Spark内核源码解析
1.spark内核架构常用术语
Application:基于spark程序,包含一个driver program(客户端程序)和多个executeor(线程)
Driver Progrom:代表着sparkcontext
executeor:某个Application运行在worker node上的一个进程,该进程负责运行Task,并且将数据存储到内存或者磁盘上,每个Application都有各自独立的executeor。
worker node:集群中任何可以运行Application代码的节点。
Task:被传送到某个executeor的工作单元。
Cluster Manager:在集群上获取外部服务(例如:Standalone\Year\Mesos)
job:包含多个Task组成的并行计算,往往有spark的action催生
stage:每个job会被拆分很多组task任务,每组任务被称为stage,也称为TaskSet
RDD:Spark的基本计算单元,可以通过一系列算子进行操作(主要有Transformation和Action)
DAG Scheduler:根据job构建基于Stage的DAG,并提交Stage给Task Scheduler
Task Scheduler:将Taskset提交给worker(集群)运行并回报结果
2.创建SparkContext
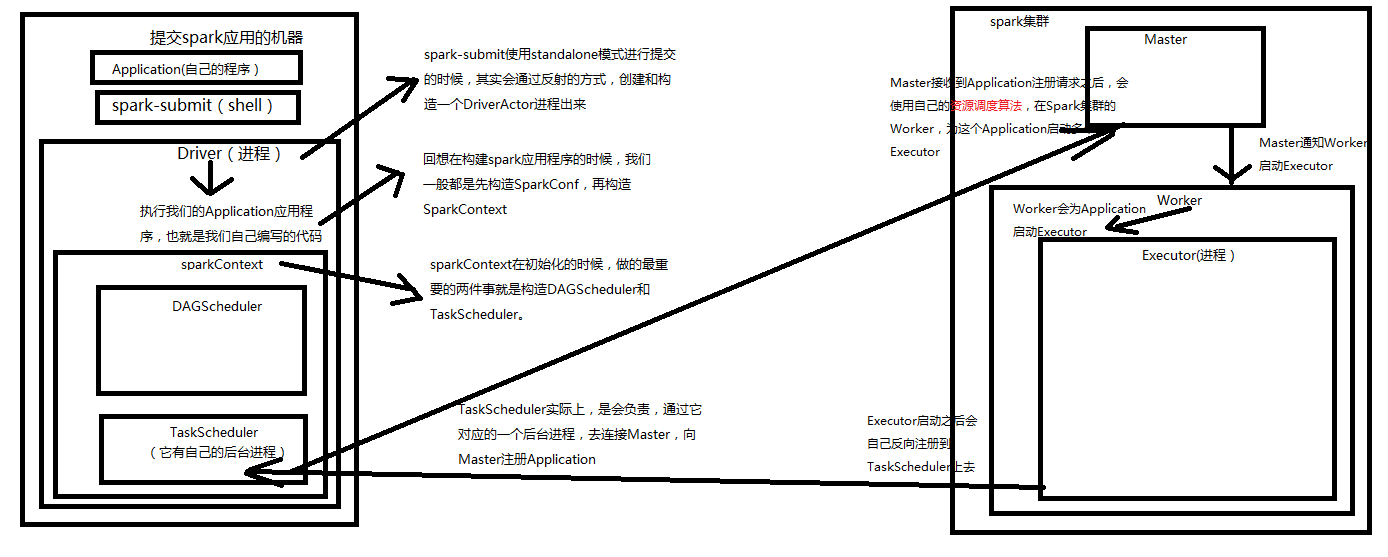
1.1 在shell下,spark-submit使用standalone模式提交的时候,其实会通过反射的方式,创建和构造一个Driveractor(和java的actor进程差不多)
1.2 Driver进程在执行我们提交的Application代码的时候,会先构建SparkConf,再构建SparkContext.
1.3 SparkContext在初始化的时候,做的最重要的事情,就是构造DAG Scheduler和Task Scheduler
1.4 TaskScheduler实际上,是会负责与它对应的一个后台进程,去连接Spark集群的Master并注册Application
1.5 Master接收到Application的注册请求后,会使用自己的资源调度算法(基于调度器standalone、Yarn、Mesos等都有不同的调度算法),在Spark集群的Worker上会为i这个Application启动Executor
1.6 Master通知Worker启动Executor后,Worker会为Application启动Executor进程
1.7 Executer启动后,首先做的就是会将自己反向注册给Task Scheduler上去,到此为止SparkContext完成了初始化
3.运行Application
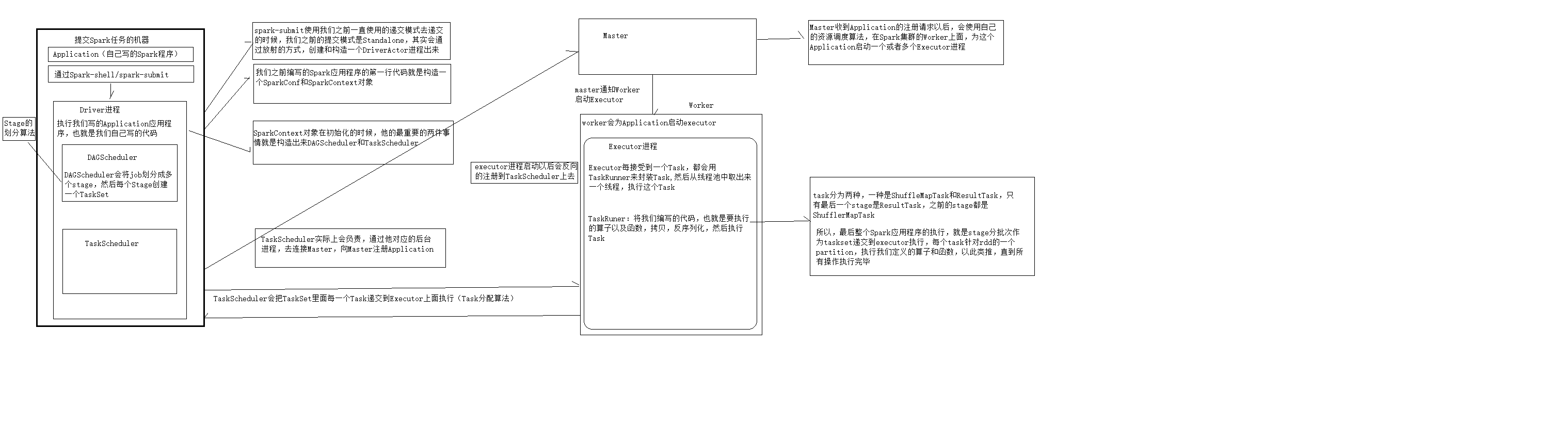
2.1 所有的Executer都会反向注册给Driver programe,Driver Programe当结束SparkContextc初始化后,会继续只想我们编写的代码哦
2.2 每执行一个Action就会创建一个job,job会提交给DAG Scheduler
2.3 DAG Scheduler会采用自己的stage划分算法将job划分为多个stage,然后每个stage会创建一个TaskSet
2.4 DAG Scheduler会将TaskSet传递给Task Scheduler,Task Scheduler会把TaskSet里的每一个Task提交到Worker上的Executer上执行
2.5 Executor每接收一个task都会用TaskRunner来封装task,然后从线程池里面取出一个线程,执行这个task,TaskRunner将我们编写的代码,也就是要执行的算子以及函数,拷贝,反序列化,然后执行Task。
2.6 Task有两种,ShuffleMapTsk和ResultTask。只有最后一个stage是ResultTask,之前的stage,都是ShuffleMapTask.
2.7所以,最后整个应用程序的执行,就是将stage分批次作为taskSet提交给executeor执行,每个task针对RDD的一个partition,执行我们定义的算子和函数,为此类推,知道所有的操作完成为止。
Spark内核源码解析的更多相关文章
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- Spark SQL源码解析(三)Analysis阶段分析
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Analysis阶段概述 首先 ...
- Spark SQL源码解析(四)Optimization和Physical Planning阶段解析
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Spark SQL源码解析(三 ...
- Spark SQL源码解析(五)SparkPlan准备和执行阶段
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Spark SQL源码解析(三 ...
- Spark SQL源码解析(二)Antlr4解析Sql并生成树
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 这一次要开始真正介绍Spark解析SQL的流程,首先是从Sql Parse阶段开始,简单点说, ...
- Spark Streaming运行流程及源码解析(一)
本系列主要描述Spark Streaming的运行流程,然后对每个流程的源码分别进行解析 之前总听同事说Spark源码有多么棒,咱也不知道,就是疯狂点头.今天也来撸一下Spark源码. 对Spark的 ...
- [源码解析] 深度学习分布式训练框架 horovod (8) --- on spark
[源码解析] 深度学习分布式训练框架 horovod (8) --- on spark 目录 [源码解析] 深度学习分布式训练框架 horovod (8) --- on spark 0x00 摘要 0 ...
- [源码解析] 深度学习分布式训练框架 horovod (9) --- 启动 on spark
[源码解析] 深度学习分布式训练框架 horovod (9) --- 启动 on spark 目录 [源码解析] 深度学习分布式训练框架 horovod (9) --- 启动 on spark 0x0 ...
- [源码解析] 深度学习分布式训练框架 horovod (10) --- run on spark
[源码解析] 深度学习分布式训练框架 horovod (10) --- run on spark 目录 [源码解析] 深度学习分布式训练框架 horovod (10) --- run on spark ...
随机推荐
- TCP_Wrappers访问控制
一.TCP_Wrappers简介 对有状态连接的特定服务进行安全检测并实现访问控制,它以库文件形式实现,某进程是否接受libwrap的控制取决于发起此进程的程序在编译时是否针对libwrap进行编译的 ...
- poj3691 DNA repair[DP+AC自动机]
$给定 n 个模式串,和一个长度为 m 的原串 s,求至少修改原串中的几个字符可以使得原串中不包含任一个模式串.模式串总长度 ≤ 1000,m ≤ 1000.$ 先建出模式串的AC自动机,然后考虑怎么 ...
- .NET界面开发神器:DevExpress全新发布v19.1.7!快来试用
DevExpress Universal Subscription(又名DevExpress宇宙版或DXperience Universal Suite)是全球使用广泛的.NET用户界面控件套包,De ...
- 08-sp_who2和inputbuffer的使用,连接数
一.sp_who2的使用 1.存储过程的位置 sp_who官方解释地址:https://docs.microsoft.com/zh-cn/sql/relational-databases/system ...
- 配置Multipath多路径环境
iscsi服务器 eth0:192.168.4.5/24 eth1:192.168.2.5/24 iscsi客户端 eth0:192.168.4.100/24 eth3:201 ...
- yolov3 in PyTorch
https://github.com/ultralytics/yolov3 Introduction简介 This directory contains PyTorch YOLOv3 software ...
- vue 钩子函数的使用
1.什么是自定义指令,有哪些钩子函数及自定义指令的使用场景 ①自定义指令是什么?以及自定义指令的使用场景 在Vue中,有很多内置指令,但是这些指令只能满足我们最基础的使用,当我们在实际项目中遇到了必须 ...
- 2015ACM/ICPC亚洲区沈阳站 部分题解
链接在这:http://bak.vjudge.net/contest/132442#overview. A题,给出a,b和n,初始的集合中有a和b,每次都可以从集合中选择不同的两个,相加或者相减,得到 ...
- HTTP服务器(1)
import socket def service_client(new_socket): """为这个客户端返回数据""" # 1. 接收 ...
- flask第三篇 request
每个框架中都有处理请求的机制(request),但是每个框架的处理方式和机制是不同的 为了了解Flask的request中都有什么东西,首先我们要写一个前后端的交互 基于HTML + Flask 写一 ...