前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
目 标 场 景
相信大家平时刷抖音短视频的时候,看到颜值高的小姐姐,都有随手点赞关注的习惯。
如果一条条去刷确实很耗时间,如果 Python 能帮忙筛选出颜值高的小姐姐那就省了很多事。
本篇文章是借助「百度人脸识别」API,帮我们识别出抖音上颜值高的小姐姐,然后下载到手机相册中。
准 备 工 作
首先,项目需要对页面元素进行一些精准的操作,需要提前准备一部 Android 设备,激活开发者选项,并在开发者选项中打开 「USB 调试和指针位置」两处设置。
为了确保 adb 命令能正常使用,需要提前配置好 adb 开发环境。
页面元素中的部分元素没法利用 name 等常用属性获取到,可能需要获取到完整的「UI 树」,再利用 Airtest 判断是否存在某个 UI 元素。
# 安装依赖 pip3 install pocoui
另外,项目中会对视频进行人脸识别,获取到出现的所有人脸,再进行性别识别及颜值判断。
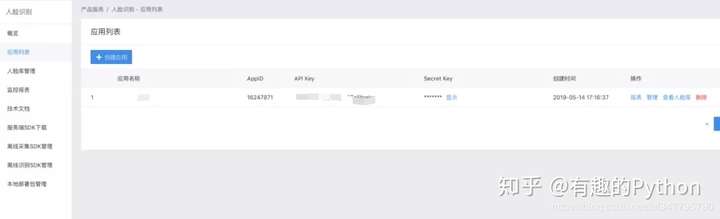
这里需要进行百度云后台,注册一个人脸识别的应用,获取到一组 「API Key 和 Secret Key」值。
然后利用官网提供的 API 文档即可获取到「access token」,由于 ak 的有效期为一个月,所以只需要初始化一次,后面就可以利用人脸识别接口进行正常的识别了。
appid = '你注册应用的appid' api_key = '你注册应用的ak' secret_key = '你注册应用的sk' def get_access_token(): """ 其关access_token有效期一般有一个月 """ # 此变量赋值成自己API Key的值 client_id = api_key # 此变量赋值成自己Secret Key的值 client_secret = secret_key auth_url = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + client_id + '&client_secret=' + client_secret header_dict = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko', "Content-Type": "application/json"} # 请求获取到token的接口 response_at = requests.get(auth_url, headers=header_dict) json_result = json.loads(response_at.text) access_token = json_result['access_token'] return access_token
编 写 脚 本
在上面已经配置好了 adb 环境的情况下,可以直接借助 python 中的 os 模块执行 adb 命令打开抖音 App。
# 抖音App的应用包名和初始Activity package_name = 'com.ss.android.ugc.aweme' activity_name = 'com.ss.android.ugc.aweme.splash.SplashActivity' def start_my_app(package_name, activity_name): """ 打开应用 adb shell am start -n com.tencent.mm/.ui.LauncherUI :param package_name: :return: """ os.popen('adb shell am start -n %s/%s' % (package_name, activity_name))
接着,我们需要截取当前播放视频的截图到本地。 需要注意的是,抖音视频播放界面包含视频创作者头像、BGM 创作者头像等一些杂乱的元素,可能对人脸识别的结果产生一些误差,所以需要对屏幕截图之后的图像进行「二次裁剪」处理。
def get_screen_shot_part_img(image_name): """ 获取手机截图的部分内容 :return: """ # 截图 os.system("adb shell /system/bin/screencap -p /sdcard/screenshot.jpg") os.system("adb pull /sdcard/screenshot.jpg %s" % image_name) # 打开图片 img = Image.open(image_name).convert('RGB') # 图片的原宽、高(1080*2160) w, h = img.size # 截取部分,去掉其头像、其他内容杂乱元素 img = img.crop((0, 0, 900, 1500)) img.thumbnail((int(w / 1.5), int(h / 1.5))) # 保存到本地 img.save(image_name) return image_name
现在可以使用百度提供的 API 获取到上面截图的人脸列表。
def parse_face_pic(pic_url, pic_type, access_token): """ 人脸识别 5秒之内 :param pic_url: :param pic_type: :param access_token: :return: """ url_fi = 'https://aip.baidubce.com/rest/2.0/face/v3/detect?access_token=' + access_token # 调用identify_faces,获取人脸列表 json_faces = identify_faces(pic_url, pic_type, url_fi) if not json_faces: print('未识别到人脸') return None else: # 返回所有的人脸 return json_faces
从上述的人脸列表中筛选出性别为女,年龄为 18-30 岁之间,颜值超过 70 的小姐姐。
def analysis_face(face_list): """ 分析人脸,判断颜值是否达标 18-30之间,女,颜值大于80 :param face_list:识别的脸的列表 :return: """ # 是否能找到高颜值的美女 find_belle = False if face_list: print('一共识别到%d张人脸,下面开始识别是否有美女~' % len(face_list)) for face in face_list: # 判断是男、女 if face['gender']['type'] == 'female': age = face['age'] beauty = face['beauty'] if 18 <= age <= 30 and beauty >= 70: print('颜值为:%d,及格,满足条件!' % beauty) find_belle = True break else: print('颜值为:%d,不及格,继续~' % beauty) continue else: print('性别为男,继续~') continue else: print('图片中没有发现人脸.') return find_belle
由于视频是连续播放的,很难通过截取视频某一帧,判断视频有出现颜值高的小姐姐。
另外,大部分短视频播放时长为「10s+」,这里需要对每一个视频多次截图去做人脸识别,直到识别到颜值高的小姐姐。
# 一条视频最长的识别时间 RECOGNITE_TOTAL_TIME = 10 # 识别次数 recognite_count = 1 # 对当前视频截图去人脸识别 while True: # 获取截图 print('开始第%d次截图' % recognite_count) # 截取屏幕有用的区域,过滤视频作者的头像、BGM作者的头像 screen_name = get_screen_shot_part_img('images/temp%d.jpg' % recognite_count) # 人脸识别 recognite_result = analysis_face(parse_face_pic(screen_name, TYPE_IMAGE_LOCAL, access_token)) recognite_count += 1 # 第n次识别结束后的时间 recognite_time_end = datetime.now() # 这一条视频出现了颜值高的小姐姐 if recognite_result: pass else: print('超时!!!这是一条没有吸引力的视频!') # 跳出里层循环 break
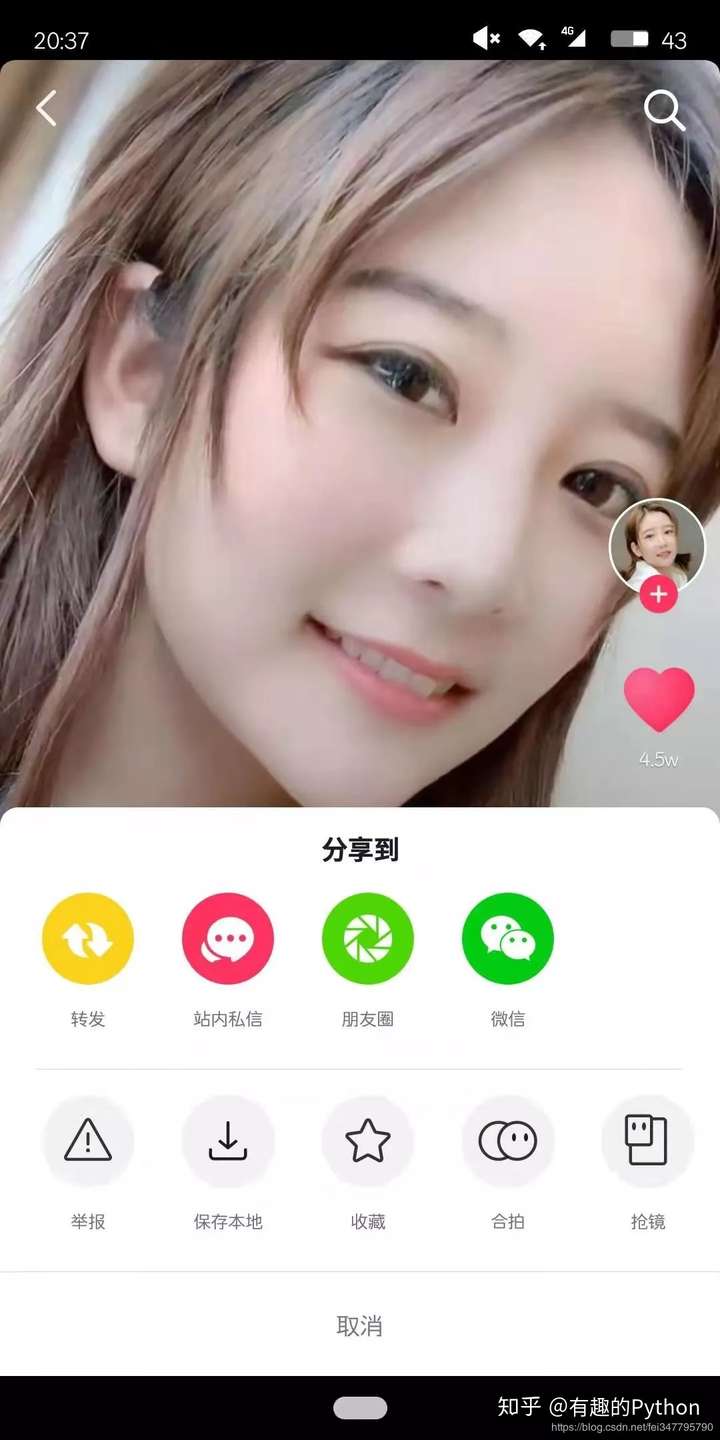
一旦当前播放的视频识别出有颜值高的小姐姐,就需要模拟保存视频到本地的操作。
获取「分享」和「保存本地」两个按钮的坐标位置,依次利用 adb 执行点击操作即可下载视频到本地。
def save_video_met(): """ :return: """ # 分享 os.system("adb shell input tap 1000 1500") time.sleep(0.05) # 保存到本地 os.system("adb shell input tap 350 1700")
另外,由于下载视频的过程是一个耗时操作,在下载进度对话框还未消失之前,需要做一个「模拟等待」的操作。
def wait_for_download_finished(poco): """ 从点击下载,到下载完全 :return: """ element = Element() while True: # 由于是对话框,不能利用Element类来判断是否存在某个元素来准确处理 # element_result = element.findElementByName('正在保存到本地') # 当前页面UI树元素信息 # 注意:保存的时候可能会获取元素异常,这里需要抛出,并终止循环 # com.netease.open.libpoco.sdk.exceptions.NodeHasBeenRemovedException: Node was no longer alive when query attribute "visible". Please re-select. try: ui_tree_content = json.dumps(poco.agent.hierarchy.dump(), indent=4).encode('utf-8').decode('unicode_escape') except Exception as e: print(e) print('异常,按下载处理~') break if '正在保存到本地' in ui_tree_content: print('还在下载中~') time.sleep(0.5) continue else: print('下载完成~') break
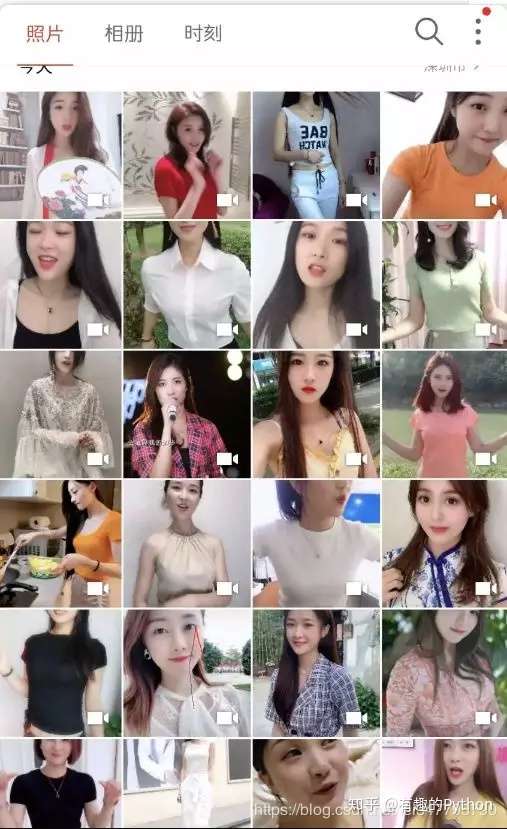
在视频保存到本地之后,就可以模拟向上滑动的操作,跳到播放「下一条视频」。 循环上面的操作,即可筛选出所有颜值高的小姐姐,并保存到本地。
def play_next_video(): """ 下一个视频 从下往上滑动 :return: """ os.system("adb shell input swipe 540 1300 540 500 100")
在脚本一条条刷视频的过程中,可能会遇到一下广告,我们需要对这类视频进行过滤。
def is_a_ad(): """ 判断的当前页面上是否是一条广告 :return: """ element = Element() ad_tips = ['去玩一下', '去体验', '立即下载'] find_result = False for ad_tip in ad_tips: try: element_result = element.findElementByName(ad_tip) # 是一条广告,直接跳出 find_result = True break except Exception as e: find_result = False return find_resul
结 果 结 论
运行上面的脚本,会自动打开抖音,对每一条小视频多次进行人脸识别,直到识别到颜值高的小姐姐,保存视频到本地,然后继续刷下一条短视频。
如果你觉得文章还不错,请大家点赞分享下。你的肯定是我最大的鼓励和支持。
- 教你用python爬取抖音app视频
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思 ...
- python爬取抖音APP视频教程
本文讲述爬取抖音APP视频数据(本文未完,后面还有很多地方优化总结) 公众号回复:抖音 即可获取源码 1.APP抓包教程,需要用到fiddler fiddler配置和使用查看>>王者荣耀盒 ...
- 【Python爬虫案例】用Python爬取李子柒B站视频数据
一.视频数据结果 今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至: https://www.cnblogs.com/mashukui/p/1622025 ...
- Python爬取抖音视频
最近在研究Python爬虫,顺便爬了一下抖音上的视频,找到了哥们喜欢的小姐姐居多,咱们给他爬下来吧. 最终爬取结果 好了废话补多说了,上代码! #https://www.iesdouyin.com/a ...
- Python爬取知乎上搞笑视频,一顿爆笑送给大家
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:Huangwei AI 来源:Python与机器学习之路 PS:如有需 ...
- python爬取虎牙直播颜值区美女主播照片
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 python免费学习资 ...
- Python爬虫---爬取抖音短视频
目录 前言 抖音爬虫制作 选定网页 分析网页 提取id构造网址 拼接数据包链接 获取视频地址 下载视频 全部代码 实现结果 待解决的问题 前言 最近一直想要写一个抖音爬虫来批量下载抖音的短视频,但是经 ...
- Python 爬取 猫眼 top100 电影例子
一个Python 爬取猫眼top100的小栗子 import json import requests import re from multiprocessing import Pool #//进程 ...
- 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
抖音很火,楼主使用python随机爬取抖音视频,并且无水印下载,人家都说天下没有爬不到的数据,so,楼主决定试试水,纯属技术爱好,分享给大家.. 1.楼主首先使用Fiddler4来抓取手机抖音app这 ...
随机推荐
- [CVPR 2019]Normalized Object Coordinate Space for Category-Level 6D Object Pose and Size Estimation
论文地址:https://arxiv.org/abs/1901.02970 github链接:https://github.com/hughw19/NOCS_CVPR2019 类别级6D物体位姿 ...
- 详解firewalld 和iptables
在RHEL7里有几种防火墙共存:firewalld.iptables.ebtables,默认是使用firewalld来管理netfilter子系统,不过底层调用的命令仍然是iptables等. fir ...
- cin.getline()的用法和坑
cin.getline()的用法和坑 cin.getline大致原型:**istream& getline (char* s, streamsize n, char delim='\n');* ...
- Building Applications with Force.com and VisualForce(Dev401)(十五):Data Management: Data management Overview
Dev401-016:Data Management: Data management Overview Course Objectives1.List typical data management ...
- CF 1012C Dp
Welcome to Innopolis city. Throughout the whole year, Innopolis citizens suffer from everlasting cit ...
- 30款Django 常用的软件包
30款Django 常用的软件包 Django是一款高级的Python Web框架,可以帮助开发者快速创建web应用.我们这里整理了30款Django开发中常用的软件包,学会使用它们可以节省大量开发时 ...
- Ubuntu 18 安装MySQL 5.7
1.首先把系统换到阿里云的镜像源,需要等待一会 2.系统更新完毕后执行MySQL安装命令:sudo apt install mysql-server 3.查看MySQL服务状态:sudo servic ...
- 操作系统-IO与显示器
1. 让外设工作起来 只要给相应的控制器中的寄存器发一个指令 向设备控制器的寄存器写不就可以了吗? 需要查寄存器地址.内容的格式和语义.操作系统需要给用户提供一个简单视图---文件视图,这样方便 总的 ...
- Blazor入门笔记(6)-组件间通信
1.环境 VS2019 16.5.1.NET Core SDK 3.1.200Blazor WebAssembly Templates 3.2.0-preview2.20160.5 2.简介 在使用B ...
- DALI 48V驱动
DALI-CC-30W-48V技术手册 产品名称:DALI-CC-30W-48V 支持协议:IEC 62386-101:2018,IEC 62386-102:2018,IEC 62386-207:20 ...