#论文阅读# Universial language model fine-tuing for text classification

论文链接:https://aclweb.org/anthology/P18-1031
对文章内容的总结
文章研究了一些在general corous上pretrain LM,然后把得到的model transfer到text classiffication上 整个过程的训练技巧。这些技巧的切入点是learning rate. 主要是三个:(1)discriminative fine-tuning (其中的discriminative 指 fine-tune each layer with different learning rate LR)(2)slanted triangular learning rate (在训练过程中先增加LR,增到预设的最大值后减小(减小速度<增加速度,所以LR随训练步数的曲线看起来是slanted triangle))(3)在训练text classiffication model时, perform gradual unfreezing. (即先锁住所有层的参数,训练过程中从最后一层开始,每训练一个epoch向前放开一层)
以下是ABSTACT和INTRODUCTION主要内容的翻译:
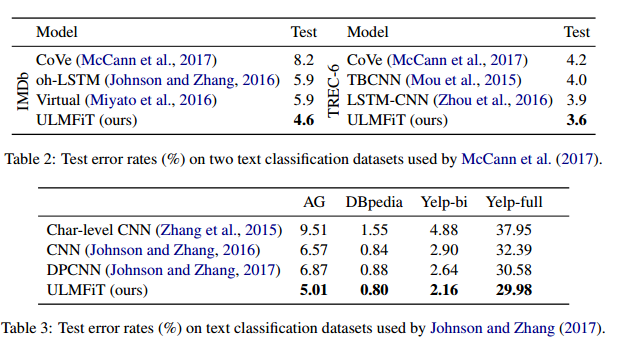

Contributions:
#论文阅读# Universial language model fine-tuing for text classification的更多相关文章
- 论文笔记 - Noisy Channel Language Model Prompting for Few-Shot Text Classification
Direct && Noise Channel 进一步把语言模型推理的模式分为了: 直推模式(Direct): 噪声通道模式(Noise channel). 直观来看: Direct ...
- 论文列表——text classification
https://blog.csdn.net/BitCs_zt/article/details/82938086 列出自己阅读的text classification论文的列表,以后有时间再整理相应的笔 ...
- 论文分享|《Universal Language Model Fine-tuning for Text Classificatio》
https://www.sohu.com/a/233269391_395209 本周我们要分享的论文是<Universal Language Model Fine-tuning for Text ...
- 【论文翻译】KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Grained Relationships
KLMo:建模细粒度关系的知识图增强预训练语言模型 (KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Graine ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- NLP问题特征表达基础 - 语言模型(Language Model)发展演化历程讨论
1. NLP问题简介 0x1:NLP问题都包括哪些内涵 人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据.那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发 ...
- YOLO 论文阅读
YOLO(You Only Look Once)是一个流行的目标检测方法,和Faster RCNN等state of the art方法比起来,主打检测速度快.截止到目前为止(2017年2月初),YO ...
- BERT 论文阅读笔记
BERT 论文阅读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 由 @快刀切草莓君 ...
随机推荐
- 【题解】[Nwerc 2006]escape -C++
Description 给出数字N(1<=N<=10000),X(1<=x<=1000),Y(1<=Y<=1000),代表有N个敌人分布一个X行Y列的矩阵上 矩形的 ...
- MySQL 热快问题解决
原文地址:http://blog.itpub.net/22664653/viewspace-1269948 一 背景 某个业务线 商品开放开用户申请免费试用,当某个商品特别吸引人时,比如iPhone ...
- decompiler
.NET Reflector trial version http://www.red-gate.com/products/dotnet-development/reflector/ 破解版本 .N ...
- shiro认证-SSM
shiro认证-SSM pom <dependency> <groupId>org.apache.shiro</groupId> <artifactId> ...
- 1656:Combination
一本通1656:Combination 1656:Combination 时间限制: 1000 ms 内存限制: 524288 KB提交数: 89 通过数: 49 [题目描述] ...
- CentOS6.8安装Docker
在CentOS6.8上安装Docker 1.Docker使用EPEL发布,RHEL系的OS首先要确保已经持有EPEL仓库,否则先检查OS的版本,然后安装相应的EOEL包:如下命令: yum insta ...
- expdp / impdp 用法详解 ,和exp / imp 的区别
一 关于expdp和impdp 使用EXPDP和IMPDP时应该注意的事项:EXP和IMP是客户端工具程序,它们既可以在客户端使用,也可以在服务端使用.EXPDP和IMPDP是服务端的工具程 ...
- Pwnhub Fantastic Key-一点总结
index.php <? php error_reporting(0); include 'config.php'; $id = $_POST['i'] ? waf($_POST['i']) : ...
- windows工程总结
1.win32控制台console程序 运行在MS-DOS环境中的程序.控制台应用程序通常没有可视化的界面,只是通过字符串来显示或者监控程序.控制台程序常常被应用在测试.监控等用途,用户往往只关心数据 ...
- dd 命令
dd:用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换. 注意:指定数字的地方若以下列字符结尾,则乘以相应的数字:b=512:c=1:k=1024:w=2 参数注释: if=文件名:输入文件名 ...