【Python数据挖掘】第六篇--特征工程
一、Standardization
方法一:StandardScaler
from sklearn.preprocessing import StandardScaler
sds = StandardScaler()
sds.fit(x_train) x_train_sds = sds.transform(x_train)
x_test_sds = sds.transform(x_test)
方法二:MinMaxScaler 特征缩放至特定范围 , default=(0, 1)
from sklearn.preprocessing import MinMaxScaler
mns = MinMaxScaler((0,1))
mns.fit(x_train) x_train_mns = mns.transform(x_train)
x_test_mns = mns.transform(x_test)
二、Normalization 使单个样本具有单位范数的缩放操作。 经常在文本分类和聚类当中使用。
from sklearn.preprocessing import Normalizer
normalizer = Normalizer()
normalizer.fit(x_train) x_train_nor = normalizer.transform(x_train)
x_test_nor = normalizer.transform(x_test)
三、Binarization 特征二值化是将数值型特征变成布尔型特征。
from sklearn.preprocessing import Binarizer
bi = Binarizer(threshold=0.0) # 设置阈值默认0.0 大于阈值设置为1 , 小于阈值设置为0 XX = bi.fit_transform(x_train["xx"]) # shape (1行,X列)
x_train["XX"] = XX.T
# x_train["XX"] = XX[0,:]
四、连续性变量划分份数
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False)
x:array-like # 要分箱的数组
bin:int # 在x范围内的等宽单元的数量。
pd.cut(df["XXX"],5)
进行分箱操作后得到得值是字符串,还需要进行Encoding categorical features
五、one-hot Encoding / Encoding categorical features
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False) dummy_na=False # 是否把 missing value单独存放一列 pd.get_dummies(df , columns = ['xx' , 'xx' , ... ])
六、Imputation of missing values 缺失值处理
①、将无限大,无限小,Missing Value (NaN)替换成其他值;
②、sklearn 不接收包含NaN的值;
class sklearn.preprocessing.Imputer(missing_values='NaN', strategy='mean', axis=0, verbose=0, copy=True) strategy : (default=”mean”) # median , most_frequent
axis : (default=”0”) # 表示用列上所有值进行计算 from sklearn.preprocessing import Imputer
im =Imputer()
im.fit_transform(df['xxx'])
③、使用无意义的值来填充,如-999。
df.replace( np.inf , np.nan )
# 先用NaN值替换,再用-999填充NaN值。
df.fillna(-999)
df.fillna(-1) # 注意: -1与标准化的数值可能有意义关系
七、Feature selection 特征选择
①:基于 L1-based feature selection

from sklearn.linear_model import Lasso
lasso = Lasso()
lasso.fit(xdata,ydata) lasso.coef_ # 查看特征系数
array([ 1.85720489, 0. , -0.03700954, 0.09217834, -0.01157946,
-0.53603543, 0.72312094, -0.231194 , 1.26363755, -0. ,
0. , -0. , 0. , 0. , 0. ,
-0. , -0. , -0. , 0. , -0. ,
0. , 5.21977984, -0. , -0. , 7.00192208,
-0. , 0. , 0. , -0. ])
可以发现,经过One-hot Encod的变量都变成0 , 需要手工进一步筛选 , 不能去掉One-hot的变量 !
利用模型进行筛选的方法:
class sklearn.feature_selection.SelectFromModel(estimator, threshold=None, prefit=False) from sklearn.feature_selection import SelectFromModel
model = SelectFromModel(lasso,prefit=True)
x_new = model.transform(xdata)
②:基于 Tree-based feature selection
采用 Random Forests
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(xdata,ydata) rf.feature_importances_
array([ 8.76227379e-02, 4.41726855e-02, 2.12394498e-02,
1.98631826e-01, 1.75612945e-02, 6.72095736e-02,
4.25518536e-01, 3.50132246e-02, 7.23241098e-02, ... ]
非线性模型, 没有系数, 只有变量重要性!!!!
变量重要性大,放前面, 小的删除或者放后面
③:基于Removing features with low variance 移除所有方差不满足阈值的特征
class sklearn.feature_selection.VarianceThreshold(threshold=0.0) from sklearn.feature_selection import VarianceThreshold
v = VarianceThreshold(1)
v.fit_transform(xdata)
④:基于Univariate feature selection 单变量特征选择
1、SelectKBest 移除得分前 k 名以外的所有特征
class sklearn.feature_selection.SelectKBest(score_func=<function f_classif>, k=10) score_func : 统计指标函数
K : 个数
模型衡量指标:

导入相应的函数即可!
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
skb = SelectKBest(f_regression,k=10)
skb.fit_transform(xdata,ydata)
xdata.shape
2、移除得分在用户指定百分比以后的特征
class sklearn.feature_selection.SelectPercentile(score_func=<function f_classif>, percentile=10) score_func:采用统计指标函数
percentile:百分数
推荐使用 Feature importtance , Tree-base > L1-base > ... //
八、Dimensionality reduction 减少要考虑的随机变量的数量
方法一:PCA ,主成分分析 , 计算协方差矩阵
sklearn.decomposition.PCA(n_components=None, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', random_state=None)
# n_components : 设置留下来几列 from sklearn.decomposition import PCA
pca = PCA(15)
newdata = pca.fit_transform(xdata)
newdata.shape
univariate feature selection 与 PCA 区别:
1/ 计算每一个feature 统计量 , 然后选择前几个
2/ PCA 是考虑整个数据集 , 列与列存在关系 , 计算整个矩阵方差共线,
pca.explained_variance_ # 可解释的方差
pca.explained_variance_ratio_ # 百分比
注意:PCA 前先将数据进行标准化!!!
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
pca.fit_transform(ss.fit_transform(xdata))
方法二:TruncatedSVD
TruncatedSVD 原来N列 可以选择指定保留k列 , 降维
SVD 产生N*N矩阵 , 没有降维
sklearn.decomposition.TruncatedSVD(n_components=2, algorithm='randomized', n_iter=5, random_state=None, tol=0.0) n_components:int , 输出数据的期望维度。
九、思维导图
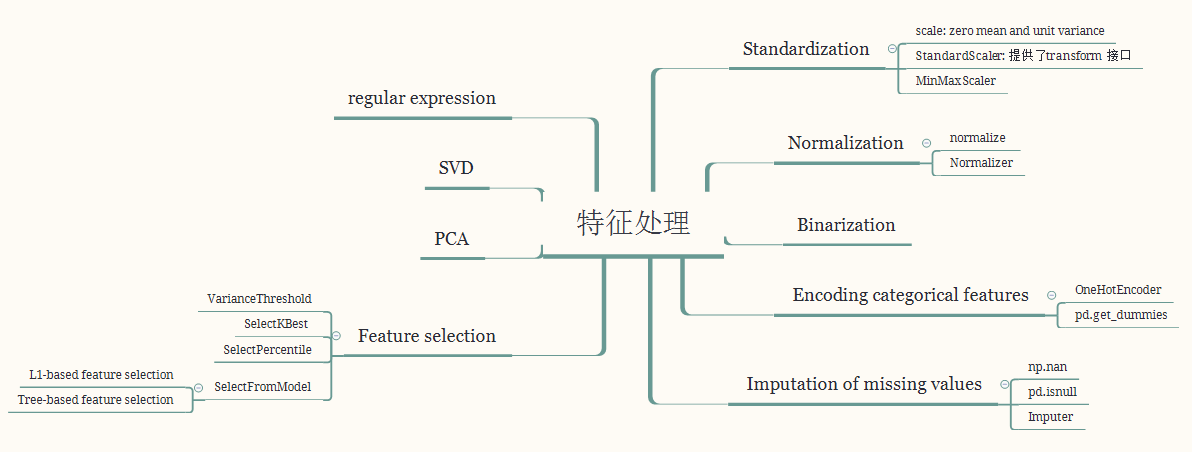
十、fit、fit_transform和transform的区别
我们使用sklearn进行文本特征提取/预处理数据。可以看到除训练,预测和评估以外,处理其他工作的类都实现了3个方法:fit、transform和fit_transform。
从命名中可以看到,fit_transform方法是先调用fit然后调用transform,我们只需要关注fit方法和transform方法即可。
transform方法主要用来对特征进行转换。从可利用信息的角度来说,转换分为无信息转换和有信息转换。
无信息转换是指不利用任何其他信息进行转换,比如指数、对数函数转换等。
有信息转换从是否利用目标值向量又可分为无监督转换和有监督转换。
无监督转换指只利用特征的统计信息的转换,统计信息包括均值、标准差、边界等等,比如标准化、PCA法降维等。
有监督转换指既利用了特征信息又利用了目标值信息的转换,比如通过模型选择特征、LDA法降维等。
通过总结常用的转换类,我们得到下表:
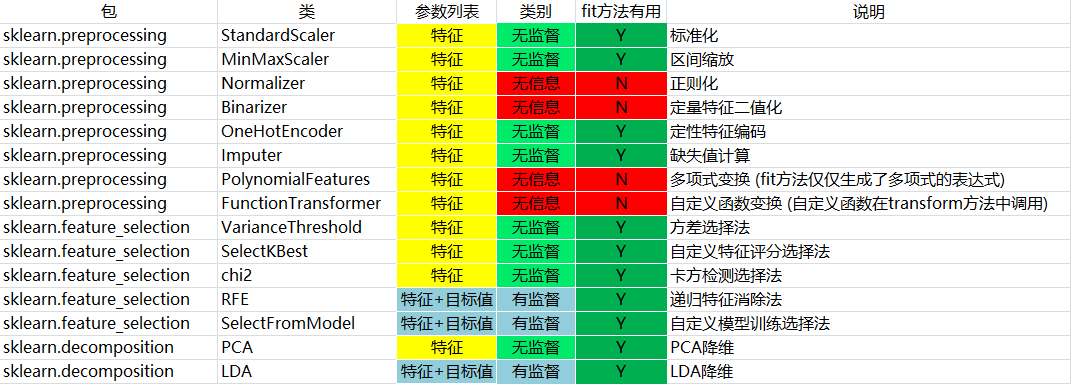
fit方法主要对整列,整个feature进行操作,但是对于处理样本独立的操作类,fit操作没有实质作用!
十一、特征工程选择
时间
空间
比率值
变化率





变化率例子: 10月 : (20% - 10%) / 10% = 100%
【Python数据挖掘】第六篇--特征工程的更多相关文章
- python数据挖掘第三篇-垃圾短信文本分类
数据挖掘第三篇-文本分类 文本分类总体上包括8个步骤.数据探索分析->数据抽取->文本预处理->分词->去除停用词->文本向量化表示->分类器->模型评估.重 ...
- python、第六篇:视图、触发器、事务、存储过程、函数
一 视图 视图是一个虚拟表(非真实存在),其本质是[根据SQL语句获取动态的数据集,并为其命名],用户使用时只需使用[名称]即可获取结果集,可以将该结果集当做表来使用. 使用视图我们可以把查询过程中的 ...
- [Python笔记]第六篇:文件处理
本篇主要内容:open文件处理函数的使用 open函数,该函数用于文件处理 操作文件时,一般需要经历如下步骤: 打开文件 操作文件 一.打开文件 文件句柄 = open('文件路径', '模式') 打 ...
- python基础-第六篇-6.2模块
python之强大,就是因为它其提供的模块全面,模块的知识点不仅多,而且零散---一个字!错综复杂 没办法,二八原则抓重点咯!只要抓住那些以后常用开发的方法就可以了,哪些是常用的?往下看--找答案~ ...
- 图解Python 【第六篇】:面向对象-类-进阶篇
由于类的内容比较多,分为类-初级基础篇和类-进阶篇 本节内容一览图: 一.类成员修饰符 每一个类的成员都有两种形式: 公有成员,在任何地方都能访问 私有成员,只能在类的内部才能访问 1.1.私有成员和 ...
- 【python自动化第六篇:面向对象】
知识点概览: 面向对象的介绍 面向对象的特性(class,object)实例变量,类变量 面型对象编程的介绍 其他概念 一.面向对象介绍 编程范式:面向对象,面向过程,函数式编程 面向过程:通过一组指 ...
- python【第六篇】面向对象编程
面向对象编程 一.编程范式:编程的方法论.程序员编程的“套路”及“特点”特点总结,抽象成方法.规范. 二.面向对象编程介绍: 1.描述 世界万物,皆可分类:世间万物,皆为对象:只要是对象,就肯定属于某 ...
- Python学习第六篇——字典中的键和值
favorite_language ={ "jen":"python", "sarah":"c", "edwa ...
- Python 学习 第六篇:迭代和解析
Python中的迭代是指按照元素的顺序逐个调用的过程,迭代概念包括:迭代协议.可迭代对象和迭代器三个概念. 迭代协议是指有__next__()函数的对象会前进到下一个结果,而到达系列的末尾时,则会引发 ...
随机推荐
- yii components文件到底应该放些什么代码
项目全局用的代码,比如项目所有controller和model的共通操作或者放一些第三方的组件.插件之类的项目全局用的代码
- redis (一) --- 基本使用
概述 redis是基于key-value 我们所说的数据类型实际是 key-value 中的 value .文章主要介绍的是redis 几个重要的数据类型的使用. 简单使用 //keys patter ...
- 【译】高级T-SQL进阶系列 (三)【中篇】:理解公共表表达式(CTEs)
[译注:此文为翻译,由于本人水平所限,疏漏在所难免,欢迎探讨指正] 原文链接:传送门. 一个简单的CTE例子 如前所述,CTE‘s提供给你了一个方法来更容易的书写复杂的代码以提高其可读性.假设你有列表 ...
- 自己实现java中Iterator(迭代器功能)
今天躺在床上忽然想到一个问题,迭代器的代码是如何实现的?于是乎不由自主的爬起来敲两行代码. List<String> list=new ArrayList<>(2); list ...
- HDU 2063 过山车(二分图 && 匈牙利 && 最小点覆盖)
嗯... 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2063 这是一道很经典的匈牙利问题: 把男同学看成左边点,女同学看成右边点,如果两个同学愿意同 ...
- CSS-禁止文本被选中
pc端: .not-select{ -moz-user-select:none; /*火狐*/ -webkit-user-select:none; /*webkit浏览器*/ -ms-user-sel ...
- CSS-自适应网页使用@media和rem
@media 查询 @media 媒体查询选择性加载css,意思是自动探测屏幕宽度,然后加载相应的CSS文件.可以针对不同的屏幕尺寸设置不同的样式,特别是需要设置设计响应式的页面,@media 是个不 ...
- ASP.NET Core搭建多层网站架构【9.1-使用Autofac代替原生的依赖注入】
2020/01/30, ASP.NET Core 3.1, VS2019, Autofac.Extensions.DependencyInjection 5.0.1 摘要:基于ASP.NET Core ...
- python应用-pycharm新建模板默认添加shebang编码作者时间等信息
1.pycharm4.5激活码 用户名: yueting3527 注册码: ===== LICENSE BEGIN ===== 93347-12042010 00001FMHemWIs"6w ...
- JDBC 通过读取文件进行初始化