python解析库之 XPath
1. XPath (XML Path Language) XML路径语言
2. XPath 常用规则:
nodename 选取此节点的所有子节点
/ 从当前结点选取直接子节点
// 从当前结点选取子孙节点
. 选取当前结点
.. 选取当前结点的父节点
@ 选取属性
3. 实例
from lxml import etree text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text) # 初始化,构造XPath对象
# 自动修正html代码,最后一个<li>没有闭合,tostring()方法补全html代码,返回结果是bytes类型
result = etree.tostring(html)
print(result.decode('utf-8'))
也可以读取文件来进行解析
from lxml import etree html = etree.parse(r'C:\Users\Administrator\Desktop\test.txt', etree.HTMLParser())
result = etree.tostring(html)
print(result.decode('utf-8'))
4. 使用//开头的XPath规则来选取符合要求的节点
from lxml import etree text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">爱我中华</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
'''匹配节点'''
html = etree.HTML(text)
result1 = html.xpath('//*') # 使用*匹配所有节点
print(result1)
result2 = html.xpath('//li') # 获取所有的li节点
print(result2)
print(result2[0])
result3 = html.xpath('//li/a') # 获取所有li节点的直接a子节点
print(result3) # 首先选中href属性为link3.html的a节点,然后再获取其父亲节点,在获取其class属性的值
# result4 为['item-inactive'],这是个只有一个元素的列表
result4 = html.xpath('//a[@href="link3.html"]/../@class')
print(result4[0])
# 同时, 也可以通过parent::来获取父亲节点 如:
result5 = html.xpath('//a[@href="link3.html"]/parent::*/@class') '''属性匹配 (选取节点时,可以用@符号进行属性过滤)'''
# 匹配属性class="item-inactive"的li节点
result6 = html.xpath('//li[@class="item-inactive"]')
print(result6) '''文本获取 (使用XPath中的text()方法获取节点中的文本)'''
result7 = html.xpath('//li[@class="item-inactive"]/a[@href="link3.html"]/text()')
print(result7) # 打印出 ['爱我中华'] 列表 '''属性获取 使用@来获取属性'''
# 匹配属性href="link3.html"的a节点的父亲节点的class属性
result8 = html.xpath('//a[@href="link3.html"]/../@class')
print(result8) # 打印['item-inactive'] '''属性多值匹配'''
html_test = '''<li class="li item-inactive"><a href="link3.html">爱我中华</a></li>'''
# 这里li标签class属性有两个值, 如果按照上边的属性匹配 是匹配不到的,就要用到contains()函数
html_test = etree.HTML(html_test)
# 通过contains方法,第一个参数穿属性名,第二个传属性值中的任意一个,都可以匹配到
result9 = html_test.xpath('//li[contains(@class, "li")]/a/text()')
print(result9) '''多属性匹配 (根据多个属性来确定一个节点)'''
html_test2 = '''<li class="li item-inactive" name="item"><a href="link3.html">Hello World</a></li>'''
# 这里li标签class属性有两个值, 如果按照上边的属性匹配 是匹配不到的,就要用到contains()函数
html_test = etree.HTML(html_test2)
# 通过contains方法,第一个参数穿属性名,第二个传属性值中的任意一个,都可以匹配到
result10 = html_test.xpath('//li[contains(@class, li) and @name="item"]/a[@href="link3.html"]/text()')
print(result10) # 打印['Hello World']
5. XPath 运算符
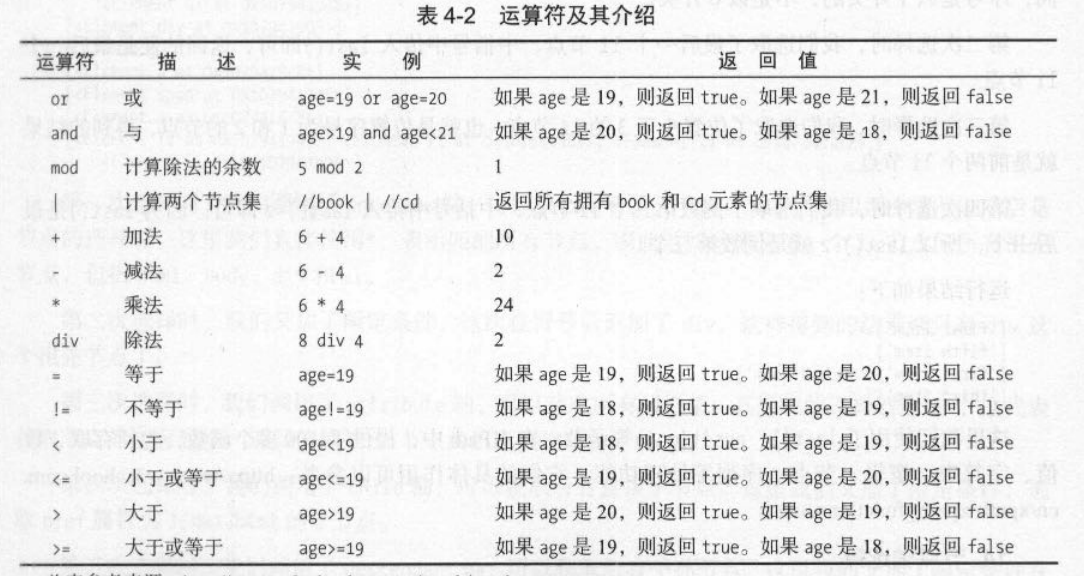
5. 按序选择 (同时匹配了多个节点时但又只想要其中一个节点时)
from lxml import etree text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">爱我中华</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
'''匹配节点后按序选择'''
html = etree.HTML(text)
result1 = html.xpath('//li[1]/a/text()') # 选取匹配到的li节点的第一个
print(result1)
result2 = html.xpath('//li[last()]/a/text()') # 选取匹配到的li节点的最后一个
print(result2)
result3 = html.xpath('//li[position()<3]/a/text()') # 选取匹配到的所有li节点中位置小于3,也就时第1,2个
print(result3)
result4 = html.xpath('//li[last()-2]/a/text()') # 选取匹配到的li节点的倒数第三个
print(result4) '''节点轴选择'''
html = etree.HTML(text)
result5 = html.xpath('//li[1]/ancestor::*') # 选取匹配到的li节点的第一个的所有祖先节点
print(result5)
result6 = html.xpath('//li[1]/attribute::*') # 选取匹配到的li节点的所有属性值
print(result6)
result7 = html.xpath('//li[1]/child::a') # 选取匹配到的li节点的所有子节点
print(result7)
result8 = html.xpath('//li[1]/descendant::a') # 选取匹配到的li节点的所有子孙节点
print(result8)
result9 = html.xpath('//li[1]/following::*') # 选取获取到的当前结点后的所有节点
print(result9)
result10 = html.xpath('//li[1]/following-sibling::*') # 选取获取到的当前结点之后的所有同级节点
print(result10)
python解析库之 XPath的更多相关文章
- python爬虫三大解析库之XPath解析库通俗易懂详讲
目录 使用XPath解析库 @(这里写自定义目录标题) 使用XPath解析库 1.简介 XPath(全称XML Path Languang),即XML路径语言,是一种在XML文档中查找信息的语言. ...
- 爬虫解析库:XPath
XPath XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言.最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的 ...
- python解析库
BeautifulSoup示例: #!/usr/bin/env python # -*- coding: utf-8 -*- # author: imcati html_doc = "&qu ...
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- xpath beautiful pyquery三种解析库
这两天看了一下python常用的三种解析库,写篇随笔,整理一下思路.太菜了,若有错误的地方,欢迎大家随时指正.......(conme on.......) 爬取网页数据一般会经过 获取信息-> ...
- Python3编写网络爬虫05-基本解析库XPath的使用
一.XPath 全称 XML Path Language 是一门在XML文档中 查找信息的语言 最初是用来搜寻XML文档的 但是它同样适用于HTML文档的搜索 XPath 的选择功能十分强大,它提供了 ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- (最全)Xpath、Beautiful Soup、Pyquery三种解析库解析html 功能概括
一.Xpath 解析 xpath:是一种在XMl.html文档中查找信息的语言,利用了lxml库对HTML解析获取数据. Xpath常用规则: nodename :选取此节点的所有子节点 // : ...
- python爬虫之html解析Beautifulsoup和Xpath
Beautiifulsoup Beautiful Soup 是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据.BeautifulSoup 用来解析 HTML 比较简 ...
随机推荐
- 爬虫(GET)——handler处理器和自定义opener
工具:python3 解释:urlopen()不支持代理.cookie等其他的http/https高级功能,所以需要handler处理器创建特定功能的处理器对象,urllib.request.buli ...
- ADC5513
一 C5513 u32 ADC5513_GetValue(void){ u32 ADValue,i; bool data_bit = false; C5513_SCK=0; C5513_CS ...
- spring assert 用法
spring在提供一个强大的应用开发框架的同时也提供了很多优秀的开发工具类,合理的运用这些工具,将有助于提高开发效率.增强代码质量.下面就最常用的Assert工具类,简要介绍一下它的用法.Assert ...
- webpack.config.js====插件html-webpack-plugin
1. 安装 cnpm install html-webpack-plugin --save-dev 2. webpack.config.js中使用 const htmlWebpackPlugin = ...
- Kendo MVVM 数据绑定(七) Invisible/Visible
Kendo MVVM 数据绑定(七) Invisible/Visible Invisible/Visible 绑定可以根据 ViewModel 的某个属性来显示/隐藏 DOM 元素.例如: <d ...
- react中constructor和super()以及super(props)的区别。
react中这两个API出镜率超级高,但是一直不太懂这到底是干嘛的,有什么用:今天整理一下,方便自己查看同时方便大家. 1.constructor( )-----super( )的基本含义 const ...
- iOS中转义后的html标签如何还原
最近用swift做一个公司的小项目,遇到一个问题,就是通过api获取的html文本中的标签都已经被转义了, <p class="MsoNormal" align=" ...
- 一键部署Moodle开源课程管理系统
产品详情 产品介绍Moodle https://moodle.org/ 是一个开源及自由的电子学习软件平台,亦称为课程管理系统.学习管理系统或虚拟学习环境.Moodle 特色异于其他商业线上教学平台, ...
- JVM的内存划分
1.栈内存:栈内存主要是用来运行函数的,在函数中定义的所有变量,都会在这个内存开辟空间. 在栈内存中定义的变量,不初始化,是不能直接使用的. 注意:所有的函数都必须在栈内存中运行. 而jvm只会运行处 ...
- SharePoint 2013 安装配置(2)
上一篇中,我们已经安装了Windows Server 2012 R2.现在第二部分,如何在Windows Server 2012 R2中安装Active Directory域控制器.请按照以下步骤. ...