曹工说JDK源码(4)--抄了一小段ConcurrentHashMap的代码,我解决了部分场景下的Redis缓存雪崩问题
曹工说JDK源码(1)--ConcurrentHashMap,扩容前大家同在一个哈希桶,为啥扩容后,你去新数组的高位,我只能去低位?
曹工说JDK源码(2)--ConcurrentHashMap的多线程扩容,说白了,就是分段取任务
曹工说JDK源码(3)--ConcurrentHashMap,Hash算法优化、位运算揭秘
什么是缓存雪崩
基本概念梳理
这个基本也是redis 面试的经典题目了,然而,网上不少博客对这个词的定义都含糊不清,各执一词。
主要有两类说法:
大量缓存key,由于设置了相同的过期时间,在某个时刻同时失效,导致此刻的查询请求,全部涌向db,本来db的tps大概是几千左右,结果涌入了几十万的请求,那db肯定直接就扛不住了
这种说法下面,解决方案一般是,把过期时间增加一个随机值,这样,也就不会大批量的key同时失效了
另外一种说法是,本来redis扛下了大部分的请求,但是,由于缓存所在的机器,发生了宕机。此时,缓存这台机器之间就连不上了,redis服务也挂了,此时,你的服务里,发现redis取不到,然后全都跑去查数据库,那,就发生和前面一样的情况了,请求全部涌向db,db无响应。
两类说法,也不用觉得,这个对,那个不对,不过是一个技术名词,当初发明这个词的人,估计也没想那么多,结果传播开来之后,就变成了现在这个样子。
我们这里主要采用下面那一种说法,因为下面这种说法,其实是已经包含了上面的情景。但是,下面这种场景,要复杂的多,因为redis此时就是一个完全不可信的东西了,你得想好,怎么不让它挂掉,那是不是应该部署sentinel、cluster集群?同时,持久化必须要开启。
这样呢,挂掉后,短暂的不可用之后,大概几十s吧,缓存集群就恢复了,就又可用了。
同时,我们还得考虑,假设,现在redis挂了,我们代码的降级策略是什么?
大家发现redis挂了,首先,估计是会抛异常了,连接超时;抛了异常后,要直接抛到前端吗?作为一个稳健的后端程序,那肯定是不行的,你redis挂了,数据库又没挂;好吧,那我们就大家一起去查数据库。
结果,大量的查询请求,就乌泱泱地跑去查库了,然后,db卒。这个肯定不行。
所以,我们必须要控制的一点是,当发现某个key失效了,不是大家都去查库,而是要进行 并发控制。
什么是并发控制?就是不能全部放过去查库,只能放少部分,免得把脆弱的db打死。
并发控制,基本就是要争夺去查库的权利了,这一步,基本就是一个选举的过程,可以通过抢锁的方式,比如Reentrentlock,synchronized,cas也可以。
抢到锁的线程,有资格去查库,其他线程要么被阻塞,要么自旋
抢到锁的线程,去查库,查到数据后,将数据存放在某个地方,通知其他线程去取(如果其他线程被阻塞的话);或者,如果其他线程没被阻塞,比如sleep 50ms,再去指定的地方拿数据那种,这种就不需要通知
总之,如果其他线程要我们通知,我们就通知;不要我们通知,我们就不通知。
抢到锁的线程,在构建缓存时,其他线程应该干什么?
在while(true)里,sleep 50ms,然后再去取数据
这种类似于忙等待,但是每次sleep一会,所以还不错
将自己阻塞,等待抢到锁的线程,构建完缓存后,来唤醒
在while(true)里,一直忙循环,期间一直检查数据是否已经ok了,这种方案呢,要看里面:检查数据的操作,是否耗时;如果只是检查jvm内存里的数据,那还好;否则的话,假设要去检查redis的话,这种io比较耗时的操作的话,就不合适了,cpu会一直空转。
本文采用的方案
主线程构建缓存时,其他线程,在while(true)里,sleep 一定时间,然后再检查数据是否ready。
说了这么多,好像和题目里的concurrenthashmap没啥关系,不,是有关系的,因为,这个思路,其实就是来自于concurrentHashMap。
ConcurrentHashMap中,是怎么去初始化底层数组的
在我们用无参构造函数,去new一个ConcurrentHashMap时,此时还不会去创建底层数组,这个是一个小优化。什么时候创建数组呢,是在我们第一次去put的时候。
put的时候,会调用putVal。
其中,putVal代码如下:
transient volatile Node<K,V>[] table;
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
// 1
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 2
if (tab == null || (n = tab.length) == 0)
tab = initTable();
1处,把field table,赋值给局部变量tab
2处,如果tab为null,则进行initTable初始化
这个2处,在多线程put的时候,是可能多个线程同时进来的。有并发问题。
我们接下来,看看initTable是怎么解决这个问题的,毕竟,我们new数组,只new一次即可,new那么多次,没用,对性能有损耗。所以,这里面肯定会多线程争夺初始化权利的代码。
private transient volatile int sizeCtl;
transient volatile Node<K,V>[] table;
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab;
int sc;
// 0
while ((tab = table) == null || tab.length == 0) {
// 1
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// 2
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
// 3
if ((tab = table) == null || tab.length == 0) {
// 4
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
// 5
sizeCtl = sc;
}
break;
}// end if
}// end while
return tab;
}
1处,这里把sizeCtl,赋值给局部变量sc。这里的sizeCtl是一个很重要的field,当我们new完之后,默认这个字段,要么为0,要么为准备创建的底层数组的长度。
这里去判断是否小于0,那肯定不满足,小于0,会是什么意思?当某个线程,抢到了这个initTable中的底层数组的创建权利时,就会把sizeCtl改为 -1。
所以,这里的意思是,看看是否已经有其他线程在初始化了,如果已经有了,则直接调用:
Thread.yield();
这个方法的意思是,暗示操作系统,自己准备放弃cpu;但操作系统,自有它自己的线程调度规则,所以,这个方法可能没什么效果;我们业务代码,这里一般可以修改为Thread.sleep。
这个方法调用完成后,后续也没有其他代码,所以会直接跳转到循环开始处(0处代码),判断table是否初始化ok了,如果没有ok,则会继续进来。
2处,使用cas,如果此时,sizeCtl的值等于sc的值,就修改sizeCtl为 -1;如果成功,则返回true,进入3处
否则,会跳转到0处,继续循环。
3处,虽然抢到了控制权,但是这里还是要再判断一下,不然可能出现重复初始化,即,不加这一行,4处的代码,会被重复执行
4处开始,这里去执行真正的初始化逻辑。
//
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
// 1
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
// 2
table = tab = nt;
sc = n - (n >>> 2);
这里的1处,new数组;2处,赋值给field:table;此时,因为table 这个field是volatile修饰的,所以其他线程会马上感知到。0处代码就不会为true了,就不会继续循环了。
5处,修改sizeCtl为正数。
这里说下,为啥要加3处的那个判断。
现在,假设线程A,在初始化完成后,走到了5处,修改了sizeCtl为正数;而线程B,刚好执行1处代码:
// 1
if ((sc = sizeCtl) < 0)
那肯定,1处就不满足了;然后就会进到2处,cas修改成功,进行初始化。没有3处判断的话,就会重复初始化。
基于concurrentHashmap,实现我们的缓存雪崩方案
我这里的方案,还是比较简单那种,就是,n个线程同时争夺构建缓存的权利;winner线程,构建缓存后,会把缓存设置到redis;其他线程则是一直在while(true)里sleep一段时间,然后检查redis里的数据是否不为空。
这个方案中,redis挂了这种情况,是没在考虑中的,但是一个方案,没办法立马各方面全部到位,后续我再完善一下。
不考虑缓存雪崩的代码
@Override
public Users getUser(long userId) {
ValueOperations<String, Users> ops = redisTemplate.opsForValue();
// 1
Users s = ops.get(String.valueOf(userId));
if (s == null) {
/**
* 2 这里要去查库获取值
*/
Users users = getUsersFromDB(userId);
// 3
ops.set(String.valueOf(users.getUserId()),users);
return users;
}
return s;
}
private Users getUsersFromDB(long userId) {
Users users = new Users();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("spent 1s to get user from db");
users.setUserId(userId);
users.setUserName("zhangsan");
return users;
}
直接看上面的1,2,3处。就是检查、构建缓存,设置到缓存的过程。
考虑缓存雪崩的代码
// 1
private volatile int initControl;
@Override
public Users getUser(long userId) {
ValueOperations<String, Users> ops = redisTemplate.opsForValue();
Users users;
while (true) {
// 2
users = ops.get(String.valueOf(userId));
if (users != null) {
// 3
break;
}
// 4
int initControlLocal = initControl;
/**
* 5 如果已经有线程在进行获取了,则直接放弃cpu
*/
if (initControlLocal < 0) {
// log.info("initControlLocal < 0,just yield and wait");
// Thread.yield();
try {
Thread.sleep(50);
} catch (InterruptedException e) {
log.warn("e:{}", e);
}
continue;
}
/**
* 6 争夺控制权
*/
boolean bGotChanceToInit = U.compareAndSwapInt(this,
INIT_CONTROL, initControlLocal, -1);
// 7
if (bGotChanceToInit) {
try {
// 8
users = ops.get(String.valueOf(userId));
if (users == null) {
log.info("got change to init");
/**
* 9 这里要去查库获取值
*/
users = getUsersFromDB(userId);
ops.set(String.valueOf(users.getUserId()), users);
log.info("init over");
}
} finally {
// 10
initControl = 0;
}
break;
}// end if (bGotChanceToInit)
}// end while
return users;
}
1处,定义了一个field,initControl;默认为0.线程们会去使用cas,修改为-1,成功的线程,即获得初始化缓存的权利。
注意,要定义为volatile,保证线程间的可见性
2处,去redis获取缓存,如果不为null,直接返回
4处,如果没取到缓存,则进入此处;此处,将field:initControl赋值给局部变量
5处,判断局部变量initControlLocal,是否小于0;小于0,说明已经有线程在进行初始化了,直接contine,继续下一次循环
6处,如果当前还没有线程在初始化,则开始竞争初始化的权利,谁成功地用cas,修改field:initControl为-1,谁就获得这个权利
7处,如果当前线程获得了权利,则进入8处,否则,会继续下一次循环
8处,再次去redis,获取缓存,如果不为空,则进入9处
9处,查库,设置缓存
10处,修改field:initControl为0,表示退出初始化
这里的代码,整体和hashmap中的initTable是一模一样的。
如何测试
上面的方案,怎么测试没问题呢?我写了一段测试代码。
ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 100,
60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1000), new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
log.info("discard:{}",r);
}
});
@RequestMapping("/test.do")
public void test() {
// 0
iUsersService.deleteUser(111L);
CyclicBarrier barrier = new CyclicBarrier(100);
for (int i = 0; i < 100; i++) {
executor.submit(new Runnable() {
@Override
public void run() {
try {
barrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
long start = System.currentTimeMillis();
// 1
Users users = iUsersService.getUser(111L);
log.info("result:{},spent {} ms", users, System.currentTimeMillis() - start);
}
});
}
}
上面模拟100并发下,获取缓存。
0处,把缓存删了,模拟缓存失效
1处,调用方法,获取缓存。
效果如下:
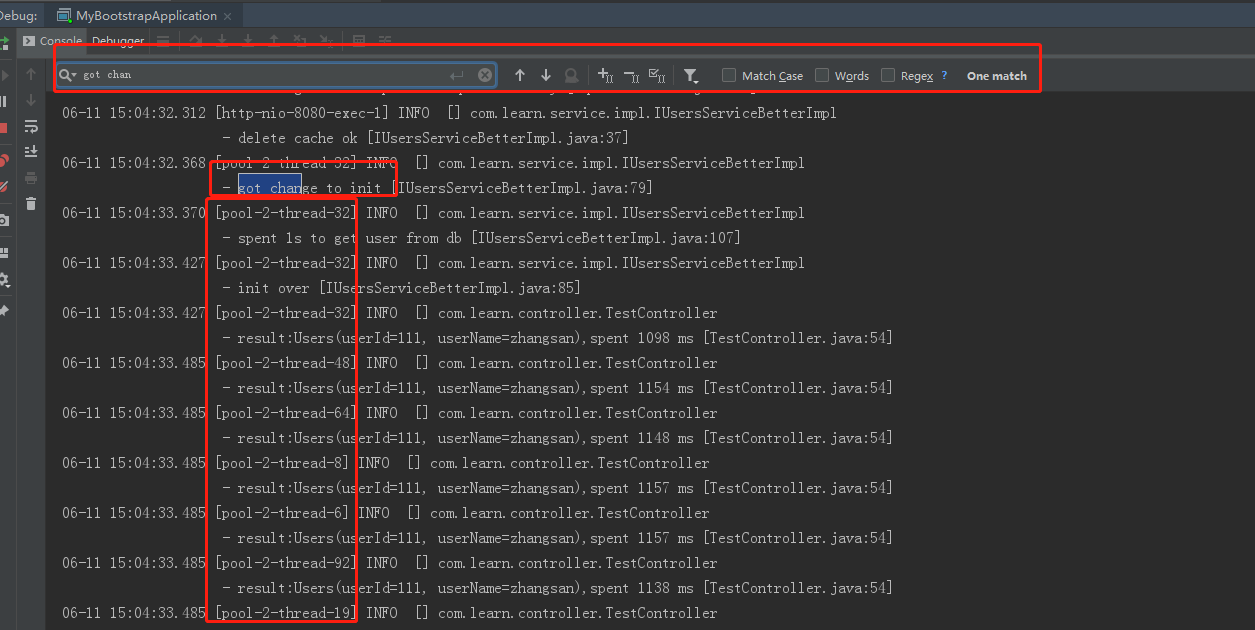
可以看到,只有一个线程拿到了初始化权利。
源码位置
https://gitee.com/ckl111/all-simple-demo-in-work-1/tree/master/redis-cache-avalanche
总结
jdk的并发包,写得真是有水平,大家仔细研究的话,必有收获。
曹工说JDK源码(4)--抄了一小段ConcurrentHashMap的代码,我解决了部分场景下的Redis缓存雪崩问题的更多相关文章
- 曹工说JDK源码(2)--ConcurrentHashMap的多线程扩容,说白了,就是分段取任务
前言 先预先说明,我这边jdk的代码版本为1.8.0_11,同时,因为我直接在本地jdk源码上进行了部分修改.调试,所以,导致大家看到的我这边贴的代码,和大家的不太一样. 不过,我对源码进行修改.重构 ...
- 曹工说JDK源码(1)--ConcurrentHashMap,扩容前大家同在一个哈希桶,为啥扩容后,你去新数组的高位,我只能去低位?
如何计算,一对key/value应该放在哪个哈希桶 大家都知道,hashmap底层是数组+链表(不讨论红黑树的情况),其中,这个数组,我们一般叫做哈希桶,大家如果去看jdk的源码,会发现里面有一些变量 ...
- 曹工说JDK源码(3)--ConcurrentHashMap,Hash算法优化、位运算揭秘
hashcode,有点讲究 什么是好的hashcode,一般来说,一个hashcode,一般用int来表示,32位. 下面两个hashcode,大家觉得怎么样? 0111 1111 1111 1111 ...
- JDK源码分析(12)之 ConcurrentHashMap 详解
本文将主要讲述 JDK1.8 版本 的 ConcurrentHashMap,其内部结构和很多的哈希优化算法,都是和 JDK1.8 版本的 HashMap是一样的,所以在阅读本文之前,一定要先了解 Ha ...
- 结合JDK源码看设计模式——简单工厂、工厂方法、抽象工厂
三种工厂模式的详解: 简单工厂模式: 适用场景:工厂类负责创建的对象较少,客户端只关心传入工厂类的参数,对于如何创建对象的逻辑不关心 缺点:如果要新加产品,就需要修改工厂类的判断逻辑,违背软件设计中的 ...
- 跟踪调试JDK源码时遇到的问题及解决方法
目录 问题描述 解决思路 在IntelliJ IDEA中调试JDK源码 在eclipse中调试JDK源码 总结 问题描述 最近在研究MyBatis的缓存机制,需要回顾一下HashMap的实现原理.于是 ...
- 关于JDK源码:我想聊聊如何更高效地阅读
简介 大家好,我是彤哥,今天我想和大家再聊聊JDK源码的几个问题: 为什么要看JDK源码 JDK源码的阅读顺序 JDK源码的阅读方法 为什么要看JDK源码 一,JDK源码是其它所有源码的基础,看懂了J ...
- 重新编译jdk源码,启用debug信息
我有一个不知道是好还是不好的习惯,搞不懂的一些玩意儿,喜欢调试然后单步执行看这玩意儿到底是怎么运行的. 今天看到正则表达式的时候,appendReplacement()这个方法怎么也看不明白它是怎么工 ...
- 使用NetBeans、Eclipse阅读JDK源码
下面说明在Netbeans.Eclipse环境下怎么查看JDK源码: Netbeans: 在"工具->java平台->源"里添加下路径,如果你安装jdk的时候选择安装了 ...
随机推荐
- ios上表单默认样式
摘自:http://blog.sina.com.cn/s/blog_7d796c0d0102uyd2.html 可惜不能直接转到博客园. input[type="button"], ...
- HTML标签和属性三
八.列表 1.列表的作用 让数据有条理的显示,在数据之前添加标识 但是现在页面布局,经常会使用到无序列表 2.列表的组成 ①有序列表 <ol> <li></li> ...
- [Asp.Net Core] Blazor Server Side 扩展用途 - 配合CEF来制作带浏览器核心的客户端软件 (二) 可运行版本
前言 大概3个星期之前立项, 要做一个 CEF+Blazor+WinForms 三合一到同一个进程的客户端模板. 这个东西在五一的时候做出了原型, 然后慢慢修正, 在5天之前就上传到github了. ...
- 安卓网络编程学习(1)——java原生网络编程(1)
写在前面 马上要进行第二轮冲刺,考虑到自己的APP在第一轮冲刺的效果不尽人意,有很多网络方面的小BUG,这里就系统学习一下网络编程,了解来龙去脉,以便更好的对项目进行优化处理. http协议 http ...
- Spring 依赖注入(DI)简介
依赖注入的英文表示为dependency injection,缩写为DI. Spring框架的核心功能之一就是通过依赖注入的方式来管理Bean之间的依赖关系. 当编写一个复杂的 Java 应用程序时, ...
- springboot使用Jwt处理跨域认证问题
在前后端开发时为什么需要用户认证呢?原因是由于HTTP协定是不存储状态的,这意味着当我们透过账号密码验证一个使用者时,当下一个request请求时他就把刚刚的资料忘记了.于是我们的程序就不知道谁是谁了 ...
- Nginx 配置文件语法
一.语法规则: location [=|~|~*|^~] /uri/ { … } = 开头表示精确匹配 ^~ 开头表示uri以某个常规字符串开头,理解为匹配 url路径即可.nginx不对url做编码 ...
- react中路由不起作用的奇怪现象
同样的两段Router代码,为什么一段正常,一段不起作用(也没有任何错误log提示) 瞪着眼观察也看不出为什么... 通过选中高亮显示内容相同, 为何就是有一段路由不管用呢? 折腾半天发现... 大小 ...
- Java:成员变量、局部变量和静态变量
梳理一下: 根据定义变量位置的不同,可以将变量分成两大类:成员变量和局部变量. 成员变量(俗称全局变量):在类里定义的变量.又分为实例变量和类变量(也成为静态变量). 实例变量:不以static修饰, ...
- php mysqli使用
连接到数据库$mysqli = new mysqli(主机,用户,密码,数据库); 选择数据库$mysqli->select_db(数据库);设置编码$mysqli->set_charse ...