Spark文档阅读之一:Spark Overview
1. spark的几种执行方式
1)交互式shell:bin/spark-shell
2)python: bin/pyspark & bin/spark-submit xx.py
3)R:bin/sparkR & bin/spark-submit xx.R
2. 任务的提交
bin/spark-submit \
--class <main-class> \ # 任务入口
--master <master-url> \ # 支持多种cluster manager
--deploy-mode <deploy-mode> \ # cluster / client,默认为client
--conf <key>=<value> \
... # other options,如--supervise(非0退出立即重启), --verbose(打印debug信息), --jars xx.jar(上传更多的依赖,逗号分隔,不支持目录展开)
<application-jar> \ # main-class来自这个jar包,必须是所有节点都可见的路径,hdfs://或file://
[application-arguments] # 入口函数的参数 bin/spark-submit \
--master <master-url> \
<application-python> \
[application-arguments]
3. cluster模式
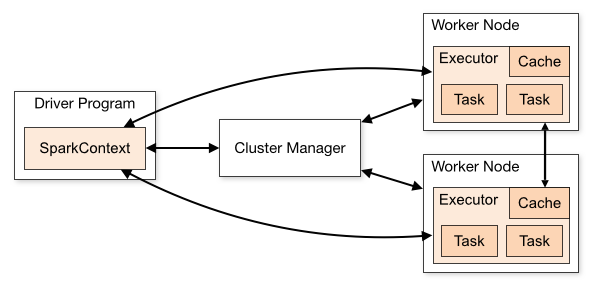
术语表
|
术语
|
含义
|
|
Application
|
任务,用户的spark程序,包含位于集群的一个driver和多个executors
|
|
Application jar
|
一个包含用户spark任务和依赖的jar包,不应包含hadoop或spark库
|
|
Driver program
|
任务main()函数和SparkContext所在的进程
|
|
Cluster manager
|
获取集群资源的外部服务
|
|
Deploy mode
|
用来区分driver进程在cluster还是client(即非cluster机器)上执行
|
|
Worker node
|
任何可以跑任务代码的节点
|
|
Executor
|
在worker node上载入并运行了用户任务的一个进程,它执行了tasks并且在内存或存储中保存数据,每个application独占它自己的executors
|
|
Task
|
一组被发送到一个executor的工作
|
|
Job
|
一个多tasks的并行计算单元,对应一个spark操作(例如save, collect)
|
|
Stage
|
每个job可以划分成的更小的tasks集合,类似MapReduce中的map/reduce,stages相互依赖
|


Spark文档阅读之一:Spark Overview的更多相关文章
- Spark文档阅读之二:Programming Guides - Quick Start
Quick Start: https://spark.apache.org/docs/latest/quick-start.html 在Spark 2.0之前,Spark的编程接口为RDD (Resi ...
- 转:苹果Xcode帮助文档阅读指南
一直想写这么一个东西,长期以来我发现很多初学者的问题在于不掌握学习的方法,所以,Xcode那么好的SDK文档摆在那里,对他们也起不到什么太大的作用.从论坛.微博等等地方看到的初学者提出的问题,也暴露出 ...
- Django文档阅读-Day1
Django文档阅读-Day1 Django at a glance Design your model from djano.db import models #数据库操作API位置 class R ...
- Django文档阅读-Day3
Django文档阅读-Day3 Writing your first Django app, part 3 Overview A view is a "type" of Web p ...
- Node.js的下载、安装、配置、Hello World、文档阅读
Node.js的下载.安装.配置.Hello World.文档阅读
- 我的Cocos Creator成长之路1环境搭建以及基本的文档阅读
本人原来一直是做cocos-js和cocos-lua的,应公司发展需要,现转型为creator.会在自己的博客上记录自己的成长之路. 1.文档阅读:(cocos的官方文档) http://docs.c ...
- Keras 文档阅读笔记(不定期更新)
目录 Keras 文档阅读笔记(不定期更新) 模型 Sequential 模型方法 Model 类(函数式 API) 方法 层 关于 Keras 网络层 核心层 卷积层 池化层 循环层 融合层 高级激 ...
- Django文档阅读-Day2
Django文档阅读 - Day2 Writing your first Django app, part 1 You can tell Django is installed and which v ...
- Spark Streaming + Flume整合官网文档阅读及运行示例
1,基于Flume的Push模式(Flume-style Push-based Approach) Flume被用于在Flume agents之间推送数据.在这种方式下,Spark Stre ...
随机推荐
- SQLSTATE[42S01]: Base table or view already exists: 1050 Table 'xxx' already exists
字面意思 xxx表已存在. 在使用laravel 写同步结构的时候 最好习惯性写个if语句判定是否存在 // 判断数据表是否存在 Schema::hasTable('table'); // 判断数据 ...
- 【C++】常量
注意:以下内容摘自文献[1],修改了部分内容. 1.常量:常量的值是不能改变的,一般从其字面形式即可判别是否为常量. 2.常量包括数值型常量(即常数)和字符型常量. 3.常量无unsigned型.但一 ...
- [wordpress使用]002_主题
使用WordPress作为博客内容管理系统有一个很大的好处是,WordPress拥有大量的优秀的免费模板.你所需要的是下载安装,和稍作修改.下面接着开始WordPress教程:WordPress主题 ...
- 同步锁Lock & 生产者和消费者案例
显示锁 Lock ①在 Java 5.0 之前,协调共享对象的访问时可以使用的机 制只有 synchronized 和 volatile . Java 5.0 后增加了一些 新的机制,但并不是一种替代 ...
- Chisel3 - Tutorial - Adder
https://mp.weixin.qq.com/s/SEcVjGRL1YloGlEPSoHr3A 位数为参数的加法器.通过FullAdder级联实现. 参考链接: https://githu ...
- Chisel3 - 字面量(literal)
https://mp.weixin.qq.com/s/uiW4k4DeguvYsG8LhHk2Ug 介绍Chisel3中基本数据类型的字面量的写法,及其背后的实现机制,也就是Scala隐式规则. ...
- Magicodes.IE 在100万数据量下导入导出性能测试
原文作者:HueiFeng 前言 目前Magicodes.IE更新到了2.2.3,感谢大家的支持,同时建议大家在使用过程中如果遇到一些问题或者说需要一些额外的功能可以直接提issues,当然更建议大家 ...
- 题解 CF1348D 【Phoenix and Science】
题目大意,每天细菌会在早上选择分裂,晚上生长. 观察题目,我们可以发现.不管我们怎么分裂细菌,这一天晚上的总质量都是前一天晚上的总质量加上今天的细菌数. 那么我们肯定希望细菌分裂的越多越好,这样我们减 ...
- Java实现 蓝桥杯 算法训练 关联矩阵
算法训练 关联矩阵 时间限制:1.0s 内存限制:512.0MB 提交此题 问题描述 有一个n个结点m条边的有向图,请输出他的关联矩阵. 输入格式 第一行两个整数n.m,表示图中结点和边的数目.n&l ...
- java实现Floyd算法
1 问题描述 何为Floyd算法? Floyd算法功能:给定一个加权连通图,求取从每一个顶点到其它所有顶点之间的最短距离.(PS:其实现功能也称完全最短路径问题) Floyd算法思想:将顶点i到j的直 ...