【并行计算-CUDA开发】GPGPU OpenCL/CUDA 高性能编程的10大注意事项
GPGPU OpenCL/CUDA 高性能编程的10大注意事项
1.展开循环
如果提前知道了循环的次数,可以进行循环展开,这样省去了循环条件的比较次数。但是同时也不能使得kernel代码太大。
循环展开代码例子:

1 #include<iostream>
2 using namespace std;
3
4 int main(){
5 int sum=0;
6 for(int i=1;i<=100;i++){
7 sum+=i;
8 }
9
10 sum=0;
11 for(int i=1;i<=100;i=i+5){
12 sum+=i;
13 sum+=i+1;
14 sum+=i+2;
15 sum+=i+3;
16 sum+=i+4;
17 }
18 return 0;
19 }
2.避免处理非标准化数字
OpenCL中非标准化数字,是指数值小于最小能表示的正常值。由于计算机的位数有限,表示数据的范围和精度都不可能是无限的。(具体可以查看IEEE 754标准,http://zh.wikipedia.org/zh-cn/IEEE_754)
在OpenCL中使用非标准化数字,可能会出现“除0操作”,处理很耗时间。
如果在kernel中“除0”操作影响不大的话,可以在编译选项中加入-cl-denorms-are-zero,如:
clBuildProgram(program, 0, NULL, "-cl-denorms-are-zero", NULL, NULL);
3.通过编译器选项传输常量基本类型数据到kernel,而不是使用private memory
如果程序中需要给kernel 传输常量基本类型数据,最好是使用编译器选项,比如宏定义。而不是,每个work-item都定义一个private memory变量。这样编译器在编译时,会直接进行变量替换,不会定义新的变量,节省空间。
如下面代码所示(Dmacro.cpp):
1 #include<stdio.h>
2 int main()
3 {
4 int a=SIZE;
5 printf("a=%d, SIZE=%d\n",a,SIZE);
6 return 0;
7 }
编译:
g++ -DSIZE=128 -o A Dmacro.cpp
4.如果共享不重要的话,保存一部分变量在private memory而不是local memory
work-item访问private memory速度快于local memory,因此可以把一部分变量数据保存在private memory中。当然,当private memory容量满时,GPU硬件会自动将数据转存到local memory中。
5.访问local memory应避免bank conflicts
local memory被组织为一个一个的只能被单独访问的bank,bank之间交叉存储数据,以便连续的32bit被保存在连续的bank中。如下图所示:
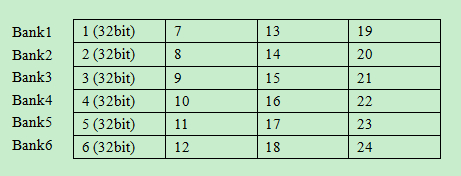
(1)如果多个work-item访问连续的local memory数据,他们就能最大限度的实现并行读写。
(2)如果多个work-item访问同一个bank中的数据,他们就必须顺序执行,严重降低数据读取的并行性。因此,要合理安排数据在local memory中的布局。
(3)特殊情况,如果一个wave/warp中的线程同时读取一个local memory中的一个地址,这时将进行广播,不属于bank 冲突。
6.避免使用”%“操作
"%"操作在GPU或者其他OpenCL设备上需要大量的处理时间,如果可能的话尽量避免使用模操作。
7.kernel中重用(Reuse) private memory,为同一变量定义不同的宏
如果kernel中有两个或者以上的private variable在代码中使用(比如一个在代码段A,一个在代码段B中),但是他们可以被数值相同。
也就是当一个变量用作不同的目的时,为了避免代码中的命名困惑,可以使用宏。在一个变量上定义不同的宏。
如下面代码所示:
1 #include<stdio.h>
2 int main(){
3 int i=4;
4 #define EXP i
5 printf("EXP=%d\n",EXP);
6
7 #define COUNT i
8 printf("COUNT=%d\n",COUNT);
9 getchar();
10 return 0;
11 }
8.对于(a*b+c)操作,尽量使用 fma function
如果定义了“FP_FAST_FMAF”宏,就可以使用函数fma(a,b,c)精确的计算a*b+c。函数fma(a,b,c)的执行时间小于或等于计算a*b+c。
9.在program file 文件中对非kernel的函数使用inline
inline修饰符告诉编译器在调用inline函数的地方,使用函数体替换函数调用。虽然会使得编译后的代码占用memory增加,但是省去了函数调用时上下、函数调用栈的切换操作,节省时间。
10.避免分支预测惩罚,应该尽量使得条件判断为真的可能性大
现代处理器一般都会进行“分支预测”,以便更好的提前“预取”下一条要执行的指令,使得“取指令、译码分析、执行、保存”尽可能的并行。
在“分支预测”出错时,提前取到的指令,不是要执行的指令,就需要根据跳转指令,进行重新取指令,就是“分支预测惩罚”。
看如下的代码:
1 #include<stdio.h>
2 int main()
3 {
4 int i=1;
5 int b=0;
6 if(i == 1)
7 b=1;
8 else
9 b=0;
10 return 1;
11 }
对应的汇编代码:
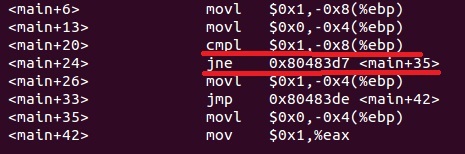
(movl 赋值,cmpl 比较,jne 不等于跳转,jmp 无条件跳转)
从上面的汇编指令代码看出,如果比较(<main+24>)结果相等,则执行<main+26>也就是比较指令的下一条指令,对应b=1顺序执行;如果比较(<main+24>)结果不相等,则执行跳转到<main+35>,不是顺序执行。
当然,有的处理器可能会根据以往“顺序执行”与“跳转执行”的比例来进行分支预测,但是这也是需要积累的过程。况且并不是,每个处理器多能这样只能。
本文:http://www.cnblogs.com/xudong-bupt/p/3630952.html
最后,上面的10个tips,能过提升kernel函数的性能,但是你应该进行具体的性能分析知道程序中最耗时的地方在哪里。当然了,只有通过实验才能真正学会OpenCL高性能编程。
【并行计算-CUDA开发】GPGPU OpenCL/CUDA 高性能编程的10大注意事项的更多相关文章
- GPGPU OpenCL/CUDA 高性能编程的10大注意事项
转载自:http://hc.csdn.net/contents/content_details?type=1&id=341 1.展开循环 如果提前知道了循环的次数,可以进行循环展开,这样省去了 ...
- 【并行计算-CUDA开发】OpenCL、OpenGL和DirectX三者的区别
什么是OpenCL? OpenCL全称Open Computing Language,是第一个面向异构系统通用目的并行编程的开放式.免费标准,也是一个统一的编程环境,便于软件开发人员为高性能计算服务器 ...
- 【并行计算-CUDA开发】有关CUDA当中global memory如何实现合并访问跟内存对齐相关的问题
ps:这是英伟达二面面的一道相关CUDA的题目.<NVIDIA CUDA编程指南>第57页开始 在合并访问这里,不要跟shared memory的bank conflic ...
- 【CUDA开发】论CUDA和LAV解码器是否真的实用
先说配置,我电脑E3V3+GTX780TI视频就一个普通的720P AVC1编码MP4视频,实时检测软件是CPU-Z和GPU-Z,AIDA64[全默认设置]全部用ptoplayer默认播放时候,播放3 ...
- 【并行计算-CUDA开发】从零开始学习OpenCL开发(一)架构
多谢大家关注 转载本文请注明:http://blog.csdn.net/leonwei/article/details/8880012 本文将作为我<从零开始做OpenCL开发>系列文章的 ...
- 【并行计算-CUDA开发】CUDA编程——GPU架构,由sp,sm,thread,block,grid,warp说起
掌握部分硬件知识,有助于程序员编写更好的CUDA程序,提升CUDA程序性能,本文目的是理清sp,sm,thread,block,grid,warp之间的关系.由于作者能力有限,难免有疏漏,恳请读者批评 ...
- 【并行计算-CUDA开发】GPU并行编程方法
转载自:http://blog.sina.com.cn/s/blog_a43b3cf2010157ph.html 编写利用GPU加速的并行程序有多种方法,归纳起来有三种: 1. 利用现有的G ...
- 【并行计算-CUDA开发】FPGA 设计者应该学习 OpenCL及爱上OpenCL的十个理由
为什么要学习OpenCL呢?就目前我所从事的医疗超声领域,超声前端的信号处理器一般是通过FPGA或FPGA+DSP来设计的,高端设备用的是FPGA+ GPU架构.传统的设计方法是通过HDL语言来进行设 ...
- 【并行计算与CUDA开发】英伟达硬件加速编解码
硬件加速 并行计算 OpenCL OpenCL API VS SDK 英伟达硬件编解码方案 基于 OpenCL 的 API 自己写一个编解码器 使用 SDK 中的编解码接口 使用编码器对于 OpenC ...
随机推荐
- HDU 6061 - RXD and functions | 2017 Multi-University Training Contest 3
每次NTT都忘记初始化,真的是写一个小时,Debug两个小时- - /* HDU 6061 - RXD and functions [ NTT ] | 2017 Multi-University Tr ...
- LDA的参数确定和主题数确定方法
主题数确定:困惑度计算,画出曲线,选择拐点,避免信息丢失和主题冗余 https://blog.csdn.net/u014449866/article/details/80218054 参数调节: 方法 ...
- PHP mysqli_next_result() 函数
定义和用法 mysqli_next_result() 函数为 mysqli_multi_query() 准备下一个结果集. 语法 mysqli_next_result(connection); 执 ...
- bbs--点赞
bbs---点赞 需求分析 页面展示 1 点赞 和 踩灭 按钮展示 1 用户未登录,不处理点赞踩灭,给用户提供登录接口 2 登录 1 第一次点点赞/踩灭 1 点赞成功 数据+1 提示点赞成功 ...
- NotFoundError (see above for traceback): Key local3/weights not found in checkpoint
解决办法 原文 https://www.jianshu.com/p/2de8e01af88d with tf.Session() as sess: tf.get_variable_scope().re ...
- 初学c++动态联编
先看一下什么是C++联编? 我觉得通俗的讲,用对象来访问类的成员函数就是静态联编. 那什么是动态联编: 一般是通过虚函数实现动态联编. 看一个动态联编的例子: 我比较懒,所以直接粘贴了MOOC视频的图 ...
- Android学习——MediaProvider与Music模块
一.MediaProvider数据库介绍 1. 关系型数据库 关系模型的物理表示是一个二维表格,由行和列组成. 2. MediaProvider数据库存储位置 /data/data/com.a ...
- JAVA之G1与CMS垃圾回收
G1 GC,全称Garbage-FirstGarbage Collector,通过-XX:+UseG1GC参数来启用,作为体验版随着JDK 6u14版本面世,在JDK 7u4版本发行时被正式推出,相信 ...
- Nginx之核心结构体ngx_cycle_t
1. ngx_listening_t 结构体 ngx_cycle_t 对象中有一个动态数组成员叫做 listening,它的每个数组元素都是 ngx_listening_t 结构体,而每个 ngx_l ...
- Ubuntu18.04 server安装步骤
Ubuntu18.04 server安装步骤 1. select a language default 2. select your location default 3. configure th ...