基于离散化的特征选择(FS)(四)
作者:Geppetto 前面我们介绍了特征选择(Feature Selection,FS)与离散化数据的重要性,介绍了PSO在FS中的重要性和一些常用的方法.FS与离散化的背景,介绍了EPSO与PPS ...
- 粒子群优化算法PSO及matlab实现
算法学习自:MATLAB与机器学习教学视频 1.粒子群优化算法概述 粒子群优化(PSO, particle swarm optimization)算法是计算智能领域,除了蚁群算法,鱼群算法之外的一种群 ...
- 数值计算:粒子群优化算法(PSO)
PSO 最近需要用上一点最优化相关的理论,特地去查了些PSO算法相关资料,在此记录下学习笔记,附上程序代码.基础知识参考知乎大佬文章,写得很棒! 传送门 背景 起源:1995年,受到鸟群觅食行为的规律 ...
- 粒子群优化算法(PSO)的基本概念
介绍了PSO基本概念,以及和遗传算法的区别: 粒子群算法(PSO)Matlab实现(两种解法)
- MATLAB粒子群优化算法(PSO)
MATLAB粒子群优化算法(PSO) 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.介绍 粒子群优化算法(Particle Swarm Optim ...
- ARIMA模型--粒子群优化算法(PSO)和遗传算法(GA)
ARIMA模型(完整的Word文件可以去我的博客里面下载) ARIMA模型(英语:AutoregressiveIntegratedMovingAverage model),差分整合移动平均自回归模型, ...
- 计算智能(CI)之粒子群优化算法(PSO)(一)
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 计算智能(Computational Intelligence , ...
随机推荐
- 压力测试(八)-多节点JMeter分布式压测实战
1.Jmeter4.0分布式压测准备工作 简介:讲解Linux服务器上jmeter进行分布式压测的相关准备工作 1.压测注意事项 the firewalls on the systems are tu ...
- 浅析TCP/IP协议
浅析TCP/IP协议 0x00 什么是TCP/IP协议? 想一想人与人之间交流需要什么?我们是不是要掌握一种我们都能体会到对方意思的语言.那么计算机与网络设备之间进行通信,是不是不同设备之间是不是 ...
- FC及BFC
1.什么是FC 2.BFC块级格式化上下文(Block formatting context) Box 是 CSS 布局的对象和基本单位, 直观点来说,就是一个页面是由很多个 Box 组成的.元素的类 ...
- 在浏览器中使用ES6的模块功能 import 及 export
感谢英文原作者 Jake Archibald 的技术分享 各个浏览器对于ES6模块 import . export的支持情况 Safari 10.1. Chrome 61. Firefox 54 – ...
- 高性能MySQL之锁详解
一.背景 MySQL里面的锁大致可以分成全局锁.表级锁和行锁三类.数据库锁的设计的初衷是处理并发问题.我们知道多用户共享资源的时候,就有可能会出现并发访问的时候,数据库就需要合理的控制资源的访问规则, ...
- Eight II HDU - 3567
Eight II Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 130000/65536 K (Java/Others)Total S ...
- web前端问题整理
1.常用那几种浏览器测试?有哪些内核(Layout Engine)? (Q1)浏览器:IE,Chrome,FireFox,Safari,Opera (Q2)内核:Trident,Gecko,Prest ...
- 复制url事故:出现特殊的字符%E2%80%8B
复制url事故:出现特殊的字符%E2%80%8B 问题:直接其他地方复制过来的中文字进行网页搜索.或者中文字识别排序等情况的,会出现搜索不到的情况. 解决方法:可能存在复制源里面的文字带了空白url编 ...
- 操作系统-schedule函数
1. Linux 0.11的调度函数schedule() 也就是找到了counter最大的进程,然后就跳出去执行switch_to,对应上面的优先级算法,而counter本身也是时间片,也作了轮转调度 ...
- Flutter Form表单控件超全总结
注意:无特殊说明,Flutter版本及Dart版本如下: Flutter版本: 1.12.13+hotfix.5 Dart版本: 2.7.0 Form.FormField.TextFormField是 ...