MySQL 性能优化细节
服务器层面优化(了解)
将数据保存在内存中,保证从内存读取数据
- 设置足够大的innodb_buffer_pool_size,将数据读取到内存中。
- 建议innodb_buffer_pool_size设置为总内存大小的3/4或者4/5。
- 怎样确定innodb_buffer_pool_size足够大,数据是从内存读取而不是硬盘?
show global status like 'innodb_buffer_pool_pages_%';
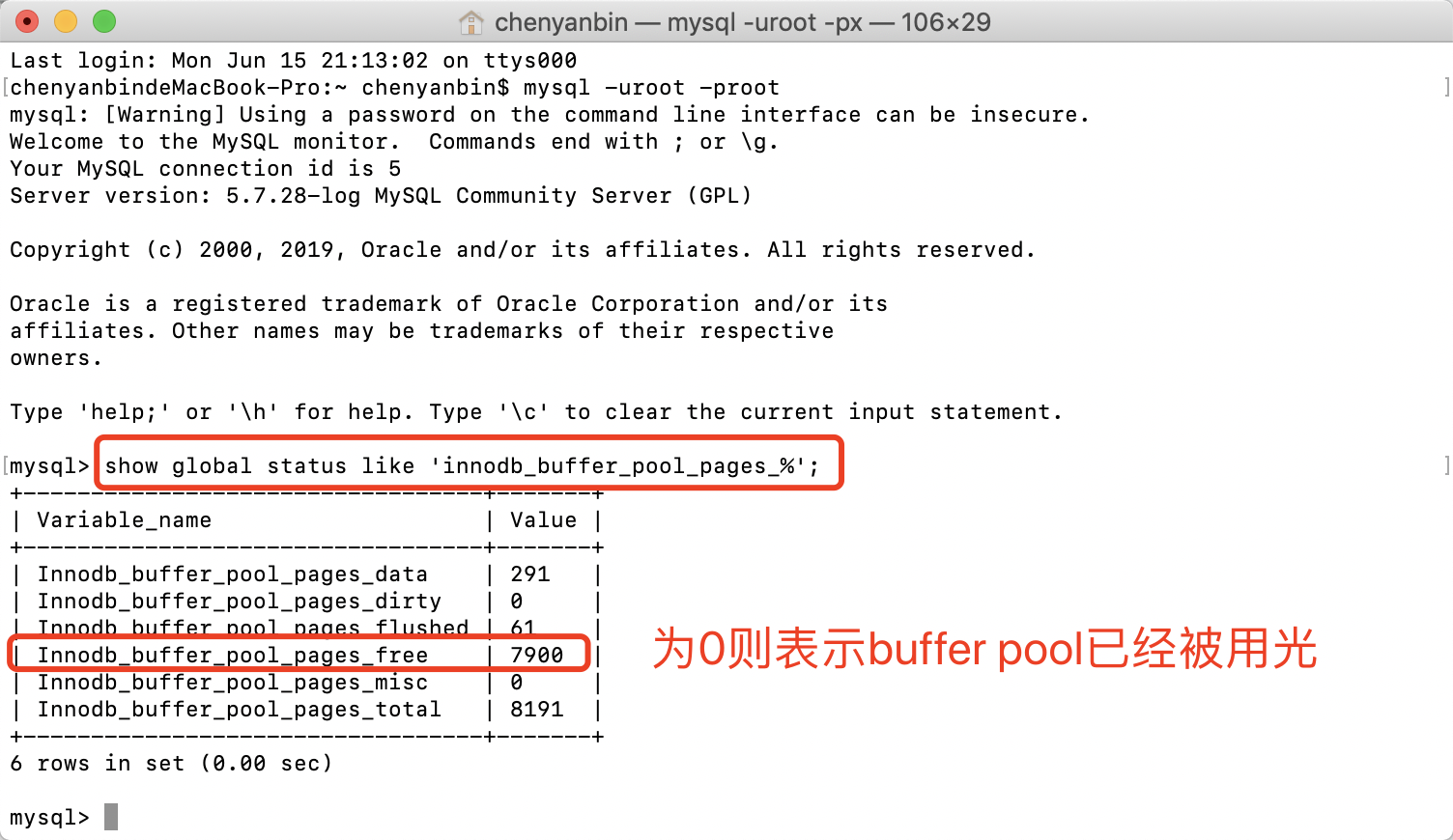
降低磁盘写入次数
- 使用足够大的写入缓存innodb_log_file_size
- 推荐innodb_log_file_size设置为0.25*innodb_buffer_pool_size
- 设置合适的innodb_flush_log_at_trx_commit
提高磁盘读写
可以考虑使用SSD硬盘,不过得考虑成本是否合适。
SQL设计优化(了解需求的人并懂技术的人)
- 设计中间表,一般针对统计分析功能,或者实时性不高的需求
- 为减少关联查询,创建合理的冗余字段
- 对于字段太多的大表,考虑拆表
- 对于表中经常不被使用的字段,考虑拆表
- 每张表都有一个主键,而且主键类型最好是int类型,建议自增主键
SQL语句优化(开发人员)
索引优化
- 为搜索字段创建索引(考虑:查询多还是增删多?)
- 尽量建立组合索引并注意组合索引的创建顺序,按照顺序组织查询条件,尽量将筛选粒度大的查询条件放到最左边
- SELECT 语句尽量不要使用*
- order by、group by语句尽量使用索引
LIMIT优化
- 如果预计SELECT 语句的查询结果是一条,最好使用LIMIT 1,可以停止全表扫描
- SELECT * FROM S_USER WHERE USERNAME='chenyanbin' LIMIT 1;
- 处理分页会使用到LIMIT,当翻页到非常靠后的页面的时候,偏移量会非常大,这时LIMIT的效率会非常差
LIMIT的优化问题,其实是OFFSET的问题,他会导致MySQL扫描大量不需要的行然后再抛弃掉。 解决方案:使用order by和索引覆盖 原sql:
SELECT user_name,age FROM s_user LIMIT 10000,20; 优化后SQL:
SELECT user_name,age FROM s_user ORDER BY city LIMIT 20;
其他优化
- 尽量不使用count(*)、尽量使用count(主键)
- JOIN两张表的关联字段最好都建立索引,而且最好字段类型是一样的
- WHERE条件中尽量不要使用1=1、not in 语句(建议使用not exists)
- 不用MySQL内置的函数,因为内置函数不会建立查询缓存
- 合理利用慢查询日志、explain执行计划查询、show profile查询SQL执行的资源使用情况
MySQL 性能优化细节的更多相关文章
- MySQL性能优化的5个维度
面试官如果问你:你会从哪些维度进行MySQL性能优化?你会怎么回答? 所谓的性能优化,一般针对的是MySQL查询的优化.既然是优化查询,我们自然要先知道查询操作要经过哪些环节,然后思考可以在哪些环节进 ...
- Mysql - 性能优化之子查询
记得在做项目的时候, 听到过一句话, 尽量不要使用子查询, 那么这一篇就来看一下, 这句话是否是正确的. 那在这之前, 需要介绍一些概念性东西和mysql对语句的大致处理. 当Mysql Server ...
- Mysql性能优化三(分表、增量备份、还原)
接上篇Mysql性能优化二 对表进行水平划分 如果一个表的记录数太多了,比如上千万条,而且需要经常检索,那么我们就有必要化整为零了.如果我拆成100个表,那么每个表只有10万条记录.当然这需要数据在逻 ...
- [MySQL性能优化系列]提高缓存命中率
1. 背景 通常情况下,能用一条sql语句完成的查询,我们尽量不用多次查询完成.因为,查询次数越多,通信开销越大.但是,分多次查询,有可能提高缓存命中率.到底使用一个复合查询还是多个独立查询,需要根据 ...
- [MySQL性能优化系列]巧用索引
1. 普通青年的索引使用方式 假设我们有一个用户表 tb_user,内容如下: name age sex jack 22 男 rose 21 女 tom 20 男 ... ... ... 执行SQL语 ...
- MySQL性能优化:索引
MySQL性能优化:索引 索引提供指向存储在表的指定列中的数据值的指针,然后根据您指定的排序顺序对这些指针排序.数据库使用索引以找到特定值,然后顺指针找到包含该值的行.这样可以使对应于表的SQL语句执 ...
- mysql 性能优化方向
国内私募机构九鼎控股打造APP,来就送 20元现金领取地址:http://jdb.jiudingcapital.com/phone.html内部邀请码:C8E245J (不写邀请码,没有现金送)国内私 ...
- MySQL性能优化总结
一.MySQL的主要适用场景 1.Web网站系统 2.日志记录系统 3.数据仓库系统 4.嵌入式系统 二.MySQL架构图: 三.MySQL存储引擎概述 1)MyISAM存储引擎 MyISAM存储引擎 ...
- MYSQL性能优化的最佳20+条经验
MYSQL性能优化的最佳20+条经验 2009年11月27日 陈皓 评论 148 条评论 131,702 人阅读 今天,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显.关于数 ...
随机推荐
- POJ1015
题目链接:http://poj.org/problem?id=1015 大概题意: 法庭要挑选m人陪审团.先随机挑选n个公民,对于每个公民,控辩双方都有各自的“喜好度”p[ ] 和 d[ ],法庭要尽 ...
- 设计模式:Filter+Servlet+反射
传统设计 分类管理需要:增加,删除,编辑,修改,查询5个服务端功能. 一个路径对应一个Servlet的思路,就需要设计5个Servlet类,并且在web.xml中配置5个路径. CategoryAdd ...
- sklearn学习:为什么roc_auc_score()和auc()有不同的结果?
为什么roc_auc_score()和auc()有不同的结果? auc():计算ROC曲线下的面积.即图中的area roc_auc_score():计算AUC的值,即输出的AUC 最佳答案 AUC并 ...
- docker-compose 命令详解
1.docker-compose的使用非常类似于docker命令的使用,但是需要注意的是大部分的compose命令都需要到docker-compose.yml文件所在的目录下才能执行. 2.[Linu ...
- jdk8 Collections#sort究竟做了什么
前言 Collections#sort 追踪代码进去看,会调用到Arrays.sort,看到这里时,你肯定会想,这不是很简单,Arrays.sort在元素较少时使用插入排序,较多时使用快速排序,再多时 ...
- c# 优化代码的一些规则——优先隐式类型[一]
前言 说到底就是优先使用var,这个关键字,在c# 3.0中出现了. 首先要确认几点,一个就是var 是静态变量,而不是动态变量,也就是说使用var 你是不必去担心性能问题得, 百度百科: 1)静态存 ...
- mybatis的多表联查
多对一连表查询简单记录
- mysql去重复关键字distinct的用法
distinct的去重复的提前是表中所有列的数据完成相同时,才能把相同的数据只保留一条,并不是 distinct 列名,除去某一列相同的数据,并且 distinct要放在第一个列前面.案例如下:一个学 ...
- java的Interger自动包装带来的问题
1 首先看一下以下代码: Integer b=7; Integer c=7; Integer r=234; Integer d=234; System.out.println(b==c); Syste ...
- try catch finally return 轶事
最近阿里发布了java开发手册终极版,看到其中一条规约:[强制]不能在 finally 块中使用 return, finally 块中的 return 返回后方法结束执行,不会再执行 try 块中的 ...