sklearn调用逻辑回归算法
1、逻辑回归算法即可以看做是回归算法,也可以看作是分类算法,通常用来解决分类问题,主要是二分类问题,对于多分类问题并不适合,也可以通过一定的技巧变形来间接解决。
2、决策边界是指不同分类结果之间的边界线(或者边界实体),它具体的表现形式一定程度上说明了算法训练模型的过拟合程度,我们可以通过决策边界来调整算法的超参数。

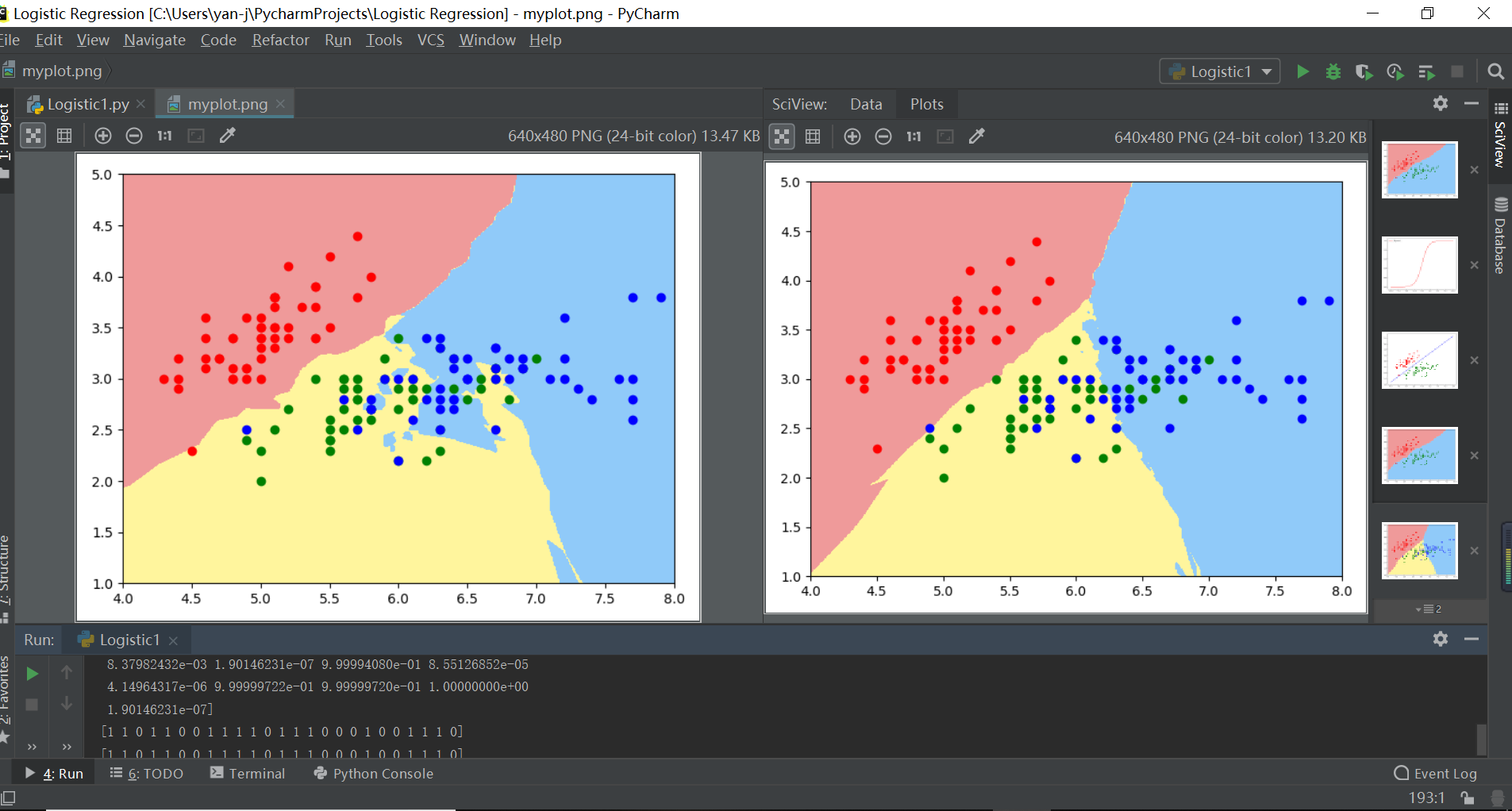
注解:左边逻辑回归拟合决策边界嘈杂冗余说明过拟合,右边决策边界分层清晰说明拟合度好
3、在逻辑回归中随着算法的复杂度不断地提高,其算法的过拟合也会越来越严重,为了避免这个现象,我们在逻辑回归中也需要进行正则化,以减小整体拟合的均方差,减少训练的过拟合现象。因此sklearn中调用逻辑回归时含有三个重要的超参数degree(多项式的最高次数),C(正则化系数)以及penalty(正则化的方式l1/l2)

4、sklearn中逻辑回归使用的正则化方式如下:
import numpy as np
import matplotlib.pyplot as plt
#定义概率转换函数sigmoid函数
def sigmoid(t):
return 1/(1+np.exp(-t))
x=np.linspace(-10,10,100)
y=sigmoid(x)
plt.figure()
plt.plot(x,y,"r",label="Sigmoid")
plt.legend(loc=2)
plt.show()
from sklearn import datasets
d=datasets.load_iris()
x=d.data
y=d.target
x=x[y<2,:2]
y=y[y<2]
#定义机器学习算法的决策边界输出函数
def plot_decision_boundary(model,axis):
x0,x1=np.meshgrid(
np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2],axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1,1)
)
x_new=np.c_[x0.ravel(),x1.ravel()]
y_pre=model.predict(x_new)
zz=y_pre.reshape(x0.shape)
from matplotlib.colors import ListedColormap
cus=ListedColormap(["#EF9A9A","#FFF59D","#90CAF9"])
plt.contourf(x0,x1,zz,cmap=cus)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=666)
from sklearn.neighbors import KNeighborsClassifier
knn1=KNeighborsClassifier()
knn1.fit(x_train,y_train)
plot_decision_boundary(knn1,axis=[4,8,1,5])
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.show()
knn2=KNeighborsClassifier(n_neighbors=50) #k越大,模型越简单,也意味着过拟合的程度越轻,决策边界越清晰
knn2.fit(d.data[:,:2],d.target)
x=d.data
y=d.target
plot_decision_boundary(knn2,axis=[4,8,1,5])
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.scatter(x[y==2,0],x[y==2,1],color="b")
plt.show() #逻辑回归添加多项式回归
import numpy as np
import matplotlib.pyplot as plt
np.random.seed=666
x=np.random.normal(0,1,size=(100,2))
y=np.array(x[:,0]**2+x[:,1]**2<1.5,dtype="int")
knn2=KNeighborsClassifier()
knn2.fit(x,y)
plot_decision_boundary(knn2,axis=[-4,4,-3,3])
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.show() ### sklearn中调用逻辑回归算法函数
import numpy as np
import matplotlib.pyplot as plt
np.random.seed=666
x=np.random.normal(0,1,size=(200,2))
y=np.array(x[:,0]**2+x[:,1]<1.5,dtype="int")
for _ in range(20):
y[np.random.randint(200)]=1
plt.figure()
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.show()
#1-1单纯的逻辑回归算法
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=666)
from sklearn.linear_model import LogisticRegression
log=LogisticRegression()
log.fit(x_train,y_train)
print(log.score(x_test,y_test))
knn3=KNeighborsClassifier()
knn3.fit(x_train,y_train)
print(knn3.score(x_test,y_test))
#1-2sklearn中的逻辑回归(多项式参与,并不带正则化)
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
def polynomiallogisticregression(degree):
return Pipeline([
("poly",PolynomialFeatures(degree=degree)),
("std_reg",StandardScaler()),
("log_reg",LogisticRegression())
])
x=np.random.normal(0,1,size=(200,2))
y=np.array(x[:,0]**2+x[:,1]<1.5,dtype="int")
for _ in range(20):
y[np.random.randint(200)]=1
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=666)
p1=polynomiallogisticregression(degree=2)
p1.fit(x_train,y_train)
print(p1.score(x_train,y_train))
print(p1.score(x_test,y_test))
plot_decision_boundary(p1,axis=[-4,4,-4,4])
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.show()
p1=polynomiallogisticregression(degree=20) #当其次数变为高次时,其训练模型已经过拟合
p1.fit(x_train,y_train)
print(p1.score(x_train,y_train))
print(p1.score(x_test,y_test))
plot_decision_boundary(p1,axis=[-4,4,-4,4])
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.show()
#1-3逻辑回归的正则化形式函数
def Polynomiallogisticregression(degree,C,penalty): #逻辑回归的三大超参数
return Pipeline([
("poly",PolynomialFeatures(degree=degree)),
("std_reg",StandardScaler()),
("log_reg",LogisticRegression(C=C,penalty=penalty))
])
p1=Polynomiallogisticregression(degree=20,C=1,penalty="l2") #当其次数变为高次时,其训练模型已经过拟合
p1.fit(x_train,y_train)
print(p1.score(x_train,y_train))
print(p1.score(x_test,y_test))
plot_decision_boundary(p1,axis=[-4,4,-4,4])
plt.scatter(x[y==0,0],x[y==0,1],color="r")
plt.scatter(x[y==1,0],x[y==1,1],color="g")
plt.show() 其输出结果对比如下所示:
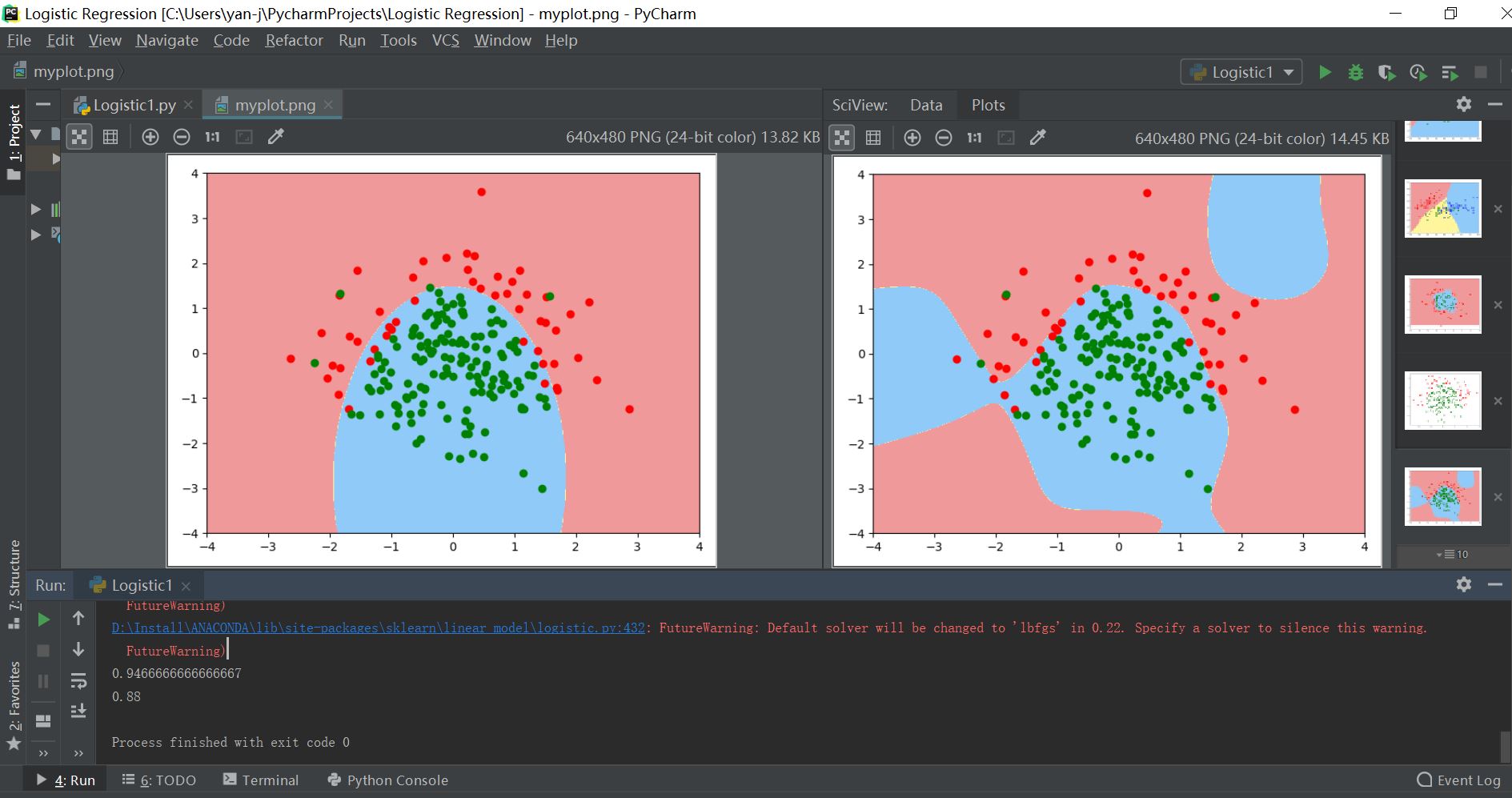
注:左为拟合度比较好的决策边界,右边为高次的过拟合训练模型
sklearn调用逻辑回归算法的更多相关文章
- Sklearn实现逻辑回归
方法与参数 LogisticRegression类的各项参数的含义 class sklearn.linear_model.LogisticRegression(penalty='l2', dual=F ...
- SparkMLlib学习分类算法之逻辑回归算法
SparkMLlib学习分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/51693 ...
- SparkMLlib分类算法之逻辑回归算法
SparkMLlib分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/5169383 ...
- 逻辑回归算法的原理及实现(LR)
Logistic回归虽然名字叫"回归" ,但却是一种分类学习方法.使用场景大概有两个:第一用来预测,第二寻找因变量的影响因素.逻辑回归(Logistic Regression, L ...
- Spark机器学习(2):逻辑回归算法
逻辑回归本质上也是一种线性回归,和普通线性回归不同的是,普通线性回归特征到结果输出的是连续值,而逻辑回归增加了一个函数g(z),能够把连续值映射到0或者1. MLLib的逻辑回归类有两个:Logist ...
- 《BI那点儿事》Microsoft 逻辑回归算法——预测股票的涨跌
数据准备:一组股票历史成交数据(股票代码:601106 中国一重),起止日期:2011-01-04至今,其中变量有“开盘”.“最高”.“最低”.“收盘”.“总手”.“金额”.“涨跌”等 UPDATE ...
- sklearn 调用逻辑回归函数训练数据时出现 “unknown label type:unknown”
problemsolution:
- sklearn中调用集成学习算法
1.集成学习是指对于同一个基础数据集使用不同的机器学习算法进行训练,最后结合不同的算法给出的意见进行决策,这个方法兼顾了许多算法的"意见",比较全面,因此在机器学习领域也使用地非常 ...
- sklearn实现多分类逻辑回归
sklearn实现多分类逻辑回归 #二分类逻辑回归算法改造适用于多分类问题1.对于逻辑回归算法主要是用回归的算法解决分类的问题,它只能解决二分类的问题,不过经过一定的改造便可以进行多分类问题,主要的改 ...
随机推荐
- svn检出两种方式的区别
第一种是“做为新项目检出,并使用新建项目向导进行配置(仅当资源库中不存在.project工程文件时才可用,意思是如果代码库中有了这个工程文件,那么它就认为这是一个信息完整的工程,在导入的过程中就不需要 ...
- 在Windows上使用Docker运行.NET COE应用
在Windows上使用Docker运行.NET COE应用 执行步骤: 1:安装Docker For Windows(注意:docker for windows-64位Windows 10.必须开启 ...
- [IDEA] Idea复制文件到项目一直updating indices的问题
通常我们在开发JavaWeb项目的时候,都需要先将网页写好,在进行复制到web目录下,如果里面包含了很多的资源文件,就会造成一直updating indices. 方法一: 这是因为项目需要对web目 ...
- SpringMVC 配置文件详解
HandlerMapping 处理器映射 HTTP请求被DispatcherServlet拦截后,会调用HandlerMapping来处理,HandlerMapping根据 url<=&g ...
- Aery的UE4 C++游戏开发之旅(4)加载资源&创建对象
目录 资源的硬引用 硬指针 FObjectFinder<T> / FClassFinder<T> 资源的软引用 FSoftObjectPaths.FStringAssetRef ...
- mongodb插入性能
转自 https://blog.csdn.net/asdfsadfasdfsa/article/details/60872180 MongoDB与MySQL的插入.查询性能测试 7.1 平均 ...
- requests库 cookie和session
cookie 如果一个相应中包含了cookie,那么可以利用cookie属性拿到这个返回的cookie值: res = requests.get('http://www.baidu.com') pri ...
- Spring Boot + MyBatis + PostgreSql
Maven构建项目 1.访问http://start.spring.io/ 2.选择构建工具Maven Project.Spring Boot版本1.3.6以及一些工程基本信息,点击“Switch t ...
- TensorFlow样例一
假设原函数为 f(x) = 5x^2 + 3,为了估计出这个函数,定义参数未知的函数g(x, w) = w0 x^2 + w1 x + w2,现要找出适合的w使g(x, w) ≍ f(x).将这个问题 ...
- 设计模式课程 设计模式精讲 21-2 观察者模式coding
1 代码演练 1.1 代码演练1(一对一观察) 1.2 代码演练2(一对多观察) 1.3 代码演练3(多对多观察) 1 代码演练 1.1 代码演练1(一对一观察) 需求: 木木网课程系统,教师后台提醒 ...