SQL 中的group by (转载)
- 概述
- 原始表
- 简单Group By
- Group By 和 Order By
- Group By中Select指定的字段限制
- Group By All
- Group By与聚合函数
- Having与Where的区别
- Compute 和 Compute By
1、概述
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
2、原始表
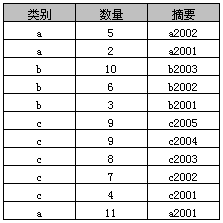
3、简单Group By
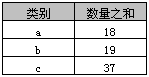
示例1
select 类别, sum(数量) as 数量之和
from A
group by 类别
返回结果如下表,实际上就是分类汇总。
4、Group By 和 Order By
示例2
select 类别, sum(数量) AS 数量之和
from A
group by 类别
order by sum(数量) desc
返回结果如下表
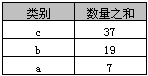
在Access中不可以使用“order by 数量之和 desc”,但在SQL Server中则可以。
5、Group By中Select指定的字段限制
示例3
select 类别, sum(数量) as 数量之和, 摘要
from A
group by 类别
order by 类别 desc
示例3执行后会提示下错误,如下图。这就是需要注意的一点,在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。

6、Group By All
示例4
select 类别, 摘要, sum(数量) as 数量之和
from A
group by all 类别, 摘要
示例4中则可以指定“摘要”字段,其原因在于“多列分组”中包含了“摘要字段”,其执行结果如下表
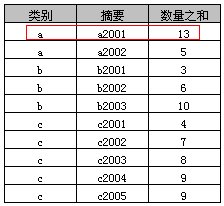
“多列分组”实际上就是就是按照多列(类别+摘要)合并后的值进行分组,示例4中可以看到“a, a2001, 13”为“a, a2001, 11”和“a, a2001, 2”两条记录的合并。
SQL Server中虽然支持“group by all”,但Microsoft SQL Server 的未来版本中将删除 GROUP BY ALL,避免在新的开发工作中使用 GROUP BY ALL。Access中是不支持“Group By All”的,但Access中同样支持多列分组,上述SQL Server中的SQL在Access可以写成
select 类别, 摘要, sum(数量) AS 数量之和
from A
group by 类别, 摘要
7、Group By与聚合函数
在示例3中提到group by语句中select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中,常见的聚合函数如下表:
| 函数 | 作用 | 支持性 |
|---|---|---|
| sum(列名) | 求和 | |
| max(列名) | 最大值 | |
| min(列名) | 最小值 | |
| avg(列名) | 平均值 | |
| first(列名) | 第一条记录 | 仅Access支持 |
| last(列名) | 最后一条记录 | 仅Access支持 |
| count(列名) | 统计记录数 | 注意和count(*)的区别 |
示例5:求各组平均值
select 类别, avg(数量) AS 平均值 from A group by 类别;
示例6:求各组记录数目
select 类别, count(*) AS 记录数 from A group by 类别;
示例7:求各组记录数目
8、Having与Where的区别
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
示例8
select 类别, sum(数量) as 数量之和 from A
group by 类别
having sum(数量) > 18
示例9:Having和Where的联合使用方法
select 类别, SUM(数量)from A
where 数量 gt;8
group by 类别
having SUM(数量) gt; 10
9、Compute 和 Compute By
select * from A where 数量 > 8
执行结果:

示例10:Compute
select *
from A
where 数量>8
compute max(数量),min(数量),avg(数量)
执行结果如下:

compute子句能够观察“查询结果”的数据细节或统计各列数据(如例10中max、min和avg),返回结果由select列表和compute统计结果组成。
示例11:Compute By
select *
from A
where 数量>8
order by 类别
compute max(数量),min(数量),avg(数量) by 类别
执行结果如下:
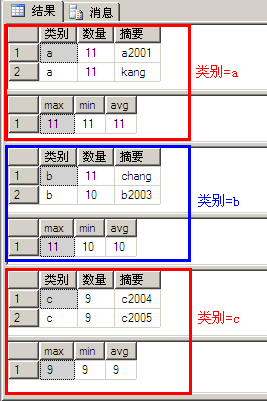
示例11与示例10相比多了“order by 类别”和“... by 类别”,示例10的执行结果实际是按照分组(a、b、c)进行了显示,每组都是由改组数据列表和改组数统计结果组成,另外:
- compute子句必须与order by子句用一起使用
- compute...by与group by相比,group by 只能得到各组数据的统计结果,而不能看到各组数据
在实际开发中compute与compute by的作用并不是很大,SQL Server支持compute和compute by,而Access并不支持
原文链接:http://www.cnblogs.com/rainman/archive/2013/05/01/3053703.html
SQL 中的group by (转载)的更多相关文章
- sql中的group by 和 having 用法解析
转载博客:http://www.cnblogs.com/wang-123/archive/2012/01/05/2312676.html --sql中的group by 用法解析:-- Group B ...
- sql中的group by 和 having 用法
sql中的group by 用法:-- Group By语句从英文的字面意义上理解就是“根据(by)一定的规则进行分组(Group)”.--它的作用是通过一定的规则将一个数据集划分成若干个小的区域,然 ...
- SQL中CASE 的用法 转载
sql语言中有没有类似C语言中的switch case的语句?? 没有,用case when 来代替就行了. 例如,下面的语句显示中文年月 select getdat ...
- mongoDB 分组并对分组结果筛选类似于SQL中的(group by xxx having ) 附带Java代码
今天需要做一个筛选程序,因为数据放在mongodb中,没写过分组的查询语句,查了一些资料,终于写出来了,分享给各位小伙伴 需求是 查询 学员 在2019-07-29之后未同步的数据(同一个学员需要2条 ...
- 详解SQL中的GROUP BY语句
下面为您介绍SQL语句中GROUP BY 语句,GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组. 希望对您学习SQL语句有所帮助. SQL GROUP BY 语法 SELEC ...
- SQL中的 group by 1, order by 1 语句
看到group by 1,2 和 order by 1, 2.看不懂,google,搜到了Stack Overflow 上有回答 What does SQL clause “GROUP BY 1” m ...
- sql中group by 和having 用法解析
--sql中的group by 用法解析:-- Group By语句从英文的字面意义上理解就是“根据(by)一定的规则进行分组(Group)”.--它的作用是通过一定的规则将一个数据集划分成若干个小的 ...
- 转载:SQL中Group By 的常见使用方法
SQL中Group By 的常见使用方法 转载源:http://www.cnblogs.com/wang-meng/p/5373057.html 前言今天逛java吧看到了一个面试题, 于是有了今天 ...
- SQL中Group By的使用
1.概述 2.原始表 3.简单Group By 4.Group By 和 Order By 5.Group By中Select指定的字段限制 6.Group By All 7.Group By与聚合函 ...
随机推荐
- HTTP缓存控制
HTTP缓存控制总结 引言 通过网络获取内容既缓慢,成本又高.大的相应需要在客户端和服务器之间多次往返通信,这拖延了浏览器可以使用和处理内容的时间,同时也增加了通信的成本.因此,缓存和重用以前获取 ...
- 选择排序(java)
选择排序的思想是:内外两层循环,第一层循环从第一个数开始到倒数第一个数, 第二层循环从上一层的数开始, 与上一层循环的数比较,如果小于则交换位置. 代码如下: public class SelectS ...
- phpstrom添加monokai-sublime主题
phpstrom默认的主题看起来不是特别舒服,sublime的主题却相当养眼,搜索之后,大为惊喜. 下载地址:https://github.com/sumiaowen/jetbrains-monoka ...
- NFS原理详解
NFS原理详解 摘自:http://atong.blog.51cto.com/2393905/1343950 2013-12-23 12:17:31 标签:linux NFS nfs原理详解 nfs搭 ...
- POJ 3281 Dining (网络流之最大流)
题意:农夫为他的 N (1 ≤ N ≤ 100) 牛准备了 F (1 ≤ F ≤ 100)种食物和 D (1 ≤ D ≤ 100) 种饮料.每头牛都有各自喜欢的食物和饮料, 而每种食物或饮料只能分配给 ...
- Kth Largest Element in a Stream
Design a class to find the kth largest element in a stream. Note that it is the kth largest element ...
- [51nod] 1267 4个数和为0 暴力+二分
给出N个整数,你来判断一下是否能够选出4个数,他们的和为0,可以则输出"Yes",否则输出"No". Input 第1行,1个数N,N为数组的长度(4 < ...
- python列表逆序三种方法
栗子: # 题目:将一个数组逆序输出. # # 程序分析:用第一个与最后一个交换. import random list =[random.randint(0,100) for _ in range( ...
- 【Unity】物理碰撞实验
http://www.cnblogs.com/javawebsoa/archive/2013/05/18/3085818.html 这几天为了准备面试,所以决定对平时学习中的盲点扫盲一下,首先想到的就 ...
- 汇总:unity中弹道计算和击中移动目标计算方法
http://download.jikexueyuan.com/detail/id/432.html 弹道计算是游戏里常见的问题,其中关于击中移动目标的自动计算提前量的话题,看似简单,其实还是挺复杂的 ...