sklearn调用逻辑回归算法
1、逻辑回归算法即可以看做是回归算法,也可以看作是分类算法,通常用来解决分类问题,主要是二分类问题,对于多分类问题并不适合,也可以通过一定的技巧变形来间接解决。
2、决策边界是指不同分类结果之间的边界线(或者边界实体),它具体的表现形式一定程度上说明了算法训练模型的过拟合程度,我们可以通过决策边界来调整算法的超参数。

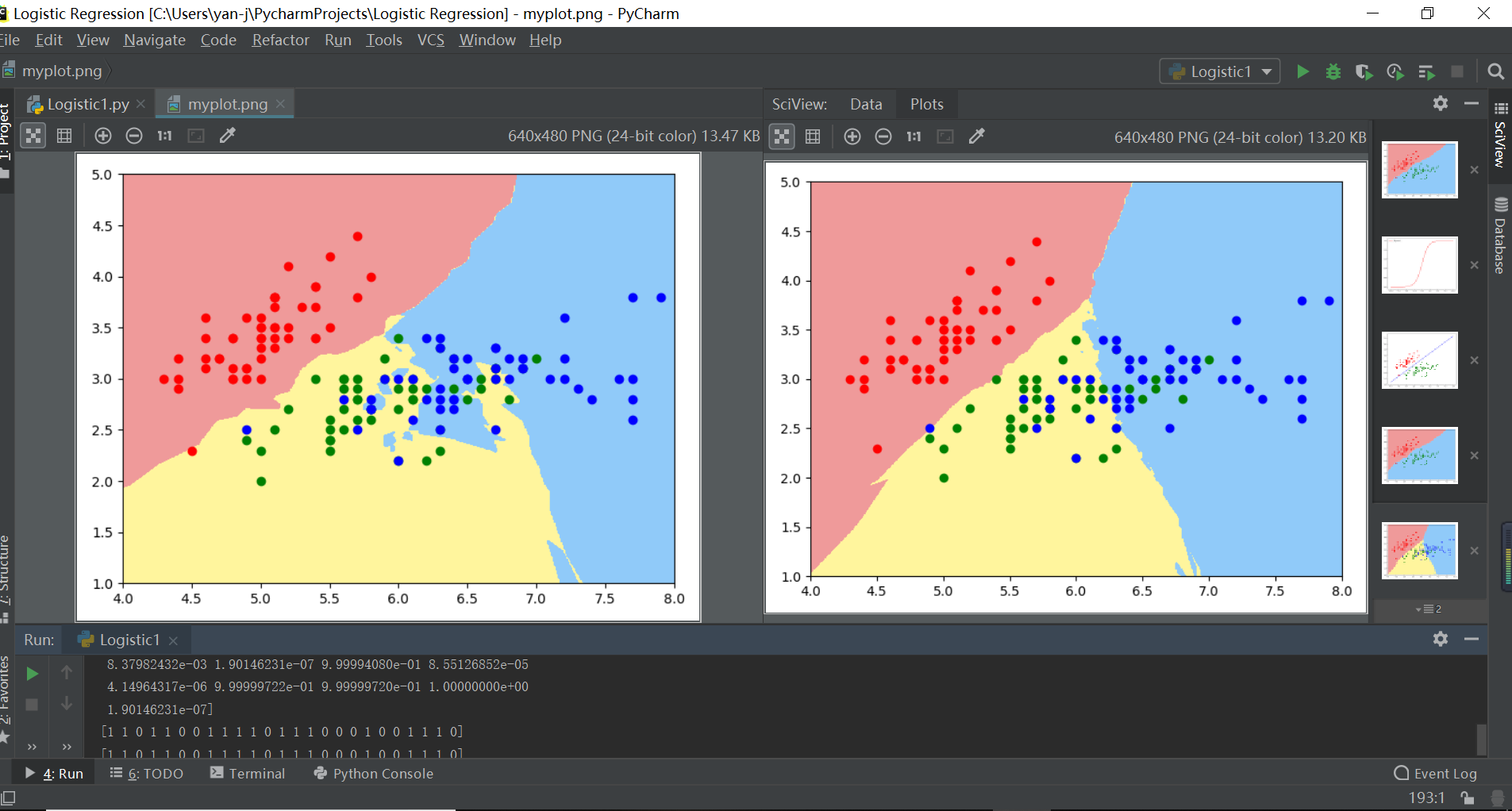
注解:左边逻辑回归拟合决策边界嘈杂冗余说明过拟合,右边决策边界分层清晰说明拟合度好
3、在逻辑回归中随着算法的复杂度不断地提高,其算法的过拟合也会越来越严重,为了避免这个现象,我们在逻辑回归中也需要进行正则化,以减小整体拟合的均方差,减少训练的过拟合现象。因此sklearn中调用逻辑回归时含有三个重要的超参数degree(多项式的最高次数),C(正则化系数)以及penalty(正则化的方式l1/l2)

4、sklearn中逻辑回归使用的正则化方式如下:
import numpy as np
import matplotlib.pyplot as plt
#定义概率转换函数sigmoid函数
def sigmoid(t):
return 1/(1+np.exp(-t))
x=np.linspace(-10,10,100)
y=sigmoid(x)
plt.figure()
plt.plot(x,y,"r",label="Sigmoid")
plt.legend(loc=2)
plt.show()
from sklearn import datasets
d=datasets.load_iris()
x=d.data
y=d.target
x=x[y<2,:2]
y=y[y<2]
#定义机器学习算法的决策边界输出函数
def plot_decision_boundary(model,axis):
x0,x1=np.meshgrid(
np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2],axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1,1)
)
x_new=np.c_[x0.ravel(),x1.ravel()]
y_pre=model.predict(x_new)
zz=y_pre.reshape(x0.shape)
from matplotlib.colors import ListedColormap
cus=ListedColormap(["#EF9A9A","#FFF59D","#90CAF9"])
plt.contourf(x0,x1,zz,cmap=cus)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=666)
from sklearn.neighbors import KNeighborsClassifier
knn1=KNeighborsClassifier()
knn1.fit(x_train,y_train)
plot_decision_boundary(knn1,axis=[4,8,1,5])
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.show()
knn2=KNeighborsClassifier(n_neighbors=50) #k越大,模型越简单,也意味着过拟合的程度越轻,决策边界越清晰
knn2.fit(d.data[:,:2],d.target)
x=d.data
y=d.target
plot_decision_boundary(knn2,axis=[4,8,1,5])
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.scatter(x[y==2,0],x[y==2,1],color="b")
plt.show() #逻辑回归添加多项式回归
import numpy as np
import matplotlib.pyplot as plt
np.random.seed=666
x=np.random.normal(0,1,size=(100,2))
y=np.array(x[:,0]**2+x[:,1]**2<1.5,dtype="int")
knn2=KNeighborsClassifier()
knn2.fit(x,y)
plot_decision_boundary(knn2,axis=[-4,4,-3,3])
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.show() ### sklearn中调用逻辑回归算法函数
import numpy as np
import matplotlib.pyplot as plt
np.random.seed=666
x=np.random.normal(0,1,size=(200,2))
y=np.array(x[:,0]**2+x[:,1]<1.5,dtype="int")
for _ in range(20):
y[np.random.randint(200)]=1
plt.figure()
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.show()
#1-1单纯的逻辑回归算法
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=666)
from sklearn.linear_model import LogisticRegression
log=LogisticRegression()
log.fit(x_train,y_train)
print(log.score(x_test,y_test))
knn3=KNeighborsClassifier()
knn3.fit(x_train,y_train)
print(knn3.score(x_test,y_test))
#1-2sklearn中的逻辑回归(多项式参与,并不带正则化)
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
def polynomiallogisticregression(degree):
return Pipeline([
("poly",PolynomialFeatures(degree=degree)),
("std_reg",StandardScaler()),
("log_reg",LogisticRegression())
])
x=np.random.normal(0,1,size=(200,2))
y=np.array(x[:,0]**2+x[:,1]<1.5,dtype="int")
for _ in range(20):
y[np.random.randint(200)]=1
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=666)
p1=polynomiallogisticregression(degree=2)
p1.fit(x_train,y_train)
print(p1.score(x_train,y_train))
print(p1.score(x_test,y_test))
plot_decision_boundary(p1,axis=[-4,4,-4,4])
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.show()
p1=polynomiallogisticregression(degree=20) #当其次数变为高次时,其训练模型已经过拟合
p1.fit(x_train,y_train)
print(p1.score(x_train,y_train))
print(p1.score(x_test,y_test))
plot_decision_boundary(p1,axis=[-4,4,-4,4])
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.show()
#1-3逻辑回归的正则化形式函数
def Polynomiallogisticregression(degree,C,penalty): #逻辑回归的三大超参数
return Pipeline([
("poly",PolynomialFeatures(degree=degree)),
("std_reg",StandardScaler()),
("log_reg",LogisticRegression(C=C,penalty=penalty))
])
p1=Polynomiallogisticregression(degree=20,C=1,penalty="l2") #当其次数变为高次时,其训练模型已经过拟合
p1.fit(x_train,y_train)
print(p1.score(x_train,y_train))
print(p1.score(x_test,y_test))
plot_decision_boundary(p1,axis=[-4,4,-4,4])
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.show() 其输出结果对比如下所示:
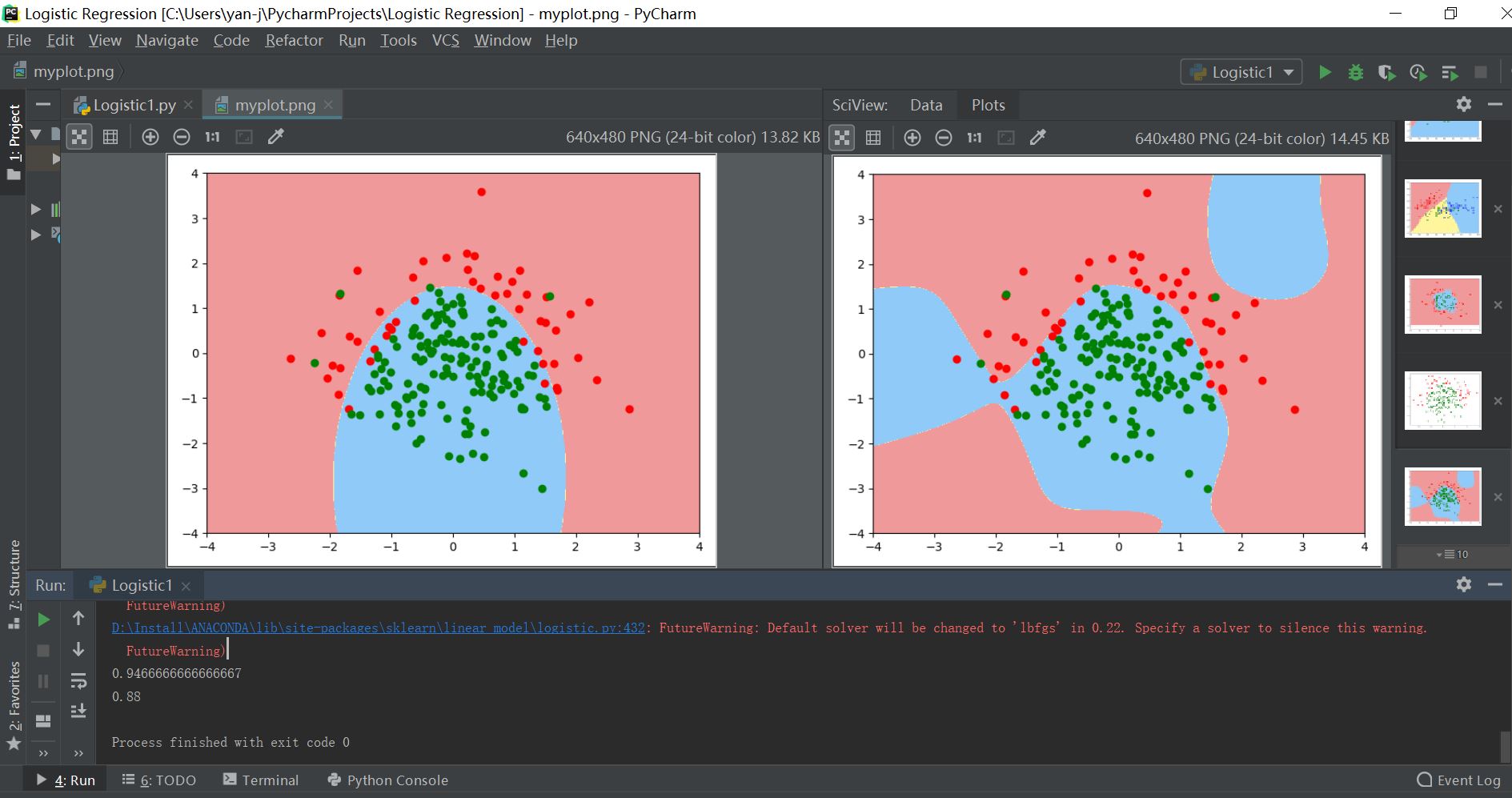
注:左为拟合度比较好的决策边界,右边为高次的过拟合训练模型
sklearn调用逻辑回归算法的更多相关文章
- Sklearn实现逻辑回归
方法与参数 LogisticRegression类的各项参数的含义 class sklearn.linear_model.LogisticRegression(penalty='l2', dual=F ...
- SparkMLlib学习分类算法之逻辑回归算法
SparkMLlib学习分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/51693 ...
- SparkMLlib分类算法之逻辑回归算法
SparkMLlib分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/5169383 ...
- 逻辑回归算法的原理及实现(LR)
Logistic回归虽然名字叫"回归" ,但却是一种分类学习方法.使用场景大概有两个:第一用来预测,第二寻找因变量的影响因素.逻辑回归(Logistic Regression, L ...
- Spark机器学习(2):逻辑回归算法
逻辑回归本质上也是一种线性回归,和普通线性回归不同的是,普通线性回归特征到结果输出的是连续值,而逻辑回归增加了一个函数g(z),能够把连续值映射到0或者1. MLLib的逻辑回归类有两个:Logist ...
- 《BI那点儿事》Microsoft 逻辑回归算法——预测股票的涨跌
数据准备:一组股票历史成交数据(股票代码:601106 中国一重),起止日期:2011-01-04至今,其中变量有“开盘”.“最高”.“最低”.“收盘”.“总手”.“金额”.“涨跌”等 UPDATE ...
- sklearn 调用逻辑回归函数训练数据时出现 “unknown label type:unknown”
problemsolution:
- sklearn中调用集成学习算法
1.集成学习是指对于同一个基础数据集使用不同的机器学习算法进行训练,最后结合不同的算法给出的意见进行决策,这个方法兼顾了许多算法的"意见",比较全面,因此在机器学习领域也使用地非常 ...
- sklearn实现多分类逻辑回归
sklearn实现多分类逻辑回归 #二分类逻辑回归算法改造适用于多分类问题1.对于逻辑回归算法主要是用回归的算法解决分类的问题,它只能解决二分类的问题,不过经过一定的改造便可以进行多分类问题,主要的改 ...
随机推荐
- linux可执行程序调试
gdb调试不用多说 ./testapp 2>%261 适合线上问题排查,可打印程序错误接口代码 ldd testapp 查看代码动态链接程序是否正常
- HDU 1035 Robot Motion(dfs + 模拟)
嗯... 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1035 这道题比较简单,但自己一直被卡,原因就是在读入mp这张字符图的时候用了scanf被卡. ...
- 【规范建议】服务端接口返回字段类型与iOS端的解析
一.本文档的写作目的 App需要跟产品.UI.后台.服务器.测试打交道,app的产出是其他端人员产出的综合体现.与其他端人员沟通就像是开发写接口,也就是面向接口编程的思想. 本文档讲解针对的是服务端返 ...
- selenium webdriver 操作select
@Test public void test() { WebDriver driver=ExplorerBase.IESetting(); driver.get("http://unique ...
- day1-3js代码执行特性
Js代码执行特性 js中变量声明都会提升到脚本的第一行(注意不是定义,只是声明) 函数变量声明也会提升到前面(是整个函数!)(变量最前,函数其后) 注:在执行js代码前,先把所有变量声明,函数提升至前 ...
- GO判断输入
判断用户密码输入: package main import"fmt" func main(){ var a int var b int fmt.Printf("请输入密码 ...
- 从零构建以太坊(Ethereum)智能合约到项目实战——第23章 从零构建和部署去中心化投票App,decentralization Voting Dapp
P90 .1-从零构建和部署去中心化投票App-01 P91 .2-从零构建和部署去中心化投票App-02 P92 .3-从零构建和部署去中心化投票App-03 参考博文:http://liyuech ...
- A - Bi-shoe and Phi-shoe 素数打表
A - Bi-shoe and Phi-shoe Bamboo Pole-vault is a massively popular sport in Xzhiland. And Master Phi- ...
- Spring boot 启动图片
生成工具:http://patorjk.com/software/taag/#p=testall&h=0&v=0&f=Graffiti&t=Type%20Somethi ...
- Java基础 -3.4
反码(~) 在计算机中,负数以其正值的补码形式表达. 什么叫补码呢?这得从原码,反码说起. 原码:一个整数,按照绝对值大小转换成的二进制数,称为原码. 比如 00000000 00000000 000 ...