Python scrapy框架爬取瓜子二手车信息数据
项目实施依赖:
python,scrapy ,fiddler
scrapy安装依赖的包:
可以到https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载 pywin32,lxml,Twisted,scrapy然后pip安装
项目实施开始:
1、创建scrapy项目:cmd中cd到需创建的文件目录下
scrapy startproject guazi
2、创建爬虫:cd到创建好的项目下
scrapy genspider gz guazi.com
3、分析目标网址:
第一次我直接用的谷歌浏览器的抓包分析,取得UA和Cookies请求,返回的html数据完全缺失,分析可能是携带的Cookies
有问题,然后就用fiddler抓包才,得到Cookies与谷歌上得到Cookies多了UA,时间等参数,
4、将UA,Cookies添加到下载中间中去:
class Guzi1DownloaderMiddleware(object):
def process_request(self, request, spider):
# 需要对得到的cookies处理成字典类型
request.cookies={}
request.headers["User-Agent"]=""
5、在settings中将DOWNLOADER_MIDDLEWARES打开
6、在spiders目录下找到gz.py开始编写爬虫逻辑处理
import scrapy
import time class GzSpider(scrapy.Spider):
name = 'gz'
allowed_domains = ['guazi.com']
start_urls = ['https://www.guazi.com/cd/buy/0'] def parse(self, response):
# 得到页面上所有车辆的url
url_list = response.xpath('//ul[@class="carlist clearfix js-top"]//li/a/@href').extract()
url_list = [response.urljoin(url) for url in url_list]
url_list = [url.replace("cq", "cd") for url in url_list]
for url in url_list:
yield scrapy.Request(url=url, callback=self.parse1, dont_filter=True) # 获取下一页的url
next_url = response.urljoin(response.xpath('//span[text()="下一页"]/../@href').extract_first())
if next_url:
yield scrapy.Request(url=next_url, callback=self.parse, dont_filter=True)
time.sleep(2) def parse1(self, response):
# 判断是否有数据
if response.xpath('//h2/text()').extract_first():
print(response.xpath('//h2/text()').extract_first().strip())
item = {}
item["车型"] = response.xpath('//h2/text()').extract_first().strip()
item["选车类型"] = response.xpath('//h2/span/text()').extract_first()
item["价格/万"] = response.xpath('//div[@class="pricebox js-disprice"]/span[1]/text()').extract_first().strip()
item["新车价格"] = response.xpath('//div[@class="pricebox js-disprice"]/span[2]/text()').extract_first().strip()
item["上牌时间"] = response.xpath('//ul[@class="basic-eleven clearfix"]/li[1]/div/text()').extract_first().strip()
item["公里数"] = response.xpath('//ul[@class="basic-eleven clearfix"]/li[2]/div/text()').extract_first().strip()
item["排量"] = response.xpath('//ul[@class="basic-eleven clearfix"]/li[3]/div/text()').extract_first().strip()
item["变速箱"] = response.xpath('//ul[@class="basic-eleven clearfix"]/li[4]/div/text()').extract_first().strip()
item["配置信息"] = response.xpath('//span[@class="type-gray"]//text()').extract()
item["网址"] = response.url
yield item
7、启动爬虫并保存为csv文件
scrapy crawl gz -o guanzi.csv
8、最后得到了想要的二手车信息,贴上部分截图
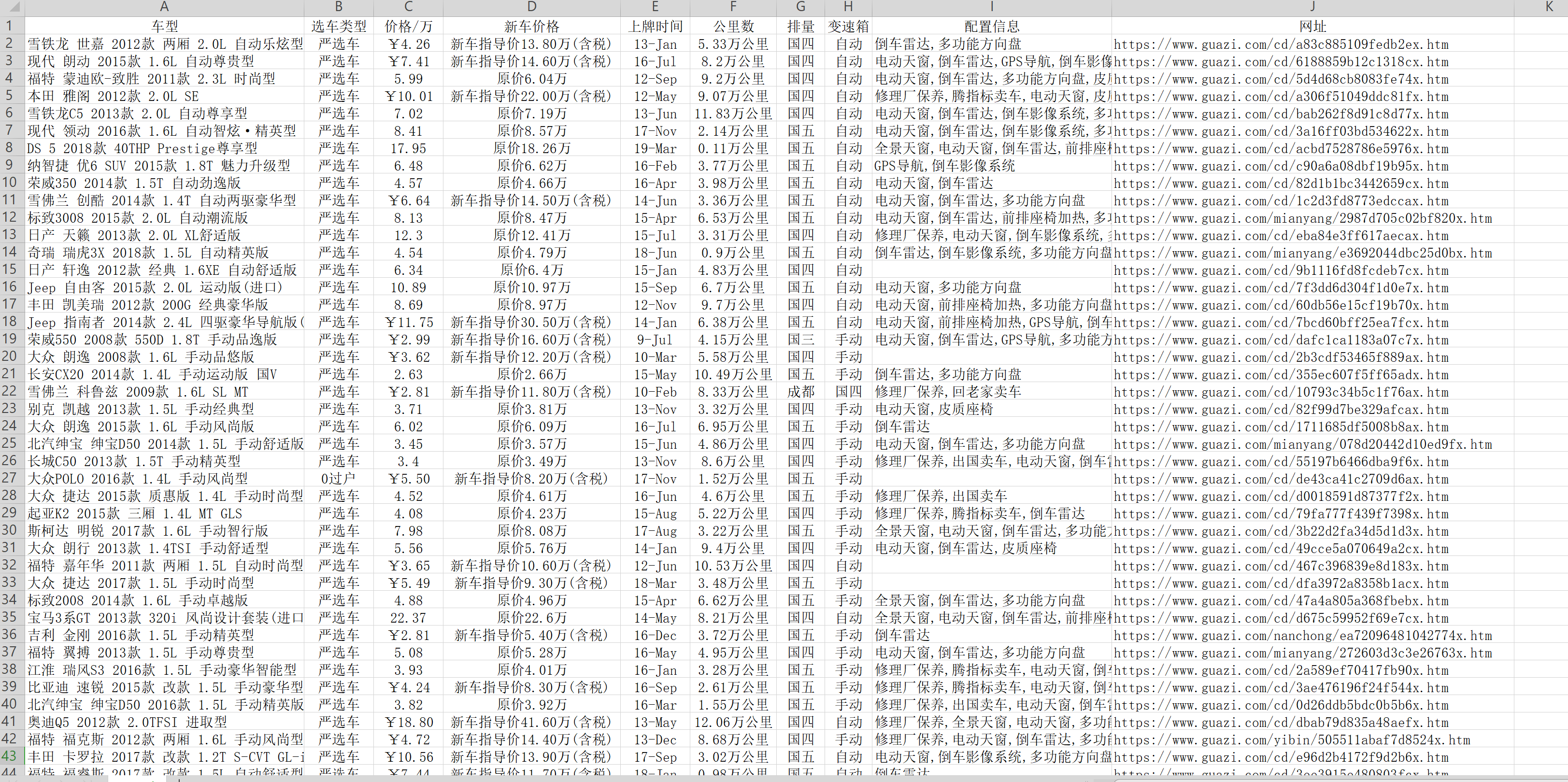
Python scrapy框架爬取瓜子二手车信息数据的更多相关文章
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- python scrapy框架爬取豆瓣
刚刚学了一下,还不是很明白.随手记录. 在piplines.py文件中 将爬到的数据 放到json中 class DoubanmoviePipelin2json(object):#打开文件 open_ ...
- Python——爬取瓜子二手车
# coding:utf8 # author:Jery # datetime:2019/5/1 5:16 # software:PyCharm # function:爬取瓜子二手车 import re ...
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- scrapy框架爬取小说信息
1.爬取目标网站:http://www.zhaoxiaoshuo.com/all.php?c=0&o=0&s=0&f=2&l=0&page=1 2.爬取目标网站 ...
- [Python学习] 简单爬取CSDN下载资源信息
这是一篇Python爬取CSDN下载资源信息的样例,主要是通过urllib2获取CSDN某个人全部资源的资源URL.资源名称.下载次数.分数等信息.写这篇文章的原因是我想获取自己的资源全部的评论信息. ...
- python之简单爬取一个网站信息
requests库是一个简介且简单的处理HTTP请求的第三方库 get()是获取网页最常用的方式,其基本使用方式如下 使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
随机推荐
- Qt中的打印操作
Qt中对打印的支持是有一个独立的printsupport模块来完成的,所以,要想在程序中使用Qt的打印功能,必须先在pro文件中添加下面这句代码: QT += printsupport在这个模块中,提 ...
- centOS7安装docker步骤
首先准备一台linux系统, Docker需要一个64位系统的系统,内核的版本必须大于3.10,可以用命令来检查是否满足要求: 满足条件后,下面开始正式安装步骤: 1.更新yum: sudo yum ...
- Disruptor学习杂记
慎入,有点乱,只是学习记录,disruptor_2.10.4 1.Disruptor对象有一个EventProcessorRepository对象 2.EventProcessorReposito ...
- 激活win10企业长期服务版
win10 2016 长期服务版的ISO文件中本身就带有KMS激活KEY,不用输入任何KEY,连接网络进入CMD,只要输入:slmgr /skms kms.digiboy.irslmgr /ato这两 ...
- [coci2012]覆盖字符串 AC自动机
给出一个长度为N的小写字母串,现在Mirko有M个若干长度为Li字符串.现在Mirko要用这M个字符串去覆盖给出的那个字符串的.覆盖时,必须保证:1.Mirko的字符串不能拆开,旋转:2.Mirko的 ...
- SpringMVC+Spring+MyBatis配置
今天配置项目时遇到一个问题,tomcat启动没有报错,但是访问页面的时总是报404,后台打印的日志是: 8080-exec-1] WARN springframework.web.servlet.Pa ...
- 配置Nginx四层负载均衡
nginx 支持TCP转发和负载均衡的支持 实现下面的架构: 看配置: #user nobody; worker_processes 1; #error_log logs/error.log; #er ...
- hadoop学习之旅2
集群搭建文档1.0版本 1. 集群规划 所有需要用到的软件: 链接:http://pan.baidu.com/s/1jIlAz2Y 密码:kyxl 2.0 系统安装 2.1 主机名配置 vi /etc ...
- 关于使用response.addHeader下载中文名乱码问题
介绍下我项目中遇到的问题:在数据库导出Excel文件的过程中,导出文件中文名始终异常,最终结果发现需要在response.addHeader 中的 filename = "xxxx" ...
- BZOJ_3729_Gty的游戏_博弈论+splay+dfs序
BZOJ_3729_Gty的游戏_博弈论+splay+dfs序 Description 某一天gty在与他的妹子玩游戏. 妹子提出一个游戏,给定一棵有根树,每个节点有一些石子,每次可以将不多于L的石子 ...