ELK安装配置简单使用
ELK是三款软件的总称,包括了elasticsearch、logstash、kibana,其实在生产使用中,我们还需要使用到其他的更多辅助软件来更好更合理的收集展示数据。
Elasticsearch:一个分布式的搜索查询服务器,提供了rest接口
Logstash:收集处理并传出日志,他安装在需要被收集日志的服务器上(暂时)
Kibana:一个web展示操作页面,从Elasticsearch提供的接口获取数据并做一些常用操作
使用ELK解决的问题:
- 开发人员可以完全不登录服务器也可以拿到需要的日志了
- 各个系统、集群日志分散,不统一,需要一台台去专门查询
- 日志量过大,常规查询分析方法太慢
那么我们现在来规划下,三台节点,node1、node2、node3。其中node1、node2作为Elasticsearch的分布式集群节点,并且都安装Kibana来提供web页面,而node3则为我们需要收集日志的目标机器,他只需要安装Logstash即可
首先我们要先去获取安装包,我们三种软件全部都下载同一版本(5.6.5)的rpm包,下载网址https://www.elastic.co/downloads/past-releases,然后分别上传到对应服务器上
然后回到node1上
[root@linux-node1 ~]# yum install java elasticsearch-5.6..rpm kibana-5.6.-x86_64.rpm –y
[root@linux-node1 ~]# grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: elk-cluster- # 集群名称,用来区分不同elk集群
node.name: node- # 集群内该节点名称,不可重复
path.data: /elk/data # 数据目录,即分散着被检索的日志
path.logs: /elk/logs # 日志目录
network.host: 192.168.56.11 # 自己的ip
http.port: # 对外访问端口。集群内部进行选举、通讯用的是9300端口
discovery.zen.ping.unicast.hosts: ["192.168.56.11", "192.168.56.12"] # 自动广播的目标,因为是广播,如果广播的机器过多,可能会影响到网络质量,所以规定好只向某些机器广播即可
[root@linux-node1]# mkdir /elk
[root@linux-node1]# systemctl start elasticsearch.service
[root@linux-node1]# ls /elk/ # 发现神马都木有
这是因为我们的elasticsearch默认的启动用户是elasticsearch,此时的/elk目录权限不够
[root@linux-node1]# chown elasticsearch:elasticsearch -R /elk
[root@linux-node1]# systemctl restart elasticsearch.service
[root@linux-node1 ~]# ls /elk/
data logs
[root@linux-node1 ~]# grep "^[a-Z]" /etc/kibana/kibana.yml
server.port: # 打开的端口,默认就是5601
server.host: "192.168.56.11" # 监听的ip地址,默认是localhost
elasticsearch.url: http://192.168.56.11:9200 # 从该elasticsearch的获取数据来展示
[root@linux-node1 ~]# systemctl start kibana.service
[root@linux-node1 ~]# ss –tln # 发现9200、、5601都有啦
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN *: *:*
LISTEN *: *:*
LISTEN *: *:*
LISTEN *: *:*
LISTEN *: *:*
LISTEN *: *:*
LISTEN 192.168.56.11: *:*
LISTEN ::: :::*
LISTEN ::ffff:192.168.56.11: :::*
LISTEN ::ffff:192.168.56.11: :::*
LISTEN ::: :::*
LISTEN ::ffff:127.0.0.1: :::*
此时node1上的操作就完成了,但是现在elasticsearch里并没有数据供我们检索查询,所以我们要去配置node3收集点日志,不过在此之前我们先去配置node2
[root@linux-node2 ~]# yum install java elasticsearch-5.6..rpm kibana-5.6.-x86_64.rpm -y
[root@linux-node2 ~]# grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: elk-cluster- # 让他们处于统一elk集群里
node.name: node- # 这个要变
path.data: /elk/data
path.logs: /elk/logs
network.host: 192.168.56.12 # 这个要变
http.port:
discovery.zen.ping.unicast.hosts: ["192.168.56.11", "192.168.56.12"]
[root@linux-node2]# mkdir /elk
[root@linux-node1]# chown elasticsearch:elasticsearch -R /elk
[root@linux-node2]# systemctl start elasticsearch.service
[root@linux-node2 ~]# ls /elk/
data logs
[root@linux-node2 ~]# grep "^[a-Z]" /etc/kibana/kibana.yml
server.port: # 打开的端口,默认就是5601
server.host: "192.168.56.12" # 监听的ip地址,默认是localhost
elasticsearch.url: http://192.168.56.12:9200 # 从该elasticsearch的获取数据来展示
[root@linux-node2 ~]# systemctl start kibana.service
现在的情况很明显了,node1与node2组成了一个elasticsearch集群,我们向他们两个任意一个的9200端口传输获取数据都可以,而他们也都同时提供了kibana页面供我们访问,熟悉高可用负载均衡的朋友就可以一眼看出,我提供一个vip给kibana与elasticsearch做负载就可以保证生产时的环境了,没错就是酱,但是这点小事我们就不执行了,其实很简单啊,就几分钟的事情。
[root@linux-node3 ~]# yum install java logstash-5.6..rpm –y
[root@linux-node3 ~]# cd /etc/logstash/conf.d/ # 以后所有的配置规则都在这里哦
[root@linux-node3 conf.d]# cat systemlog.conf
input { # 数据来源定义,可定义多个
file { # 从文件中获取
path => "/var/log/messages" # 文件路径
start_position => "beginning" # 从文件开头获取还是从现在开始,默认从现在
type => "systemlog-5613" # 类别名自定义,最好具有良好的辨认性
stat_interval => "" # 获取时间间隔,默认1秒,太频繁了
}
} output { # 数据输出定义,可定义多个
elasticsearch { # 向elasticsearch输出
hosts => ["192.168.56.11:9200"] # elasticsearch的url
index => "system-log-5613-%{+YYYY.MM.dd}" # 自定义,最好具有良好的辨认性,最后的%{+YYYY.MM.dd}是取当前的时间戳
}
file { # 向文件输出
path => "/tmp/systemlog.txt" # 输出路径
}
}
[root@linux-node3 tmp]# chmod /var/log/messages # messages的权限特殊是600
[root@linux-node3 ~]# systemctl start logstash
[root@linux-node3 ~]# tail - /tmp/systemlog.txt
{"@version":"","host":"linux-node3.example.com","path":"/var/log/messages","@timestamp":"2017-12-15T10:30:02.990Z","message":"Dec 15 18:30:01 linux-node3 systemd: Starting Session 62 of user root.","type":"systemlog-5613"}
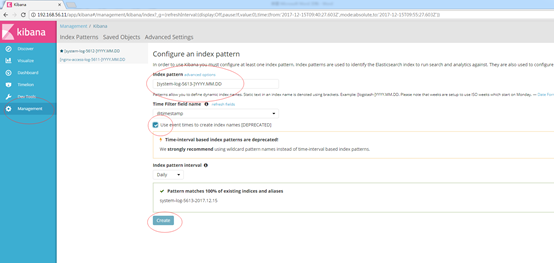
[system-log-5613-]YYYY.MM.DD,这个就是我们刚才的index,不同的是最后时间戳的表示是DD,然后我们勾选使用时间戳创建,确认到了匹配的数据索引后创建
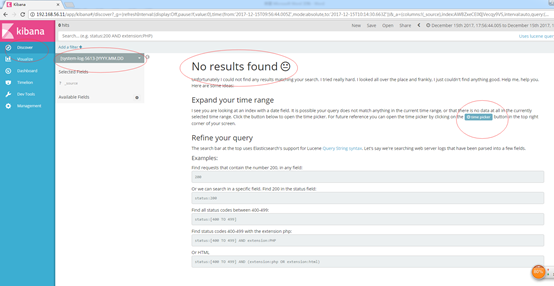
发现没有数据,wtf,劳资费了这么大劲就给我看这个? 我们点击蓝色按钮调整下查找的时间轴
我们点击蓝色按钮调整下查找的时间轴
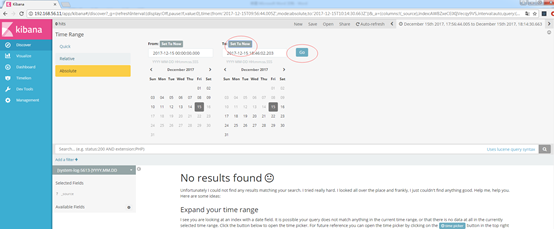
设置成起始时间今天,截至时间为当前再次查询
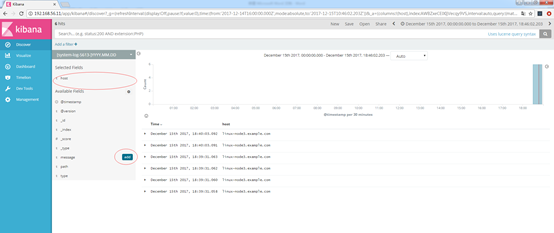
有点信心了,我们选择排列host跟message,这样就可以直观的对比数据了
ELK安装配置简单使用的更多相关文章
- elk安装配置
ELK介绍 官网https://www.elastic.co/cn/ 中文指南https://www.gitbook.com/book/chenryn/elk-stack-guide-cn/det ...
- ELK安装配置及nginx日志分析
一.ELK简介1.组成ELK是Elasticsearch.Logstash.Kibana三个开源软件的组合.在实时数据检索和分析场合,三者通常是配合使用,而且又都先后归于 Elastic.co 公司名 ...
- saltstack master minion安装配置简单使用
首先先了解下saltstack是什么,为什么使用它 它与Ansible.Puppet都属于集中管理工具,由于现在企业规模的不断庞大及业务的增长,所需要管理的服务器数量增多,而且大部分机器都属于同类业务 ...
- puppet yum安装配置,简单证书维护
Puppet学习之puppet的安装和配置 一.Puppet简介 Puppet基于ruby语言开发的自动化系统配置工具,可以C/S模式或独立运行,支持对所有UNIX及类UNIX系统的配置管理,最新版本 ...
- Jenkins安装配置简单使用
安装启动是十分简单的,直接去https://jenkins.io/download/下载对应的rpm包就好了,需要注意的是我们的机器上要提前有java环境,相对应要选择你java环境可以支持的jenk ...
- Katalon Studio 安装 配置 简单使用
本教程只针对Katalon Studio进行演示操作. 一.下载 Katalon 官网下载地址:https://www.katalon.com/download/ (需要注册账号) 二.解压.配置 直 ...
- Linux下elk安装配置
安装jdkJDK版本大于1.8 elk下载地址:https://www.elastic.co/products注意:elk三个版本都要保持一致. rpm -ivh elasticsearch-5.4. ...
- Cobbler安装配置简单使用
安装Cobbler [root@linux-node3 ~]# yum -y install epel-release [root@linux-node3 ~]# yum -y install cob ...
- glusterfs安装配置简单使用
GlusterFS是一种分布式分布式文件系统,默认采用无中心完全对等架构,搭建维护使用十分简单,是很受欢迎的分布式文件系统. 官网https://www.gluster.org/,官网上表示Glust ...
随机推荐
- JavaScript之this的工作原理
JavaScript 有一套完全不同于其它语言的对 this 的处理机制. 在五种不同的情况下 ,this 指向的各不相同. 1.全局范围内 当在全部范围内使用 this,它将会指向全局对象. 2.函 ...
- 16 redis之sentinel运维监控
一:sentinel运维监控 Sentinel不断与master通信,获取master的slave信息. 监听master与slave的状态 如果某slave失效,直接通知master去除该slave ...
- 研究下JavaScript中的Rest參数和參数默认值
研究下JavaScript中的Rest參数和參数默认值 本文将讨论使 JavaScript 函数更有表现力的两个特性:Rest 參数和參数默认值. Rest 參数 通常,我们须要创建一个可变參数的函数 ...
- Epplus使用技巧
废话不说,直接开始. 创建Excel工作表 private static ExcelWorksheet CreateSheet(ExcelPackage p, string sheetName) { ...
- sql 时间转换格式
convert(varchar(10),字段名,转换格式) CONVERT(nvarchar(10),count_time,121)CONVERT为日期转换函数,一般就是在时间类型(datetime, ...
- (转)ConcurrentModificationException异常原因和解决方法
原文地址: http://www.cnblogs.com/dolphin0520/p/3933551.html 一.ConcurrentModificationException异常出现的原因 先看下 ...
- python中的raw字符串
在正则表达式的字符串前面加上r表示这个是一个raw字符串,只以正则表达式的元字符进行解析,不用理会ascii的特殊字符.
- Cocos2d-js官方完整项目教程翻译:六、添加Chipmunk物理引擎在我们的游戏世界里
添加Chipmunk物理引擎在我们的游戏世界里 一.简介 cocos2d JS能给我们力量来创造令人印象深刻的游戏世界.但缺乏某种现实. ...
- maven-appfuse配备步骤
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/qiaqia609/article/details/36231851 maven-appfuse配置步 ...
- tmux基本使用方法
tmux是一款优秀的终端复用软件.tmux采用C/S模型构建,输入tmux命令就相当于开启了一个服务器,此时默认将新建一个会话,然后会话中默认新建一个窗口,窗口中默认新建一个面板. 一个tmux se ...