machine learning for hacker记录(2) 数据分析
本章主要讲了对数据的一些基本探索,常见的six numbers,方差,均值等
> data.file <- file.path('data', '01_heights_weights_genders.csv')
> heights.weights <- read.csv(data.file, header = TRUE, sep = ',')
> heights <- with(heights.weights, Height)
> summary(heights)
Min. 1st Qu. Median Mean 3rd Qu. Max.
54.26 63.51 66.32 66.37 69.17 79.00
上面是six numbers:最小值,第一个四分位数,中位数(注意跟均值的区别),均值,第三个四分位数,最大值
中位数跟均值的区别:中位数 就是指数据排序后处于中间的那个数,而均值就是算术平均值,在R中可以直接用函数mean(),median()来求出。
同时,R中的quantile函数是计算数据的分位数的,默认情况是0%,25%,50%,75%,100%,例如:
> quantile(heights)
0% 25% 50% 75% 100%
54.26313 63.50562 66.31807 69.17426 78.99874
> quantile(heights,probs=seq(0,1,by=0.2))
0% 20% 40% 60% 80% 100%
54.26313 62.85901 65.19422 67.43537 69.81162 78.99874
> quantile(heights,probs=c(0,0.1,0.5,0.9,1))
0% 10% 50% 90% 100%
54.26313 61.41270 66.31807 71.47215 78.99874
后面两个就是自定义所需的分位数。
对于一份数据 光有six numbers 可能还不能很好的刻画数据的分布,对此统计学家引入了方差、标准差的概念,方差是明确了数据集中数据与均值的平均偏离程度,标准差是sqrt(方差)。对应R语言内置的函数var(),std()可以计算。
以上讲的是一些简单的统计学术语,接下来描述的是有关数据可视化的相关技术,并引出了一些基本的分布。
对上面heigths的数据,画出身高的频率直方图
ggplot(heights.weights, aes(x = Height)) +geom_histogram(binwidth = 1)
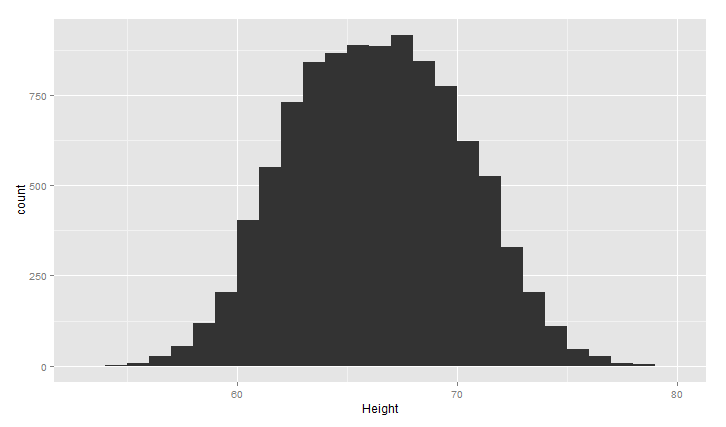
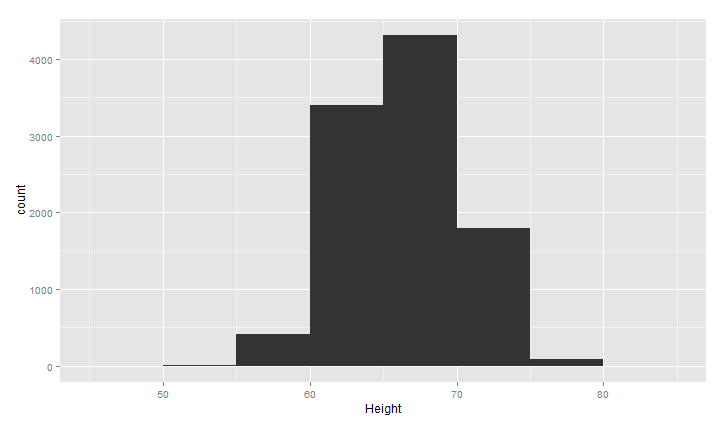
上面的图大致呈现正太分布,中间高,两边低,binwidth是直方图的宽度,设置不同,图形效果不同,下面看两种情况(过平滑和欠平滑)
ggplot(heights.weights, aes(x = Height)) +geom_histogram(binwidth = 5)
ggplot(heights.weights, aes(x = Height)) +geom_histogram(binwidth = 0.001)
同时,可以用核密度估计KDE/密度曲线图来描述数据分布:
ggplot(heights.weights, aes(x = Height)) +geom_density()
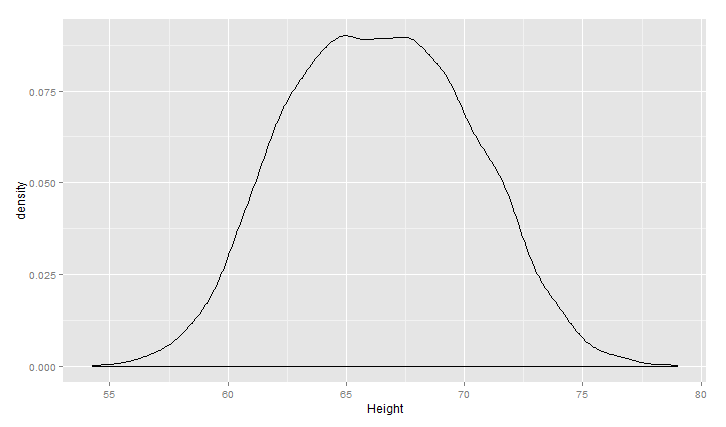
把数据样本分性别来看
ggplot(heights.weights, aes(x = Height,fill=Gender)) +geom_density()
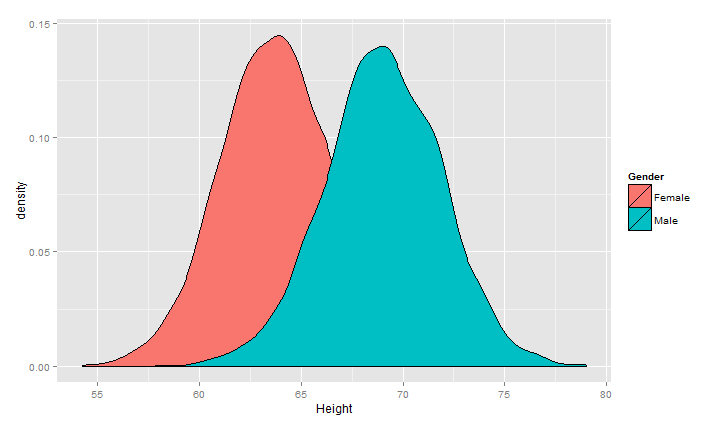
对两个曲线画成子图的模式
ggplot(heights.weights, aes(x = Height,fill=Gender)) +geom_density() +facet_grid(Gender~.)
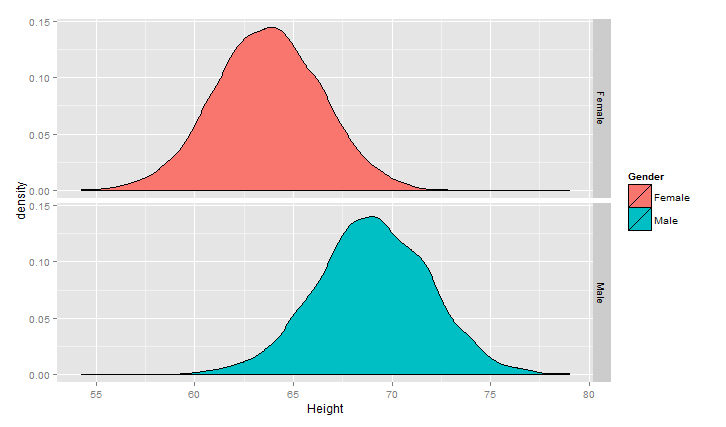
对上面的情况可以描述为高斯(正态)混合模型,正态分布应用范围非常广泛,链接http://songshuhui.net/archives/76501很清晰的讲了正态分布的“前世今生”,下面看一下高斯分布在不同均值跟方差下的 图形情况.
> m<-0
> s<-1
> ggplot(data.frame(X=rnorm(100000,m,s)), aes(x = X)) +geom_density()
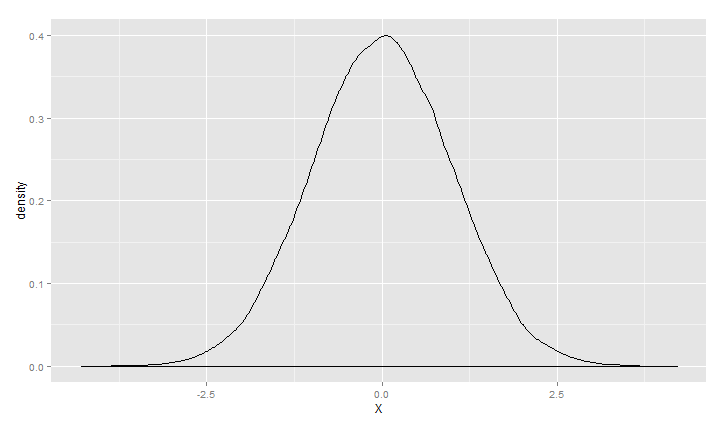
> m<-1
> s<-3
> ggplot(data.frame(X=rnorm(100000,m,s)), aes(x = X)) +geom_density()
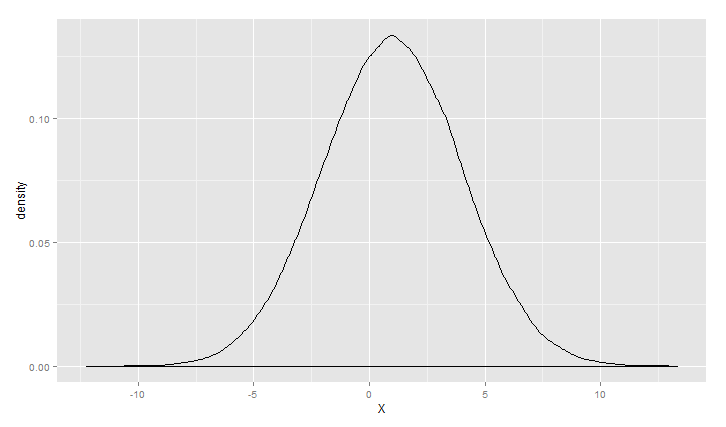
> m<-0
> s<-5
> ggplot(data.frame(X=rnorm(100000,m,s)), aes(x = X)) +geom_density()
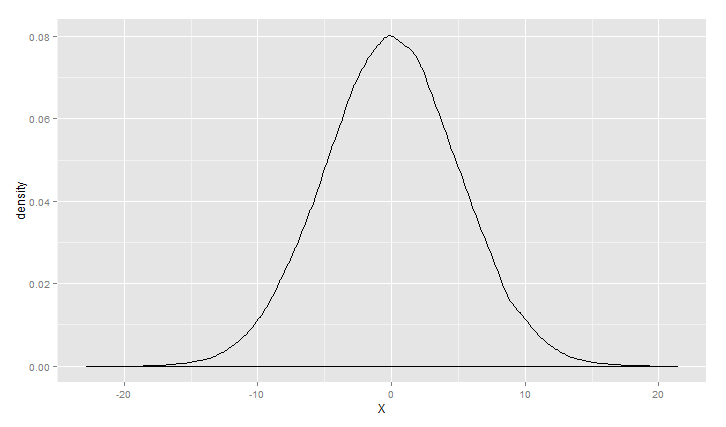
正态分布在99%的情况下所产生的的数据偏离均值不会超过3个标准差,但是对于柯西分布来说,只有90%。
> ggplot(data.frame(X=rcauchy(100000,0,1)), aes(x = X)) +geom_density()
伽玛分布
>ggplot(data.frame(X=rcauchy(100000,0,1)), aes(x = X)) +geom_density()
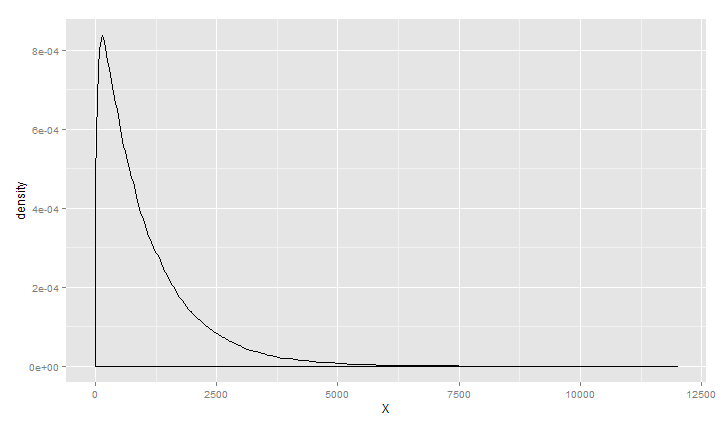
书中还统计苹果手机游戏《屋顶狂奔》的得分,KDE曲线符合伽玛分布,现实好多数据分布也是伽玛分布,如企业呼叫中心收到呼叫请求的时间间隔,还有游戏数据等等;
以上所有的绘图都是单变量的可视化,接着可以看下两个变量之间的关系
散点图
>ggplot(heights.weights, aes(x = Height,y=Weight)) +geom_point()

从图中看到,这两个变量存在某种关系,如越高的人,体重越大
>ggplot(heights.weights, aes(x = Height,y=Weight)) +geom_point() +geom_smooth()

对画图中加入性别
>ggplot(heights.weights, aes(x = Height,y=Weight,color=Gender)) +geom_point() +geom_smooth()
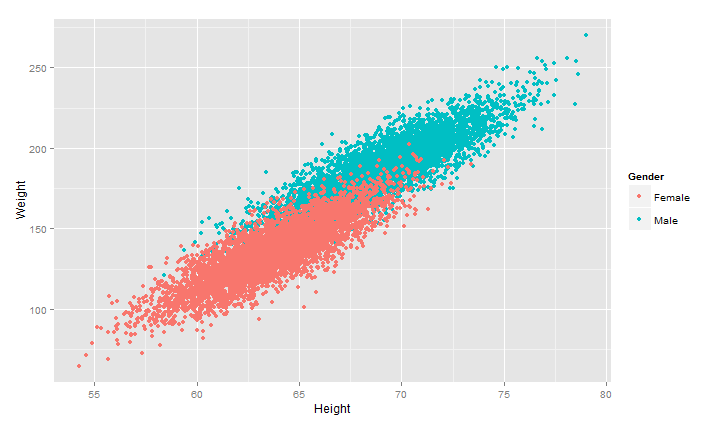
可以看出男女的分界线很鲜明,很容易用分类算法根据身高、体重来预测其性别,详细的分类算法下回分解O(∩_∩)O
machine learning for hacker记录(2) 数据分析的更多相关文章
- machine learning for hacker记录(3) 贝叶斯分类器
本章主要介绍了分类算法里面的一种最基本的分类器:朴素贝叶斯算法(NB),算法性能正如英文缩写的一样,很NB,尤其在垃圾邮件检测领域,关于贝叶斯的网上资料也很多,这里推荐那篇刘未鹏写的http://mi ...
- machine learning for hacker记录(4) 智能邮箱(排序学习&推荐系统)
本章是上一章邮件过滤技术的延伸,上一章的内容主要是过滤掉垃圾邮件,而这里要讲的是对那些正常的邮件是否可以加入个性化元素,由于每个用户关心的主题并非一样(有人喜欢技术类型的邮件或者购物促销方便的内容邮件 ...
- machine learning for hacker记录(1) R与机器学习
开篇:首先这本书的名字很霸气,全书内容讲的是R语言在机器学习上面的应用,一些基本的分类算法(tree,SVM,NB),回归算法,智能优化算法,维度约减等,机器学习领域已经有很多成熟的R工具箱,毕竟这个 ...
- Machine Learning in Action(3) 朴素贝叶斯算法
贝叶斯决策一直很有争议,今年是贝叶斯250周年,历经沉浮,今天它的应用又开始逐渐活跃,有兴趣的可以看看斯坦福Brad Efron大师对其的反思,两篇文章:“Bayes'Theorem in the 2 ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料汇总 (上)
转载:http://dataunion.org/8463.html?utm_source=tuicool&utm_medium=referral <Brief History of Ma ...
- 机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- 聊天机器人(chatbot)终极指南:自然语言处理(NLP)和深度机器学习(Deep Machine Learning)
在过去的几个月中,我一直在收集自然语言处理(NLP)以及如何将NLP和深度学习(Deep Learning)应用到聊天机器人(Chatbots)方面的最好的资料. 时不时地我会发现一个出色的资源,因此 ...
随机推荐
- MySQL的一个麻烦事
1. 开启一个MySQL连接,在这个连接中发起一个事务,进行一些操作但不提交 2. 拔网线 3. 重连网线,再开启一个MySQL连接,执行delete操作,发现stpe 1中占用的资源没有被释放 4. ...
- RabbitMQ 消费端限流、TTL、死信队列
目录 消费端限流 1. 为什么要对消费端限流 2.限流的 api 讲解 3.如何对消费端进行限流 TTL 1.消息的 TTL 2.队列的 TTL 死信队列 实现死信队列步骤 总结 消费端限流 1. 为 ...
- 017.View与窗口:AttachInfo
每一个View都需要依赖于窗口来显示,而View和窗口的关系则是放在View.AttachInfo中,关于View.AttachInfo的文章少,因为这个是View的内部类而且不是公共的,在应用层用的 ...
- linux安装开源邮件服务器iredmail的方法:docker
直接安装的方法,参考网文,我不介绍.本文介绍的是快速的方法:docker 使用镜像源:https://hub.docker.com/r/lejmr/iredmail/,因为pull的数量最多 直接 d ...
- Access自定义函数(人民币大写)
人民币大写函数:整数不超过13位. Public Function 人民币大写(A) As String Dim aa As String Dim bb As String Dim cc As Str ...
- DELPHI的BPL使用
了解BPL和DLL的关系将有助于我们更好地理解DELPHI在构件制作.运用和动态.静态编译的工作方式.对初学DELPHI但仍对DELPHI开发不甚清晰的朋友有一定帮助.第一部分:有关包的介绍 一般我们 ...
- 学习笔记 Java类的封装、继承和多态 2014.7.10
1.问题:toString()没搞懂? int a = 1; Integer aa = new Integer(a); //这是实现的过程 System.out.println("Hello ...
- fastjson中Map与JSONObject互换,List与JOSNArray互换的实现
1.//将map转换成jsonObject JSONObject itemJSONObj = JSONObject.parseObject(JSON.toJSONString(itemMap)); 将 ...
- 【翻译自mos文章】使用asmcmd命令在本地和远程 asm 实例之间 拷贝asm file的方法
使用asmcmd命令在本地和远程 asm 实例之间 拷贝asm file的方法 參考原文: How to Copy asm files between remote ASM instances usi ...
- Hibernate中的条件查询完毕类
Hibernate中的条件查询有下面三个类完毕: 1.Criteria:代表一次查询 2.Criterion:代表一个查询条件 3.Restrictions:产生查询条件的工具类