TensorFlow 多元线性回归【波士顿房价】
1数据读取
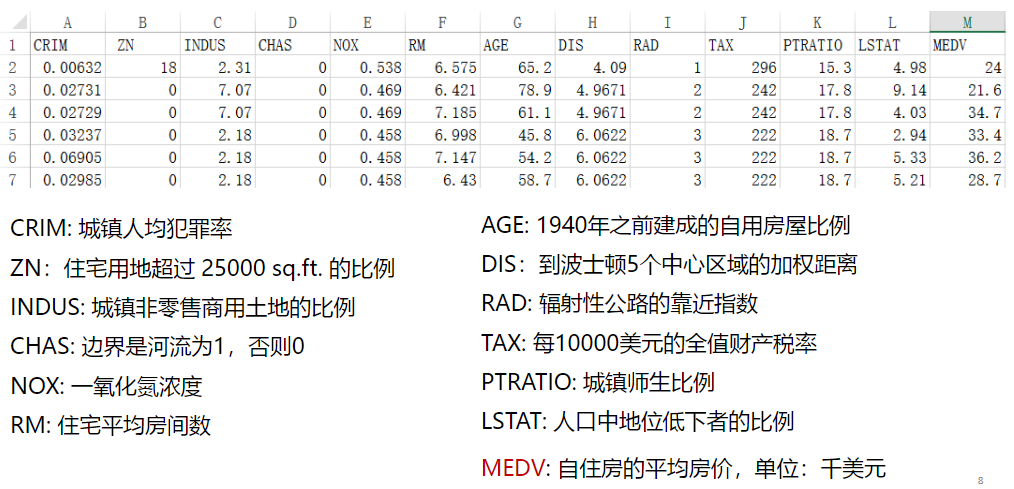
1.1数据集解读
1.2引入包
%matplotlib notebook import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.utils import shuffle1.2.1pandas介绍
1.2.2TensorFlow下安装pandas
1、激活tensorflow: Activate tensorflow
2、安装Pandas: conda install pandas1.2.3出现“No module named 'sklearn'”错误
原因:未安装sklearn模块
方法:
在anaconda 中安装: conda install scikit-learn1.3显示数据
# 读取数据文件 boston.csv文件位置自填
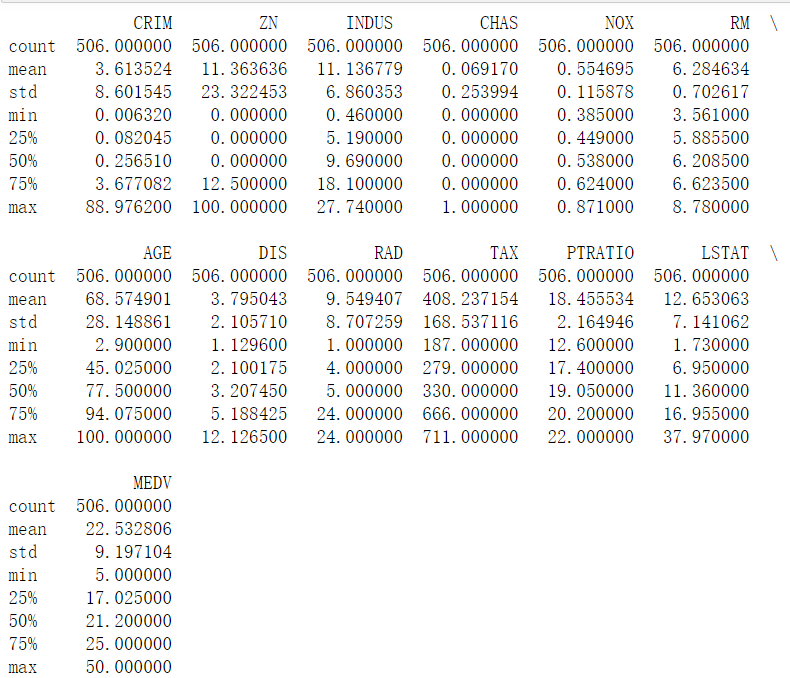
df = pd.read_csv("D:\学习资料\课程学习资料\深度学习\TensorFlow/boston.csv",header = 0) # 显示数据摘要描述信息
print(df.describe()
# 打印所有数据,只显示前30行和后三十行
print(df)
# 获取df的值
df = df.values
print(df)
# 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能
df = np.array(df)
print(df)
# x_data为前12列的数据,实际上是0 - 11列;y_data为最后一列的数据,即12列
x_data = df[:,:12]
y_data = df[:,12]
print(x_data,"\nshape = ",x_data.shape)
print(y_data,"\nshape = ",y_data.shape)
2模型定义
2.1定义训练的占位符
#定义特征数据和标签数据的占位符
#shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一
#个样本的随机SDG到批量SDG都可以
x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列)
y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列)2.2定义模型结构
定义模型函数
# 定义一个命名空间
with tf.name_scope("model"):
# w 初始化值为shape = (12,1)的随机数 stddev为标准差
w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w")
# b 初始化值为 1.0
b = tf.Variable(1.0,name = "b")
#w和x是矩阵相乘,用matmul,不能用mutiply或*
def model(x,w,b):
return tf.matmul(x,w) + b #预测计算操作,前向计算节点
pred = model(x,w,b)3模型训练
3.1设置训练超参数
# 迭代轮次
train_epochs = 50 # 学习率
learning_rate = 0.013.2定义均方差损失函数
#定义均方差损失函数
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y -pred,2))3.3选择优化器
# 创建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function)常用优化器包括:
tf.train.GradientDescentOptimizer
tf.train.AdadeltaOptimizer
tf.train.AdagradOptimizer
tf.train.AdagradDAOptimizer
tf.train.MomentumOptimizer
tf.train.AdamOptimizer
tf.train.FtrlOptimizer
tf.train.ProximalGradientDescentOptimizer
tf.train.ProximalAdagradOptimizer
tf.train.RMSPropOptimizer3.4声明会话
#声明回话
sess = tf.Session()
#定义初始化变量的操作
init = tf.global_variables_initializer()
#启动会话
sess.run(init)3.5迭代训练
#迭代训练
for epoch in range(train_epochs):
loss_sum = 0.0
for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组
xs = xs.reshape(1,12)
ys = ys.reshape(1,1)
# Feed 数据必须和Placeholder 的shape 一致
_,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss #打乱数据顺序
x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
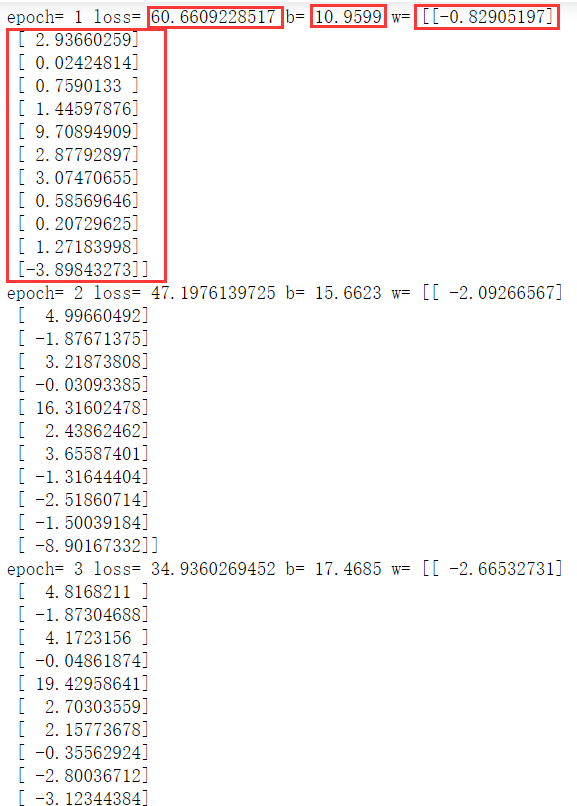
loss_average = loss_sum / len(y_data) print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)
注:训练结果异常
3.6异常明示
3.6.1原因
3.6.2方法
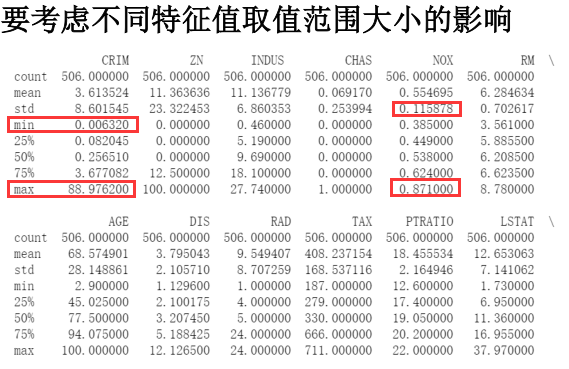
4特征归一化版本
%matplotlib notebook import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.utils import shuffle # 读取数据文件
df = pd.read_csv("D:\学习资料\课程学习资料\深度学习\TensorFlow/boston.csv",header = 0) # 显示数据摘要描述信息
print(df.describe()) # 获取df的值
df = df.values
print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能
df = np.array(df)
print(df)特征归一化
# 对特征数据 【0到11】列 做 (0-1)归一化
for i in range(12):
df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12]
#y_data 为最后一列标签数据 y_data = df[:,12]#定义特征数据和标签数据的占位符
#shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一
#个样本的随机SDG到批量SDG都可以
x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列)
y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间
with tf.name_scope("model"):
# w 初始化值为shape = (12,1)的随机数 stddev为标准差
w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w")
# b 初始化值为 1.0
b = tf.Variable(1.0,name = "b")
#w和x是矩阵相乘,用matmul,不能用mutiply或*
def model(x,w,b):
return tf.matmul(x,w) + b #预测计算操作,前向计算节点
pred = model(x,w,b) # 迭代轮次
train_epochs = 50 # 学习率
learning_rate = 0.01 #定义均方差损失函数
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话
sess = tf.Session()
#定义初始化变量的操作
init = tf.global_variables_initializer()
#启动会话
sess.run(init) #迭代训练
for epoch in range(train_epochs):
loss_sum = 0.0
for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组
xs = xs.reshape(1,12)
ys = ys.reshape(1,1)
# Feed 数据必须和Placeholder 的shape 一致
_,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss #打乱数据顺序
x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
loss_average = loss_sum / len(y_data) print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)
注:Done!
5模型应用
5.1做预测
# 指定一条数据
n = 345
x_test = x_data[n] x_test = x_test.reshape(1,12)
predict = sess.run(pred,feed_dict={x:x_test})
print("预测值:%f" % predict) target = y_data[n]
print("标签值:%f" % target
# 随机确定一条数据
n = np.random.randint(506)
print(n)
x_test = x_data[n] x_test = x_test.reshape(1,12)
predict = sess.run(pred,feed_dict={x:x_test})
print("预测值:%f" % predict) target = y_data[n]
print("标签值:%f" % target)

6可视化训练过程中的损失值
6.1每轮训练后添加一个这一轮的Loss值
%matplotlib notebook import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.utils import shuffle # 读取数据文件
df = pd.read_csv("D:\学习资料\课程学习资料\深度学习\TensorFlow/boston.csv",header = 0) # 获取df的值
df = df.values
print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能
df = np.array(df)
print(df) # 对特征数据 【0到11】列 做 (0-1)归一化 for i in range(12):
df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12]
#y_data 为最后一列标签数据 y_data = df[:,12] #定义特征数据和标签数据的占位符
#shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一
#个样本的随机SDG到批量SDG都可以
x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列)
y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间
with tf.name_scope("model"):
# w 初始化值为shape = (12,1)的随机数 stddev为标准差
w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w")
# b 初始化值为 1.0
b = tf.Variable(1.0,name = "b")
#w和x是矩阵相乘,用matmul,不能用mutiply或*
def model(x,w,b):
return tf.matmul(x,w) + b #预测计算操作,前向计算节点
pred = model(x,w,b) # 迭代轮次
train_epochs = 50 # 学习率
learning_rate = 0.01 #定义均方差损失函数
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话
sess = tf.Session()
#定义初始化变量的操作
init = tf.global_variables_initializer()
#启动会话
sess.run(init)# 用于保存 loss值得列表
loss_list = [] #迭代训练
for epoch in range(train_epochs):
loss_sum = 0.0
for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组
xs = xs.reshape(1,12)
ys = ys.reshape(1,1)
# Feed 数据必须和Placeholder 的shape 一致
_,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss #打乱数据顺序
x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
loss_average = loss_sum / len(y_data) loss_list.append(loss_average) # 每轮训练后添加一个这一轮得loss平均值 print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)6.1.2可视化损失值
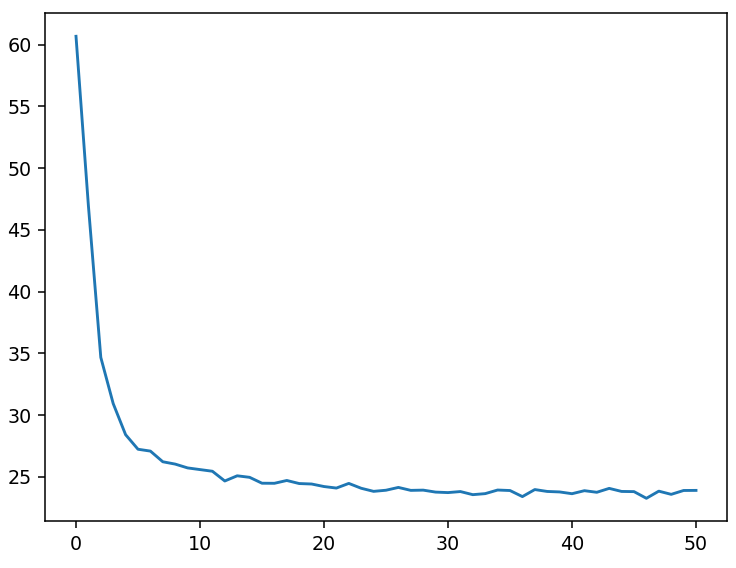
plt.figure()
plt.plot(loss_list)
# 指定一条数据
n = 345
x_test = x_data[n] x_test = x_test.reshape(1,12)
predict = sess.run(pred,feed_dict={x:x_test})
print("预测值:%f" % predict) target = y_data[n]
print("标签值:%f" % target)
6.2每步(单个样本)训练后添加这个Loss值
%matplotlib notebook import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.utils import shuffle # 读取数据文件
df = pd.read_csv("D:\学习资料\课程学习资料\深度学习\TensorFlow/boston.csv",header = 0) # 获取df的值
df = df.values
print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能
df = np.array(df)
print(df) # 对特征数据 【0到11】列 做 (0-1)归一化 for i in range(12):
df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12]
#y_data 为最后一列标签数据 y_data = df[:,12] #定义特征数据和标签数据的占位符
#shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一
#个样本的随机SDG到批量SDG都可以
x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列)
y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间
with tf.name_scope("model"):
# w 初始化值为shape = (12,1)的随机数 stddev为标准差
w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w")
# b 初始化值为 1.0
b = tf.Variable(1.0,name = "b")
#w和x是矩阵相乘,用matmul,不能用mutiply或*
def model(x,w,b):
return tf.matmul(x,w) + b #预测计算操作,前向计算节点
pred = model(x,w,b) # 迭代轮次
train_epochs = 50 # 学习率
learning_rate = 0.01 #定义均方差损失函数
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话
sess = tf.Session()
#定义初始化变量的操作
init = tf.global_variables_initializer()
#启动会话
sess.run(init)
# 用于保存 loss值得列表
loss_list = [] #迭代训练
for epoch in range(train_epochs):
loss_sum = 0.0
for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组
xs = xs.reshape(1,12)
ys = ys.reshape(1,1)
# Feed 数据必须和Placeholder 的shape 一致
_,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss
loss_list.append(loss) # 每步添加一次 #打乱数据顺序
x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
loss_average = loss_sum / len(y_data) print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)6.2.2可视化损失值
plt.figure()
plt.plot(loss_list)
# 指定一条数据
n = 345
x_test = x_data[n] x_test = x_test.reshape(1,12)
predict = sess.run(pred,feed_dict={x:x_test})
print("预测值:%f" % predict) target = y_data[n]
print("标签值:%f" % target)
7加上 TensorBoard 可视化代码
%matplotlib notebook import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.utils import shuffle # 读取数据文件
df = pd.read_csv("D:\学习资料\课程学习资料\深度学习\TensorFlow/boston.csv",header = 0) # 获取df的值
df = df.values
print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能
df = np.array(df)
print(df) # 对特征数据 【0到11】列 做 (0-1)归一化 for i in range(12):
df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12]
#y_data 为最后一列标签数据 y_data = df[:,12] #定义特征数据和标签数据的占位符
#shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一
#个样本的随机SDG到批量SDG都可以
x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列)
y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间
with tf.name_scope("model"):
# w 初始化值为shape = (12,1)的随机数 stddev为标准差
w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w")
# b 初始化值为 1.0
b = tf.Variable(1.0,name = "b")
#w和x是矩阵相乘,用matmul,不能用mutiply或*
def model(x,w,b):
return tf.matmul(x,w) + b #预测计算操作,前向计算节点
pred = model(x,w,b) # 迭代轮次
train_epochs = 50 # 学习率
learning_rate = 0.01 #定义均方差损失函数
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话
sess = tf.Session()
#定义初始化变量的操作
init = tf.global_variables_initializer()
#启动会话
sess.run(init) # 用于保存 loss值得列表
loss_list = [] #迭代训练
for epoch in range(train_epochs):
loss_sum = 0.0
for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组
xs = xs.reshape(1,12)
ys = ys.reshape(1,1)
# Feed 数据必须和Placeholder 的shape 一致
_,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss #打乱数据顺序
x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
loss_average = loss_sum / len(y_data) loss_list.append(loss_average) # 每轮训练后添加一个这一轮得loss平均值 print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)8为TensorFlow可视化准备数据
8.1修改代码
%matplotlib notebook import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.utils import shuffle # 读取数据文件
df = pd.read_csv("D:\学习资料\课程学习资料\深度学习\TensorFlow/boston.csv",header = 0) # 获取df的值
df = df.values
print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能
df = np.array(df)
print(df) # 对特征数据 【0到11】列 做 (0-1)归一化 for i in range(12):
df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12]
#y_data 为最后一列标签数据 y_data = df[:,12] #定义特征数据和标签数据的占位符
#shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一
#个样本的随机SDG到批量SDG都可以
x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列)
y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间
with tf.name_scope("model"):
# w 初始化值为shape = (12,1)的随机数 stddev为标准差
w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w")
# b 初始化值为 1.0
b = tf.Variable(1.0,name = "b")
#w和x是矩阵相乘,用matmul,不能用mutiply或*
def model(x,w,b):
return tf.matmul(x,w) + b #预测计算操作,前向计算节点
pred = model(x,w,b) # 迭代轮次
train_epochs = 50 # 学习率
learning_rate = 0.01 #定义均方差损失函数
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话
sess = tf.Session()
#定义初始化变量的操作
init = tf.global_variables_initializer()8.1.1设置日志存储目录
# 设置日志存储目录
logdir = 'd:/log'8.1.2创建一个操作,用于记录损失值loss ,后面在TensorBoard 中SCALARS 栏可见
# 创建一个操作,用于记录损失值loss ,后面在TensorBoard 中SCALARS 栏可见
sum_loss_op = tf.summary.scalar("loss",loss_function)8.1.3把所有需要记录摘要日志文件得合并,方便一次性写入
#把所有需要记录摘要日志文件得合并,方便一次性写入
merged = tf.summary.merge_all()#启动会话
sess.run(init)8.1.4创建摘要得文件写入器(FileWriter)
#创建摘要write,将计算图写入摘要,后面的在TensorBoard中GRAPHS可见
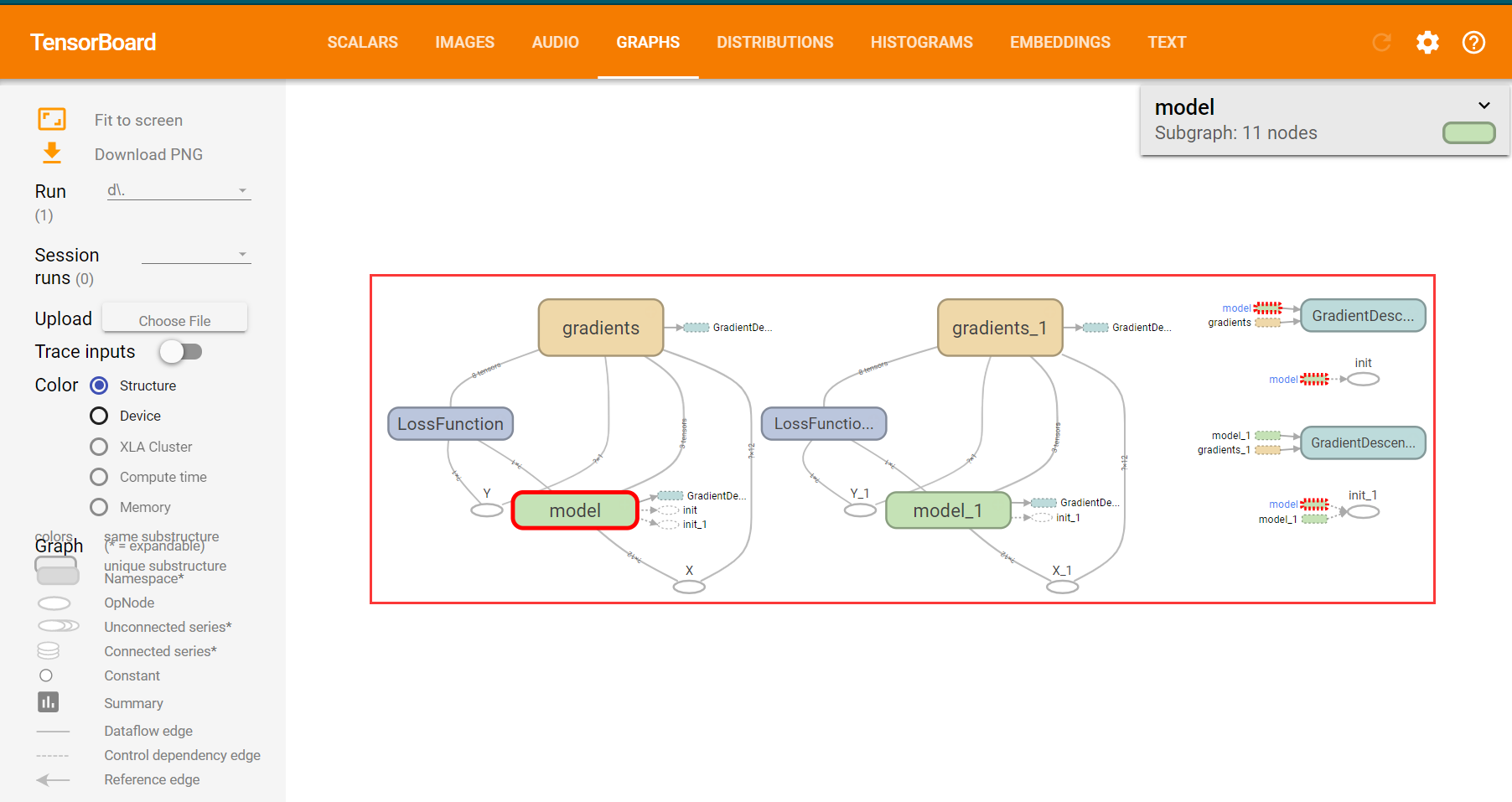
writer = tf.summary.FileWriter(logdir,sess.graph)8.1.5writer.add_summary(summary_str, epoch)
# 用于保存 loss值得列表
loss_list = [] #迭代训练
for epoch in range(train_epochs):
loss_sum = 0.0
for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组
xs = xs.reshape(1,12)
ys = ys.reshape(1,1)
# Feed 数据必须和Placeholder 的shape 一致
_,summary_str,loss = sess.run([optimizer,sum_loss_op,loss_function],feed_dict={x:xs,y:ys}) writer.add_summary(summary_str,epoch)
loss_sum = loss_sum + loss #打乱数据顺序
x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
loss_average = loss_sum / len(y_data) loss_list.append(loss_average) # 每轮训练后添加一个这一轮得loss平均值 print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)8.2运行TensorBoard
8.2.1打开Anaconda Prompt
激活TensorFlow: Activate tensorflow
进入日志存储目录 : cd d:\log
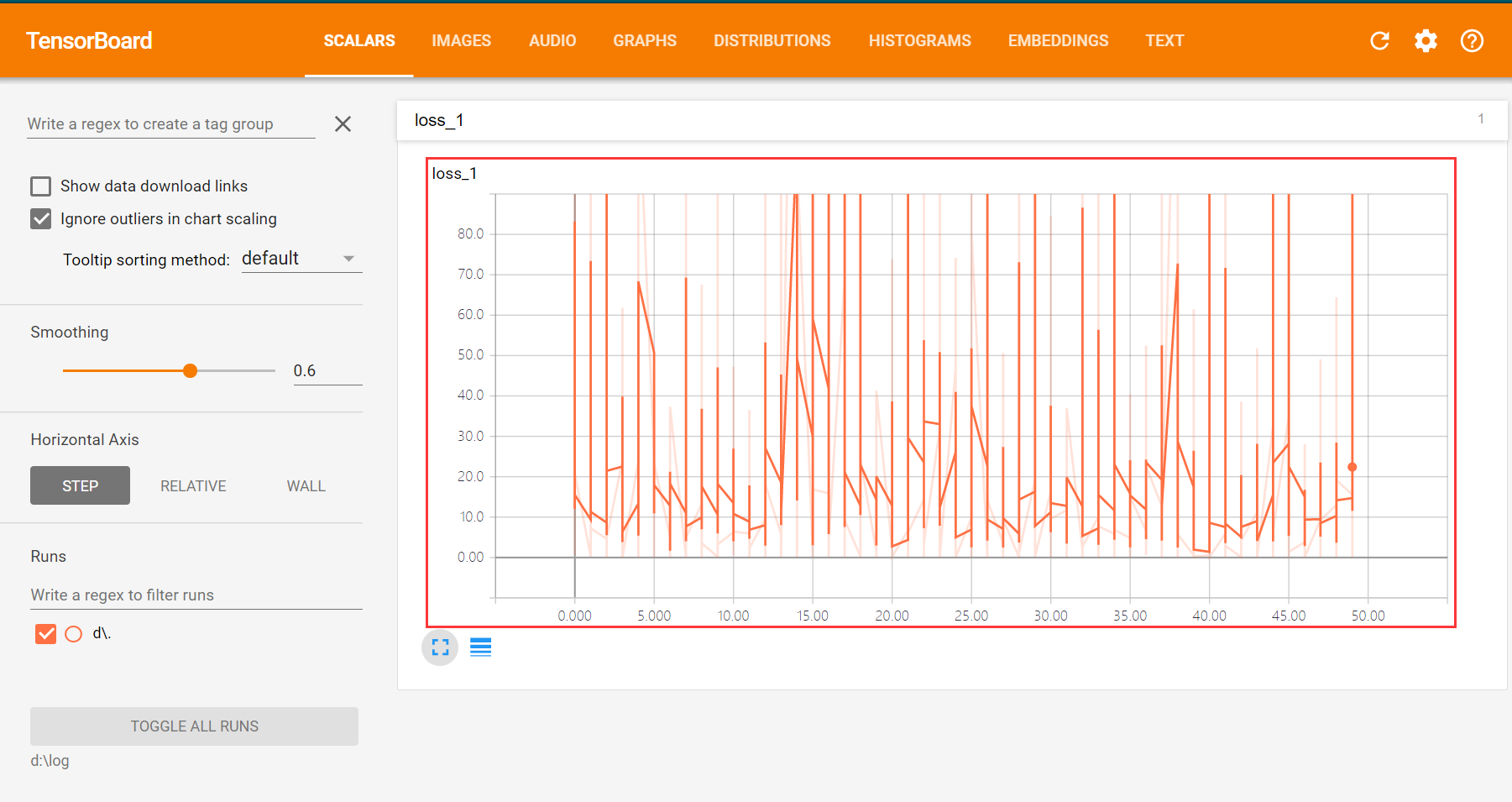
打开TensorBoard: tensorboard --logdir=d:\log8.2.2TensorBoard 查看loss
8.2.3TensorBoard查看计算图














TensorFlow 多元线性回归【波士顿房价】的更多相关文章
- TensorFlow多元线性回归实现
多元线性回归的具体实现 导入需要的所有软件包: 因为各特征的数据范围不同,需要归一化特征数据.为此定义一个归一化函数.另外,这里添加一个额外的固定输入值将权重和偏置结合起来.为此定义函数 appe ...
- Tensorflow之多元线性回归问题(以波士顿房价预测为例)
一.根据波士顿房价信息进行预测,多元线性回归+特征数据归一化 #读取数据 %matplotlib notebook import tensorflow as tf import matplotlib. ...
- TensorFlow从0到1之TensorFlow实现多元线性回归(16)
在 TensorFlow 实现简单线性回归的基础上,可通过在权重和占位符的声明中稍作修改来对相同的数据进行多元线性回归. 在多元线性回归的情况下,由于每个特征具有不同的值范围,归一化变得至关重要.这里 ...
- 【TensorFlow篇】--Tensorflow框架初始,实现机器学习中多元线性回归
一.前述 TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理.Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,T ...
- 利用TensorFlow实现多元线性回归
利用TensorFlow实现多元线性回归,代码如下: # -*- coding:utf-8 -*- import tensorflow as tf import numpy as np from sk ...
- TensorFlow简单线性回归
TensorFlow简单线性回归 将针对波士顿房价数据集的房间数量(RM)采用简单线性回归,目标是预测在最后一列(MEDV)给出的房价. 波士顿房价数据集可从http://lib.stat.cmu.e ...
- machine learning 之 多元线性回归
整理自Andrew Ng的machine learning课程 week2. 目录: 多元线性回归 Multivariates linear regression /MLR Gradient desc ...
- 多元线性回归(Multivariate Linear Regression)简单应用
警告:本文为小白入门学习笔记 数据集: http://openclassroom.stanford.edu/MainFolder/DocumentPage.php?course=DeepLearnin ...
- 斯坦福机器学习视频笔记 Week2 多元线性回归 Linear Regression with Multiple Variables
相比于week1中讨论的单变量的线性回归,多元线性回归更具有一般性,应用范围也更大,更贴近实际. Multiple Features 上面就是接上次的例子,将房价预测问题进行扩充,添加多个特征(fea ...
随机推荐
- androidthreadtest<CODE 2 chaper9>
学习目的:1.了解android线程的使用 2.了解主线程与子线程区别 3.解析异步处理机制主线程与子线程:所谓主线程,在Windows窗体应用程序中一般指UI线程,这个是程序启动的时候首先创建的线程 ...
- 开始使用Github
Gather ye rosebuds while ye may 我自己也是刚开始使用github没几天,写得不好我就写自己常用的吧 2015年9月20日下午3:19更新知乎上这个答案写得好多了
- Random Forest And Extra Trees
随机森林 我们对使用决策树随机取样的集成学习有个形象的名字–随机森林. scikit-learn 中封装的随机森林,在决策树的节点划分上,在随机的特征子集上寻找最优划分特征. import numpy ...
- 在 LaTeX 中实现缩印效果
https://liam.page/ 近日大概重拾了一点对 LaTeX 的兴趣,遇见这样一个问题:如何在 LaTeX 中实现缩印效果(即,将两页或更多页排版在一页纸上),并且实现水印效果的页码? 缩印 ...
- idea激活教程(永久)支持2019 3.1 亲测
此教程已支持最新2019.3版本 本教程适用Windows.Mac.Ubuntu等所有平台. 激活前准备工作 配置文件修改已经不在bin目录下直接修改,而是通过Idea修改 如果输入code一直弹出来 ...
- Arthas 实战,助你解决同名类依赖冲突问题
上篇文章中,小黑哥分析 Maven 依赖冲突分为两类: 项目同一依赖应用,存在多版本,每个版本同一个类,可能存在差异. 项目不同依赖应用,存在包名,类名完全一样的类. 第二种情况,往往是这个场景,本地 ...
- Nacos 数据持久化 mysql8.0
一.问题描述 直接下载的稳定版本nacos编译后的文件,不支持mysql8及其以上版本,按照官网文档:https://nacos.io/zh-cn/docs/deployment.html 执行完成之 ...
- RabbitMQ面试题集锦(精选)(另附思维导图)
1.使用RabbitMQ有什么好处? 1.解耦,系统A在代码中直接调用系统B和系统C的代码,如果将来D系统接入,系统A还需要修改代码,过于麻烦! 2.异步,将消息写入消息队列,非必要的业务逻辑以异步的 ...
- 安装archlinux的另辟蹊径的命令及心得
先说说我为什么开始入坑archlinux的吧,我最喜欢这个系统的一点就是简洁,DIY程度高,可以定制真正属于自己的专用系统.(像gentoo的话,就为了日常使用也没必要那么折腾,除非你是想在折腾的过程 ...
- openwrt 为软件包添加服务
手动修改 rc.local 加入也可以实现自启动,缺点手动修改太麻烦,停止只能用 kill . 配置成服务最方便了,可以启用或禁用,启动,停止,重启非常方便. 在openwrt 中使用服务 servi ...