http客户端与浏览器的区别
两者区别:浏览器对http响应头会进行特定处理(如自动读取本地缓存、设置cookie等),而http客户端(如crul)可能没有像浏览器那样的处理,某些封装程度高的http客户端,可能会有。
同一个文件夹中有三个文件:
使用了http标准库的js客户端:
const http = require('http');
const options = {
hostname: '127.0.0.1',
port: 8080,
path: '/api',
method: 'GET'
};
const req = http.request(options, function (res) {
console.log('STATUS:' + res.statusCode);
console.log('HEADERS:' + JSON.stringify(res.headers));
res.setEncoding('utf-8');
let data = "";
res.on('data', function (chunk) {
console.log(`接收到数据:${chunk}\r\n`);
data += chunk;
});
res.on('end', function () {
console.log('响应结束');
console.log('接收到的数据为:' + data);
});
});
req.end();
用于浏览器发起请求的h5页面:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div id="msg"></div>
<script>
var xhr = new XMLHttpRequest();
xhr.open("GET","http://127.0.0.1:8080/api",true);
xhr.send(null); xhr.onload = function(){
document.querySelector("#msg").innerHTML = xhr.responseText;
}
</script>
</body>
</html>
js服务端:
const http = require("http");
const fs = require("fs");
const server = http.createServer(function(req,res){
res.setHeader('Content-Type','text/html;charset=utf-8');
switch(true){
case req.url.startsWith('/index'):
fs.readFile('./index.html',"utf-8",function (_,data) {
res.end(data);
});
break;
case req.url.startsWith('/api'):
console.log(JSON.stringify(req.headers));
res.end("每次请求都返回一个随机数:" + Math.random());
break;
}
});
server.listen(8080,'127.0.0.1',function(){
console.log(`服务器运行在8080`);
});
后续测试环境为:
访问地址:http://127.0.0.1:8080/index
以上地址每次访问,都会显示不同的随机数。
测试强缓存
服务器返回数据前,加上个强缓存设置(10s):
case req.url.startsWith('/api'):
console.log(JSON.stringify(req.headers));
let curTime = +new Date();
let cacheOutDateTime = curTime + 10*1000;
let GMTTime = new Date(cacheOutDateTime).toGMTString();
res.setHeader('Expires', GMTTime);
res.end("每次请求都返回一个随机数:" + Math.random());
break;
浏览器访问地址:http://localhost:8080/index
10s内不停刷新浏览器,显示的随机数都是一样的,说明强缓存生效了。
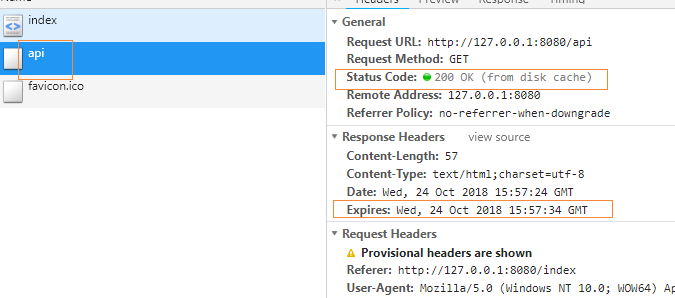
通过js客户端来访问,强缓存无效:
C:\Users\MRLWJ\Desktop\知识分享10-25\web\srv>node client.js
STATUS:200
HEADERS:{"content-type":"text/html;charset=utf-8","expires":"Wed, 24 Oct 2018 15:58:26 GMT","date":"Wed, 24 Oct 2018 15:58:16 GMT","connection":"close","content-length":"59"}
接收到数据:每次请求都返回一个随机数:0.005061696884948619 响应结束
接收到的数据为:每次请求都返回一个随机数:0.005061696884948619 C:\Users\MRLWJ\Desktop\知识分享10-25\web\srv>node client.js
STATUS:200
HEADERS:{"content-type":"text/html;charset=utf-8","expires":"Wed, 24 Oct 2018 15:58:27 GMT","date":"Wed, 24 Oct 2018 15:58:17 GMT","connection":"close","content-length":"57"}
接收到数据:每次请求都返回一个随机数:0.9111832960061363 响应结束
接收到的数据为:每次请求都返回一个随机数:0.9111832960061363
通过postman客户端来访问也是一样,强缓存无效。
结论:强缓存的头(这里测试的是expires)只能作用在浏览器上,对于这里的http客户端无效,因为这里的http客户端根本就没有用到那个http头,更别说还会自己去设置本地缓存了,这些工作浏览器才会去做。
测试协商缓存
添加一个etag头:
case req.url.startsWith('/api'):
console.log(JSON.stringify(req.headers));
res.setHeader('Etag', '123');
res.end("每次请求都返回一个随机数:" + Math.random());
break;
多次访问页面,浏览器自动带上了if-none-match头

但是协商缓存没有生效,以上两个数值明明一样的。原因在于if-none-match对应的数值,仅仅是给服务端用于校验而已,如果服务端没有读取这个值进行校验的话,则什么效果都没有。要有效果的话,则要求服务端校验完成后,返回个302状态码,才能使浏览器使用本地缓存。
if-none-match:代表本地已经有缓存了,而且这个缓存的标识符是123。服务器知道这些信息之后,再用于判断是否需要告诉浏览器去使用缓存(是否要返回304)。
假如直接返回304的话,则访问/api时,虽然能完成请求(打开chrome调试工具,显示响应状态码为304),但响应数据为空:
case '/api':
console.log(JSON.stringify(req.headers));
res.statusCode = 304;
res.end("每次请求都返回一个随机数:" + Math.random());
break;
正确的判断方式,以下设置了304之后,不管有没有返回正文内容,正文内容都会被忽略
case req.url.startsWith('/api'):
console.log(JSON.stringify(req.headers));
res.setHeader('Etag', "123");
if("123" == req.headers['if-none-match']){
res.statusCode = 304;
res.end();
}
res.end("每次请求都返回一个随机数:" + Math.random());
break;
}
});
修改完成后,用浏览器多次请求,都使用的是本地缓存,即显示到界面上的随机数一直无变化。
然后再用js客户端进行请求,结果如下:
C:\Users\MRLWJ\Desktop\知识分享10-25\web\srv>node client.js
STATUS:200
HEADERS:{"content-type":"text/html;charset=utf-8","etag":"123","date":"Wed, 24 Oct 2018 16:25:53 GMT","connection":"close","content-length":"57"}
接收到数据:每次请求都返回一个随机数:0.7875283103348185 响应结束
接收到的数据为:每次请求都返回一个随机数:0.7875283103348185 C:\Users\MRLWJ\Desktop\知识分享10-25\web\srv>node client.js
STATUS:200
HEADERS:{"content-type":"text/html;charset=utf-8","etag":"123","date":"Wed, 24 Oct 2018 16:25:54 GMT","connection":"close","content-length":"57"}
接收到数据:每次请求都返回一个随机数:0.2601388266595912 响应结束
接收到的数据为:每次请求都返回一个随机数:0.2601388266595912
结论: 因为这个http客户端没有像浏览器那样遵守了http规范,接收到etag时,下次请求时没有带上if-none-match,导致服务器没办法用于判断,所以一直返回200,导致协商缓存失效。
http客户端与浏览器的区别的更多相关文章
- ASP.NET程序单客户端(浏览器)登录的实现方案
需求描述:当用户的账户在另一个浏览器中登录的时候,需要把当前浏览器的登录强制下线.这种需求在业务系统,或付费视频服务网站中比较常见. 这种需求我称之为"单客户端(浏览器)"登录,与 ...
- Asp.Net 之 服务器端控件与客户端控件的区别
服务器控件,即Asp.Net的控件,控制这些控件必须经过服务器处理,然后响应用户,代码在服务器端解释执行,生成根据用户的浏览器而定的html元素. 客户端控件,即普通Html控件,使用script控制 ...
- H5案例分享:使用JS判断客户端、浏览器、操作系统类型
使用JS判断客户端.浏览器.操作系统类型 一.JS判断客户端类型 JS判断客户端是否是iOS或者Android手机移动端 通过判断浏览器的userAgent,用正则来判断手机是否是ios和Androi ...
- 《笔记篇》非JS方法跳转到一个新页面,主要防止客户端禁止浏览器JS以后的跳转异常
用非JS方法打开一个新页面,主要防止客户端禁止浏览器JS以后的跳转失效 <meta http-equiv="refresh" content="0; url=htt ...
- AP、路由、中继、桥接、客户端模式之间的区别
AP.路由.中继.桥接.客户端模式之间的区别 在TP-Link迷你无线路由器上一般有AP(接入点)模式.Router(无线路由)模式.Repeater(中继)模式.Bridge(桥接)模式. Clie ...
- 设置默认访问项目的客户端的浏览器版本(IE版本)
在项目开发部署中,发现浏览器不兼容现象,在不处理兼容性情况下让用户更好体验(IE浏览器) 我们来设置客户端默认访问项目的浏览器版本 如下所示的是不同IE版本下的效果截图比较: IE5.IE6下: IE ...
- JS 客户端(浏览器)存储数据之 localStorage、sessionStorage和indexDB
基本概念 1.localStorage和sessionStorage是HTML5 Web存储的提供的两种存储方式,在IE7以上以及大多数浏览器都是支持的 2.localStorage和sessionS ...
- 任务二:1、选择器 2、连接集中状态的顺序 3、浮动的用发和原理 4、盒模型在IE和Google等不同浏览器的区别与联系
1.选择器类型 标签选择器,类选择器,ID选择器,组合选择器,伪类和伪元素,属性选择器,子选择器,同胞选择器, :not()选择器 1.同胞选择器 相邻同胞标签: h2 + p{ color:red; ...
- ClientScriptManager与ScriptManager向客户端注册脚本的区别
使用ClientScriptManager向客户端注册脚本 ClientScriptManager在非异步(就是说非AJAX)环境下使用的.如果要在异步环境下注册脚本应该使用ScriptManager ...
随机推荐
- 字典排序permutation
理论 C++ 中的next_permutation 一般作为正序全排列的使用规则,其实这个就是正序字典排序的实现. 比如我们要对 列表 [1,2,3] 做full permutation 一般使用递 ...
- C# 数组之List<T>
一.引言 List<T>是ArrayList的泛型等效类,底层数据结构也是数组. 相比Array而言,可以动态的拓展数组长度.增删数据 相比ArrayList而言,由于声明的时候就已经规定 ...
- Python面向对象之类和实例
1.类的定义 定义是用过class关键字 class Student(object): pass class 后面紧接着是类名,即Student,类名通常是大写开头的单词, 紧接着是(object), ...
- GYM 101933D(最短路、二分、dp)
要点 非要先来后到暗示多源最短路,求最小的最大值暗示二分 二分内部的check是关键,dp处理一下,\(dp[i]\)表示第\(i\)笔订单最早何时送达,如果在ddl之前到不了则\(return\ 0 ...
- java join 方法的使用
在很多情况下,主线程创建并启动子线程,如果子线程中要进行大量的耗时运算,主线程往往将早于子线程结束之前结束.这时,如果主线程想等待子线程执行完成之后再结束,比如子线程处理一个数据,主线程要取得这个数据 ...
- Sql server 查询指定时间区间工作日数、休息日数等日期操作
1.查询指定时间区间的工作日 这个主要难点是法定节假日,国家的法定节假日每年都不一样,还涉及到调休,所以我们设计一个假日表.主要字段有年份,类型(是否调休),假期日期.如下: CREATE TABLE ...
- (2017.10.10) 我对 JavaScript 历史的认识
关于 JavaScript 的历史和来由相信学过 JavaScript 的小伙伴都能说出一二.我看过一些入门书籍第一章或者前言部分都有介绍,但是一直没捋清这段历史.今天通过两个问题,来加深我对 Jav ...
- python中的uuid4
Help on function uuid4 in module uuid: uuid4() Generate a random UUID.
- npm使用快速的安装源(nrm)
安装 npm install nrm --global 使用 nrm ls 切换安装源 nrm use taobao 测速 nrm test npm 参考地址:http://codingdict.co ...
- 链接服务器"(null)"的 OLE DB 访问接口 "SQLNCLI10" 返回了消息 "Cannot start more transactions on this session."
开发同事反馈一个SQL Server存储过程执行的时候,报"链接服务器"(null)"的 OLE DB 访问接口 "SQLNCLI10" 返回了消息 ...