内存分配器 (Memory Allocator)
对于大多数开发人员而言,系统的内存分配就是一个黑盒子,就是几个API的调用。有你就给我,没有我就想别的办法。
来UC前,我就是这样觉得的。实际深入进去时,才发现这个领域里也是百家争鸣。非常热闹。有操作系统层面的内存分配器(Memory Allocator)。有应用程序层面的,有为实时系统设计的,有为服务程序设计的。
但他们的目的却是一样的。平衡内存分配的性能和提高内存使用的效率。
从浏览器开发的角度看,手机内存的增长速度相对于网页内容的增长仍然仅仅是温饱水平,像Android本身就是用内存大户。另一个Low Memory Killer, 一定要优化内存占用。整体上对策就是两点:一是能不用就不用,代码里可能隐藏着非常多不必要内存分配。特别留意那些中间量。二是能少用就少用,特别避免频繁分配。由于那样仅仅会添加内存碎片,到了极端时即使仍有内存可用,也分配不出来了。还有一个选项: 换个内存分配器。这样一是假设内存分配器优良就能够缓解内存碎片,也能够在出现OOM时控制程序的行为,崩与不崩、崩在哪里就能够自己控制了。
近期由于工作原因。涉及到了小内存分配器,所以做了一些粗浅的学习。没有完整的阅读代码。也没有进行透彻的測试,仅仅是写个总结以及相关的文档放在这里,备查。
内存分配的现实问题
首先通常使用的内存分配器,即malloc/free函数并非系统提供的,而是C标准库提供的。也被称为动态内存分配器。分配器从操作系统拿内存(虚拟内存)时是以页为单位(一般是4KB,调用sbrk或mmap), 然后再自行管理。
上面也提到了,内存分配器面对的是两个核心问题: 效能和性能(或称为吞吐量Throughoutput)。 前者保证随时有内存可用,后者保证服务时间短、不拖后腿。
对于一个系统进程而言,面对OOM(Out Of Memory)问题,排除程序使用内存的Bug外,会有两个原因:
1.系统真的没有内存可用了。
2.内存分配浪费了大量空间。尽管有大量零散的可用空间,却无法合并提供出来使用。 前者才是真正的OOM, 后者就是内存碎片(Fragmentation)问题了。
libc里的malloc遇到分配失败时,默认会abort掉进程。也就是崩掉(CRASH)了。
假设系统支持mallopt就有机会改变这个行为。可惜Android还没有支持。
浏览器在载入、解析、渲染页面的时候,会分配大量的小对象,看张图就明确了:
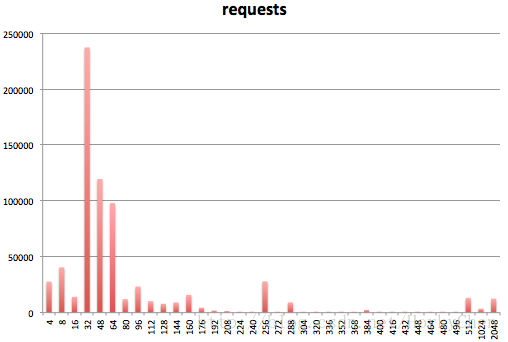
上图中模轴为对象大小,纵轴则为申请分配的次数。假设内存都以页为单位申请,就简单,也就不须要分配器。就是那些小对象,占用不多,使用频繁,非常easy造成页内无法再继续使用的碎片(Internal Fragmentation)。
对于性能,内存分配是次于I/O的一个瓶径。
尽管绝大多数情况下都相安无事。但内存分配器有一个重要的指标,即上限(bounded limits)。尽管平均值看起非常好,但一旦遇到最坏的情况(wrost case)时。能不能保证性能?特别是多线程下,内存分配、释放的性能经常受到加锁的影响。有些分配器(如ptmalloc)过于考虑性能,而无法使线程间的内存共享,各自占去一块,反而减少了内存使用的效率。
这些问题一直存在。不同的人针对不同的场景设计出了不同的分配器算法(DSA, Dynamic Storage Algorithms, 是以应用的角度来看的)。并且差点儿每一个都说自己比别人强。比方:
1. dlmalloc/ptmalloc/ptmallocX C标准库提供的分配器, 也是应用程序默认使用的malloc/free等函数。
2. tcmalloc 出自Google, WebKit/Chrome中应用。
3. bmalloc 毕竟Chrome和WebKit越走越远。所以Apple在WebKit最新代码(2014-04)里提供了新的分配器,号称远远超过 TCMalloc, 至少是在性能上。
4. jemalloc 原本是为FreeBSD开发的,后来Firefox浏览器和FaceBook的服务端都加以应用,它自身也在这些应用中得到了大幅提升。
5. Hoard 一个专为多线程优化的分配器, 作者是大学教授。有一些独特的技术。Mac OS X中的malloc就有參考事实上现进行优化。
*WebKit另外专为Render Object提供了一个所谓的Plain Old Data Areana的类,也算是一个Memory Pool的实现(PODIntervalTree, PODArena)。
核心思想和算法
分配器这么多,其核心思想类似,仅仅是差在算法和metadata存储上。附13提供的论文中有比較全面的总结,能够翻看一下。
内存分配器的核心思想概括起来三条:
1. 基本功能:首先将内存区(Memory Pool)以最小单位(chunk)定义出来。然后区分对象大小分别管理内存。小内存分成若干类(size class),专门用来分配固定大小的内存块,并用一个表管理起来。减少内部碎片(internal fragmentation)。大内存则以页为单位管理, 配合小对象所在的页,减少碎片。设计一个好的存储方案。即metadata的存储。减少对内存的占用。
同一时候优化内存信息的存储,以使对每一个size class或大内存区域的訪问的性能最优且有上限(bounded limits)。
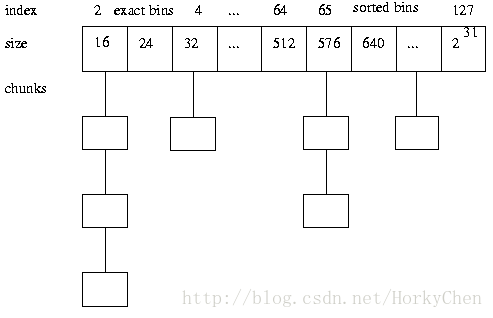
比方dlmalloc定义的是一个个bins(同size class)来存储不同大小的内存块:
2. 回收及预測功能: 当释放内存时。要能够合并小内存为大内存,依据一些条件,该保留的就保留起来,在下次使用时能够高速的响应。不须要保留时。则释放回系统。避免长期占用。
3. 优化多线程下性能问题:针对多线程环境下,每一个线程能够独立占有一段内存区间。被称为TLS(Thread Local Storage)。这样线程内操作时能够不加锁,提高性能。
下图是MSDN上贴出的关于TLS的原理图,能够參考:
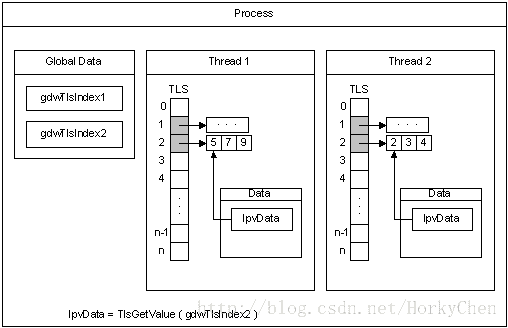
*另外測试工具也是不可缺少,比方tcmalloc的heap profile, jemalloc则结合valgrind。FireFox在移植jemalloc到Android时。特别关掉了TLS,想必是考虑到它对于线程单一应用的副作用。
上面这些思路对于各个分配器而言基本是一致,但详细怎样组织size classes, 假设以一个固定步长,必将形成一个巨大且效率低下的表。原因參考第一张图就明确了。
非常多年前,就有专门的论文对此做了评定(链接)。另外还有怎样定位内存块? 怎样解决多线程下的false cache line问题? 不同的分配器使用了不同的算法和数据结构来实现。它们所使用的算法统称为DSA, Dynamic Storage Algorithms。
详细的算法实现能够在以下的參考列表中找到相应的文档, 也能够先看附16。文中分别对DSA Algorithms和DSA Operational Model做了描写叙述,概括的非常好。会有一个整体的印象。作者将DSA算法分为五类:
1. Sequential Fit
是基于一个单向或双向链表管理各个blocks的基础算法。由于和blocks的个数有关。性能比較差。这一类算法包含Fast-Fit, First-Fit, Next-Fit, and Worst-Fit。
2. Segregated Free List (离散式空暇列表)
使用一个数组,每一个元素是存储特定大小内存块的链表。它们所代表的大小并非连续的,所以称为离散。经典的dlmalloc使用的就是这个算法。数据元素,參照上面的图就能够理解了。TLSF算法则是基于此进行了改进。
3. Buddy System
这是由一代大师Donald Knuth提出。兴许产生很多的改进版本号。最大的作用是解决外部碎片(external fragmentation), 详细的算法。參考这篇(浅析Linux内核内存管理之Buddy System)。
4. Indexed Fit
以某种数据结构为每一个block建立索引,以求能够高速存取。
一般以一个二叉树结构实现。比方使用Balanced Tree的Best Fit allocator, 以及基于Cartesian tree 的Stephenson Fast-Fit allocator。这类算法的性能比較高,也比較稳定。
5. Bitmap Fit
这类算法仅仅是索引方法不同,使用以位图式字节表示存储单元的状态。它的优点是使用一小块连续的内存,响应性能更好。
Half-Fit就属于这类算法。
随着技术演进。如今主流的allocators, 基本上都是综合运用了两类以上的算法。
另外一些基础算法也是类似的。比方以二叉树组织列表的算法,也就是in-place, 笛卡尔树 和red-block的差异。在线程上。则由于实现的不同,会导致内存占用的差异。比方jemalloc在释放时,并不须要在原来的分配线程运行释放。仅仅是被放回到分配线程的free list中去。ptmalloc则必须回到分配线程里运行释放,性能就相对弱一些。
tcmalloc则设计了算法。让一个线程能够从它的邻居那里偷一些空间来(这个过程称为transfer cache)。这样能够有效地利用线程间的内存。
优劣势对照
ptmalloc 劣势:多线程下的性能及内存占用(线程间内存无法共享),并且内存用于存储metadata开销较大。在小内存分配上浪费比較多。
优势:算是标准实现。
tcmalloc 劣势:由于算法的设计,占用的内存较大。优势:多线程下的性能。參考附6。
jemalloc 优势: 内存碎片率低。多核下性能较tcmalloc更好。參考附17。
时间有限,没有再深入研究,后面有空再补充一下。在实际应用中,还是有一些參数能够调整的,前提是要熟悉事实上现,特别是性能评估的方法。
转载请注明出处: http://blog.csdn.net/horkychen
參考
这是我列的最长的參考清单了。前人的确已经做了非常多的研究,我对当中内容仅仅是泛读,并非全部内容都相关,仅仅是觉得有些内容能够相互应证就也列进来了。
1. jemalloc关于使用red-block tree的反思 [链接]
文章公布于2008年。作者在2009年将其应用于FaceBook时。则是进行了算法上优化。
2. 2011年jemalloc作者在FaceBook应用jemalloc后撰文介绍了jemalloc的核心算法及在Facebook上应用效果。
[链接] [早期的论文,有很多其他的细节]
3. Android碎片化的度量 通过改造ROM做的实验。
4. Hoard Offical [链接]
5. Mac OS上malloc是怎么工作的[链接]
6. 关于WebKit应用tcmalloc的对照[链接]
7. How tcmalloc works[链接] [中文翻译]
8. TCMalloc源码分析,非常不错资料。
作者的站点还有其他干货值得一读。[链接]
9. dlmalloc早期的技术文档,讲述了其核心算法。[链接]
10. ptmalloc源码分析,讲的非常系统。非常值得一读。[CSDN下载链接]
11. 介绍jemalloc的资料《更好的内存管理-jemalloc》[链接]
12. 替换系统malloc的四种方法 [链接]
13. 介绍针对实时系统进行优化的内存分配算法TLSF,当中对动态分配算法(DSA)做了总结。[链接]
14. 维基百科上关于Thread Local Storage的说明, 或许你能感受到技术的相通性。[链接]
15. 针对实时系统进行各种分配算法的对照,能够结合13一起看。
[链接]
16. ptmalloc,tcmalloc和jemalloc内存分配策略研究。[链接]
17. Firefox3使用jemalloc后的总结,能够看到Firefox优化的思路。[链接] [Firefox使用的源码]
18. Chromimum Project: Out of memory handling, 里面有不错的观点。 [链接]
内存分配器 (Memory Allocator)的更多相关文章
- 14.6.4 Configuring the Memory Allocator for InnoDB 配置InnoDB 内存分配器
14.6.4 Configuring the Memory Allocator for InnoDB 配置InnoDB 内存分配器 当InnoDB 被开发时,内存分配提供了操作系统和 run-time ...
- 14.4.4 Configuring the Memory Allocator for InnoDB InnoDB 配置内存分配器
14.4.4 Configuring the Memory Allocator for InnoDB InnoDB 配置内存分配器 当InnoDB 被开发, 内分配齐 提供了与操作系统和运行库往往缺乏 ...
- php Allocator Jemalloc TCMalloc那个内存分配器比较好?
php Allocator Jemalloc TCMalloc那个内存分配器比较好? php一键安装脚本可以选择是否安装内存优化 You have 3 options for your Memory ...
- 从零开始写STL-内存部分-内存分配器allocator
从零开始写STL-内存部分-内存分配器allocator 内存分配器是什么? 一般而言,c++的内存分配和释放是这样操作的 >>class Foo{ //...}; >>Foo ...
- SQL Server 2012 内存管理 (memory management) 改进
SQL Server 2012 的内存管理和以前的版本相比,有以下的一些变化. 一.内存分配器的变化 SQL Server 2012以前的版本,比如SQL Server 2008 R2等, 有sing ...
- [转]STL的内存分配器
题记:内存管理一直是C/C++程序的红灯区.关于内存管理的话题,大致有两类侧重点,一类是内存的正确使用,例如C++中new和delete应该成对出现,用RAII技巧管理内存资源,auto_ptr等方面 ...
- CoreCLR源码探索(三) GC内存分配器的内部实现
在前一篇中我讲解了new是怎么工作的, 但是却一笔跳过了内存分配相关的部分. 在这一篇中我将详细讲解GC内存分配器的内部实现. 在看这一篇之前请必须先看完微软BOTR文档中的"Garbage ...
- [内存管理]连续内存分配器(CMA)概述
作者:Younger Liu, 本作品采用知识共享署名-非商业性使用-相同方式共享 3.0 未本地化版本许可协议进行许可. 原文地址:http://lwn.net/Articles/396657/ 1 ...
- 内核早期内存分配器:memblock
内核早期内存分配器:memblockLinux内核使用伙伴系统管理内存,那么在伙伴系统工作前,如何管理内存?答案是memblock.memblock在系统启动阶段进行简单的内存管理,记录物理内存的使用 ...
随机推荐
- linux基础学习7
Linux 的开机流程分析 1. 加载 BIOS 的硬件信息与进行自我测试,并依据设定取得第一个可开机的装置: 2. 读取并执行第一个开机装置内 MBR 的 boot Loader (亦即是 gr ...
- Define Custom Data Filter Using Pre-Query Trigger In Oracle Forms
Oracle Forms is having its default records filter, which we can use through Enter Query mode to spec ...
- 解决官网下载jdk只有5k大小的错误
问题现象 官网 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 我选择linu ...
- 分治法寻找第k大的数
利用快速排序的思想·去做 #include<iostream>using namespace std;int FindKthMax(int*list, int left, int righ ...
- 【京东个人中心】——Nodejs/Ajax/HTML5/Mysql爬坑之功能与数据分析
一.引言 在学习了Nodejs和HTML5之后,发现了Nodejs的使用很方便,和php是完全不同的另一种后台语言.我也明白了,在一个项目里,是不可能同时存在Apach服务器(php)和Web服务器( ...
- MySQL binlog-do-db选项是危险的[转]
很多人通过 binlog-do-db, binlog-ignore-db, replicate-do-db 和 replicate-ignore-db 来过滤复制(某些数据库), 尽管有些使用, ...
- Android中Java与web通信
Android中Java与web通信不是新的技术了,在android公布之初就支持这样的方式,2011年開始流行,而这样的模式开发也称作Hybird模式. 这里对android中的Java与web通信 ...
- apue学习笔记(第十二章 线程控制)
本章将讲解控制线程行为方面的详细内容,而前面的章节中使用的都是它们的默认行为 线程属性 pthread接口允许我们通过设置每个对象关联的不同属性来细调线程和同步对象的行为.管理这些属性的函数都遵循相同 ...
- RF ---library
RF内置库: http://robotframework.org/robotframework/ SSHLibrary: ---WEB自动化测试 http://robotframework.org ...
- c语言中结构体指针
1.指向结构体的指针变量: C 语言中->是一个总体,它是用于指向结构体,如果我们在程序中定义了一个结构体,然后声明一个指针变量指向这个结构体.那么我们要用指针取出结构体中的数据.就要用到指向运 ...