hive on tez 错误记录
1、执行过程失败,报 Container killed on request. Exit code is 143
如下图:


分析:造成这种原因是由于总内存不多,而容器在jvm中占比过高,修改tez-site.xml文件,添加如下配置:
<property>
<name>tez.container.max.java.heap.fraction</name>
<value>0.2</value> #调低内存占比,默认是0.8(也就是80%)
</property>
2、ERROR [main] exec.TaskRunner: Error in executeTask java.lang.NoSuchFieldError: DEFAULT_MR_AM_ADMIN_USER_ENV
分析:
- hadoop版本与tez所带的hadoop版本不一致。
- 没有配置tez的类路径或者配置失效。
解决:
- 第一种情况,删除tez的lib目录下的hadoop包,然后拷贝hadoop lib下的hadoop包过去。(参考上篇hive on tez)
- 第二种情况,在hadoop-env.sh配置环境变量 或者拷贝tez目录或者tez的lib目录下的.jar包到hive下的lib目录。
1、hadoop-env.sh配置环境变量
TEZ_CONF_DIR=/data1/hadoop/hadoop/etc/hadoop/
TEZ_JARS=/tez-0.9.
export HADOOP_CLASSPATH=${HADOOP_CLASSPATH}:${TEZ_CONF_DIR}:${TEZ_JARS}/*:${TEZ_JARS}/lib/*
或者
2、拷贝jar文件到hive
#cp /tez-0.9.0/*.jar /data1/hadoop/hive/lib
#cp /tez-0.9.0/lib/*.jar /data1/hadoop/hive/lib
3、FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.tez.TezTask
hive设置值有三种方法:
方法1:在hive-site.xml文件设置,如:
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
方法2:在启动的时候传递值进去,如:
#hive --hiveconf hive.execution.engine=tez
方法3:进入到hive-cli,通过set 设置,如:
hive> set hiveconf hive.execution.engine=tez; 优先级:方法3>>
范围:
方法1:全局生效
方法2、:当前环境生效。
现在按方法1或者方法2配置hive.execution.engine=tez,进去到hive-cli时启动调试模式:如下:
首先。在配置文件开启tez引擎:
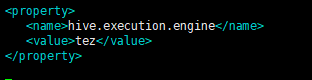
其次,启动的时候,打开调试模式,看具体错误的信息:
hive --hiveconf hive.root.logger=DEBUG,console
输出信息如下:
// :: [Tez session start thread]: INFO client.TezClient: Tez system stage directory hdfs://EDPI-HBASE/tmp/hive/root/_tez_session_dir/c6ba83f1-cd59-4a53-b9b9-38aff39ff6d9/.tez/application_1560912101665_0001 doesn't exist and is created
// :: [Tez session start thread]: DEBUG client.TezClientUtils: AppMaster capability = <memory:, vCores:>
hive> // :: [Tez session start thread]: DEBUG client.TezClientUtils: Command to launch container for ApplicationMaster is : $JAVA_HOME/bin/java -Xmx204m -Djava.io.tmpdir=$PWD/tmp -server -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -XX:+PrintGCDetails -verbose:gc -XX:+PrintGCTimeStamps -XX:+UseNUMA -XX:+UseParallelGC -Dlog4j.configuratorClass=org.apache.tez.common.TezLog4jConfigurator -Dlog4j.configuration=tez-container-log4j.properties -Dyarn.app.container.log.dir=<LOG_DIR> -Dtez.root.logger=INFO,CLA -Dsun.nio.ch.bugLevel='' org.apache.tez.dag.app.DAGAppMaster --session ><LOG_DIR>/stdout ><LOG_DIR>/stderr
// :: [Tez session start thread]: ERROR tez.TezSessionState: Failed to start Tez session
java.lang.NullPointerException #报空指针错误
at org.apache.tez.dag.api.records.DAGProtos$PlanKeyValuePair$Builder.setValue(DAGProtos.java:)
at org.apache.tez.client.TezClientUtils.createFinalConfProtoForApp(TezClientUtils.java:)
at org.apache.tez.client.TezClientUtils.createApplicationSubmissionContext(TezClientUtils.java:)
at org.apache.tez.client.TezClient.start(TezClient.java:)
at org.apache.hadoop.hive.ql.exec.tez.TezSessionState.startSessionAndContainers(TezSessionState.java:)
at org.apache.hadoop.hive.ql.exec.tez.TezSessionState.access$(TezSessionState.java:)
at org.apache.hadoop.hive.ql.exec.tez.TezSessionState$.call(TezSessionState.java:)
at org.apache.hadoop.hive.ql.exec.tez.TezSessionState$.call(TezSessionState.java:)
at java.util.concurrent.FutureTask.run(FutureTask.java:)
at java.lang.Thread.run(Thread.java:)
分析:为什么会报空指针错误呢,,,经过测试,如果不在hive-site.xml配置文件配置引擎,进入到hive-cli里面以后,通过set方法设置,在执行hive语句的时候,没问题,可以正常执行(其实,通过方法3这种方式在执行hql语句的时候,在第一次执行时也会提示空指针错误,后面在执行的时候才算正常。),但是通过方法1和2设置,不能正常执行,报:
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.tez.TezTask
实际上也就是空指针错误。
通过方法1和2设置引擎的时候,在进入hive客户端时,yarn就会分配资源启动AM,而通过方法3的时候,则是进入到hive以后,在执行具体的任务时,才开始分配资源启动AM
解决办法:
修改yarn-site.xml文件
找到如下的配置
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:,slave1:,slave2:</value>
</property>
修改成
<property>
<name>hadoop.zk.address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
分发yarn-site.xml到其他机器,重启yarn
经过测试,修改以后,三种方法设置引擎为tez后都可以正常的在hive里面使用hql。
造成这种原因的我感觉应该是由于yarn.resourcemanager.zk-address参数已经过时,现在在配置的时候,都采用hadoop.zk.address配置zookeeper的地址。
所以,出错的时候,打开调试模式还是很有帮助的。
hive on tez 错误记录的更多相关文章
- hive启动一些错误记录
java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMeta ...
- hive on tez配置
1.Tez简介 Tez是Hontonworks开源的支持DAG作业的计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升MapReduce作业的性能.Tez并不直接面向最终用户--事实上它允许 ...
- hive on spark VS SparkSQL VS hive on tez
http://blog.csdn.net/wtq1993/article/details/52435563 http://blog.csdn.net/yeruby/article/details/51 ...
- uploadify插件Http Error(302)错误记录(MVC)
由于项目(asp.net MVC)需要做一个附件上传的功能,使用的是jQuery的Uploadify插件的2.1.0版本,上传文件到自己项目指定的文件夹下面.做完之后,在谷歌上测试是正确的,在火狐上报 ...
- 开发错误记录8:Unable to instantiate application com
开发错误记录8:Unable to instantiate application com.android.tools.fd.runtime.BootstrapApplication 这是因为在And ...
- PHP 错误与异常 笔记与总结(5)配置文件中与错误日志相关的选项 && 将错误记录到指定的文件中
[记录错误(生产环境)] php.ini: ① 开启 / 关闭 错误日志功能 log_errors = On ② 设置 log_errors 的最大字节数 log_errors_max_len = 其 ...
- 安装nagios出现的两个错误记录
最近在安装nagios,出现几个错误记录: 一 检查nagios配置的时候出现错误如下: Warning: Duplicate definition found for host 'kelly' (c ...
- [置顶] 利用Global.asax的Application_Error实现错误记录,错误日志
利用Global.asax的Application_Error实现错误记录 错误日志 void Application_Error(object sender, EventArgs e) { // 在 ...
- streamsets 错误记录处理
我们可以在stage 级别,或者piepline 级别进行error 处理配置 pipeline的错误记录处理 discard(丢踢) send response to Origin pipeline ...
随机推荐
- 【转载】C#指定文件夹下面的所有内容复制到目标文件夹下面
在涉及到文件夹操作的过程中,有时候需要将文件夹下的所有内容复制拷贝到另一个文件夹,在C#的开发中有时候会遇到这个功能需求将指定文件夹下所有的内容复制到另一个文件夹,这个过程需要遍历所有的文件和目录.此 ...
- 【转载】2018年最值得期待的5大BPM厂商
部署BPM软件可以帮助企业获得竞争优势,通过分析.设计.执行.控制和调节业务流程协助企业领导者提高组织绩效. 业务流程管理(BPM)是指随着公司和组织的发展匹配业务目标和流程的行为.部署BPM软件可以 ...
- Python:Shapefile矢量转化为GeoJSON格式
在最近的项目中,完成了许多python处理矢量数据的算法程序,比如缓冲区分析.叠置分析.统计分析等,主要用到的是GDAL/OGR库,很多功能都参照了此链接中的示例:http://pcjericks.g ...
- HTML5 使用localstorage 本地存储
HTML 本地存储介绍 最早的 Cookies 自然是大家都知道,问题主要就是太小,大概也就 4KB 的样子,而且 IE6 只支持每个域名20个cookies,太少了.优势就是大家都支持,而且支持得还 ...
- MySql 学习之 一条更新sql的执行过程
上一篇文章咱们说了一条查询sql的执行过程.如果没有看过上一篇文章的可以去看下上一篇文章,今天咱们说说一条更新sql的执行过程. 上面一条sql是将id为1的分数加上10. 那么它的执行流程是怎样的呢 ...
- JAVA 多线程(一)
进程和线程 进程:是一个正在执行中的程序.每一个进程执行都有一个执行顺序,该执行顺序是一个执行路径,或者叫一个控制单元. 线程:就是进程中的一个独立的控制单元. 线程在控制着进程的执行. 在计算机中多 ...
- Scyther Advanced Topics
建立非对称秘钥对 声明一个公钥函数和一个私钥函数: const pk2: Function ; const sk2: Function : 我们还声明这些函数代表非对称密钥对: inversekeys ...
- <<构建之法>>--第二次作业
GIT地址 https://github.com/Panghu98/AchaoCalculator.git GIT用户名 Panghu98 学号后五位 62632 博客地址 https://www.c ...
- Selenium(十五)cookie
有时候我们需要验证浏览器中是否存在某个 cookie,因为基于真实的 cookie 的测试是无法通过集成测试完成的.WebDriver 提供了操作 Cookie 的相关方法可以读取.添加和删除 coo ...
- Robot Framework--接口实例一
需求:api/car/detail/recommendcar.json 接口返回的车辆数量少于等于20且车辆不能重复 分析:统计接口中返回的列表的长度,再把carid拿出来组成一个新的列表,判断这 ...