python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)
现在我们现在一个分机上引入一个SCRAPY的爬虫项目,要求数据存储在MONGODB中
现在我们需要在SETTING.PY设置我们的爬虫文件
再添加PIPELINE

注释掉的原因是爬虫执行完后,和本地存储完毕还需要向主机进行存储会给主机造成压力
设置完这些后,在MASTER主机开启REDIS服务,将代码复制放在其它主机中,注意操作系统类型以及配置
然后分别在各个主机上进行爬取,爬取速度加大并且结果不同

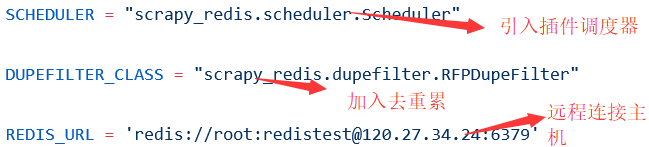
setting中加入这个可以保证爬虫不会被清空

设置这个决定重新爬取时队列是否清空,一般都用FALSE
我们现在是否分别到主机上执行爬取,现在我想直接在一台主机上控制所有的爬虫程序,现在引入SCRAPYD,他会启动WEB服务来管理所有的项目
看下步骤
1启动SCRAPYD
2可以远程访问
3运用SCPRAPYD-CLIENT来打包项目
4修改爬虫的scrapy.cfg文件
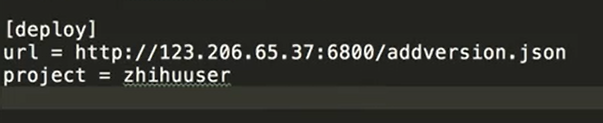
将地址改为远程的SCRAPYD服务地址
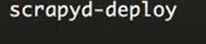
执行此命令完成部署

开启一个远程进程
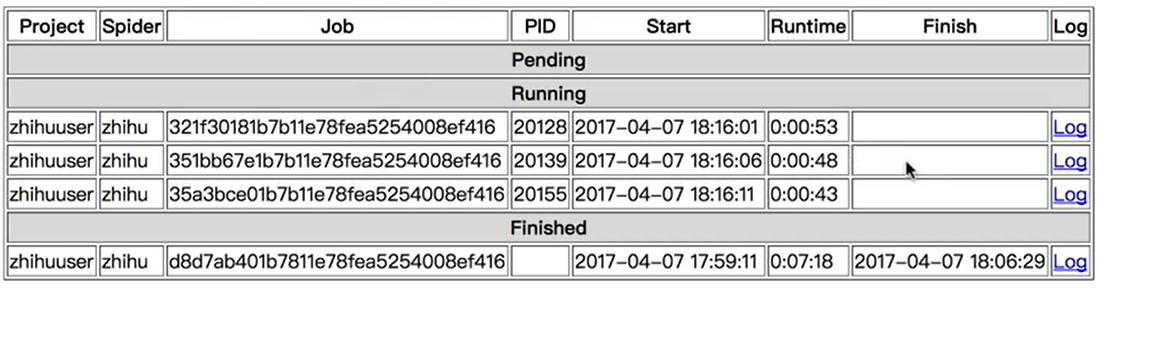
开几条指令,执行几条进程,每一个JOB都个ID如果是多个机器的任务那么ID则不同
python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)的更多相关文章
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- 21天打造分布式爬虫-Spider类爬取糗事百科(七)
7.1.糗事百科 安装 pip install pypiwin32 pip install Twisted-18.7.0-cp36-cp36m-win_amd64.whl pip install sc ...
- 21天打造分布式爬虫-Crawl类爬取小程序社区(八)
8.1.Crawl的用法实战 新建项目 scrapy startproject wxapp scrapy genspider -t crawl wxapp_spider "wxapp-uni ...
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- 21天打造分布式爬虫-Selenium爬取拉钩职位信息(六)
6.1.爬取第一页的职位信息 第一页职位信息 from selenium import webdriver from lxml import etree import re import time c ...
- 21天打造分布式爬虫-requests库(二)
2.1.get请求 简单使用 import requests response = requests.get("https://www.baidu.com/") #text返回的是 ...
- 21天打造分布式爬虫-urllib库(一)
1.1.urlopen函数的用法 #encoding:utf-8 from urllib import request res = request.urlopen("https://www. ...
- python分布式爬虫打造搜索引擎--------scrapy实现
最近在网上学习一门关于scrapy爬虫的课程,觉得还不错,以下是目录还在更新中,我觉得有必要好好的做下笔记,研究研究. 第1章 课程介绍 1-1 python分布式爬虫打造搜索引擎简介 07:23 第 ...
随机推荐
- google docker镜像下载
https://anjia0532.github.io/2017/11/15/gcr-io-image-mirror/
- lvs和keepalived
LVS调度算法参考 RR:轮询 WRR :加权轮询 DH :目标地址哈希 SH:源地址hash LC:最少连接 WLC:加权最少连接,默认 SED:最少期望延迟 NQ:从不排队调度方法 LBLC:基于 ...
- maxima安装&使用
环境: mint 19 或者 > ubuntu 18 源代码安装的好处, 可以使用最新版. mint 19.1 下面, 利用apt 直接安装的maxima版本太老,不支持 draw 函数. lo ...
- SQL基础教程(第2版)第1章 数据库和SQL:练习题
CREATE TABLE Addressbook ( regist_no INTEGER NOT NULL, name ) NOT NULL, address ) NOT NULL, tel_no ) ...
- JS基础——脚本位置、数据类型、函数作用域
(一)脚本位置 JavaScript是嵌套到浏览器里的脚本语言:可放在3个位置: 1.写在头部(head里) <head> <meta charset="UTF-8& ...
- qt使用了qstackedwidget里面放置了widget后对该子widget设置的样式无效
关键字:子窗口样式无效 QStackedwidget 问题: 我有一个对话框,里面放了一个qstackedwidget,qstackedwidget放了N个子窗口,使用addwidget添加上去了: ...
- 调度算法FCFS、SJF和优先权调度的介绍和例题
调度算法 一.先来先服务FCFS (First Come First Serve) 1.思想: 选择最先进入后备/就绪队列的作业/进程,入主存/分配CPU 2.优缺点 优点:对所有作业/进程公平,算法 ...
- RaspBerry--解决无法用 ssh 直接以 root 用户登录
参考:https://www.cnblogs.com/xwdreamer/p/6604593.html 以普通用户登录,然后切换至 root 用户. 编辑 /etc/ssh/sshd_config 添 ...
- 【C#并发】00概述
摘自<C#并发编程经典实例>[美]Stephen Cleary 并发:同时做多件事情.终端用户利用并发功能,在输入数据库的同时相应用户输入.服务器应用并发,在处理第一个请求的同时响应第二个 ...
- c指针(1)
#include<stdio.h> void swap(int *a,int *b); void dummy_swap(int *a,int *b); int main() { ,d=; ...