spark 划分stage Wide vs Narrow Dependencies 窄依赖 宽依赖 解析 作业 job stage 阶段 RDD有向无环图拆分 任务 Task 网络传输和计算开销 任务集 taskset
每个job被划分为多个stage。划分stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个stage,从而避免多个stage之间的消息传递开销。
http://spark.apache.org/docs/latest/rdd-programming-guide.html
【Spark actions are executed through a set of stages, separated by distributed “shuffle” operations. 】
Shared Variables
Normally, when a function passed to a Spark operation (such as map or reduce) is executed on a remote cluster node, it works on separate copies of all the variables used in the function. These variables are copied to each machine, and no updates to the variables on the remote machine are propagated back to the driver program. Supporting general, read-write shared variables across tasks would be inefficient. However, Spark does provide two limited types of shared variables for two common usage patterns: broadcast variables and accumulators.
Broadcast Variables
Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used, for example, to give every node a copy of a large input dataset in an efficient manner. Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost.
Spark actions are executed through a set of stages, separated by distributed “shuffle” operations. Spark automatically broadcasts the common data needed by tasks within each stage. The data broadcasted this way is cached in serialized form and deserialized before running each task. This means that explicitly creating broadcast variables is only useful when tasks across multiple stages need the same data or when caching the data in deserialized form is important.
Broadcast variables are created from a variable v by calling SparkContext.broadcast(v). The broadcast variable is a wrapper around v, and its value can be accessed by calling the value method. The code below shows this:
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)After the broadcast variable is created, it should be used instead of the value v in any functions run on the cluster so that v is not shipped to the nodes more than once. In addition, the object v should not be modified after it is broadcast in order to ensure that all nodes get the same value of the broadcast variable (e.g. if the variable is shipped to a new node later).
Accumulators
Accumulators are variables that are only “added” to through an associative and commutative operation and can therefore be efficiently supported in parallel. They can be used to implement counters (as in MapReduce) or sums. Spark natively supports accumulators of numeric types, and programmers can add support for new types.
As a user, you can create named or unnamed accumulators. As seen in the image below, a named accumulator (in this instance counter) will display in the web UI for the stage that modifies that accumulator. Spark displays the value for each accumulator modified by a task in the “Tasks” table.
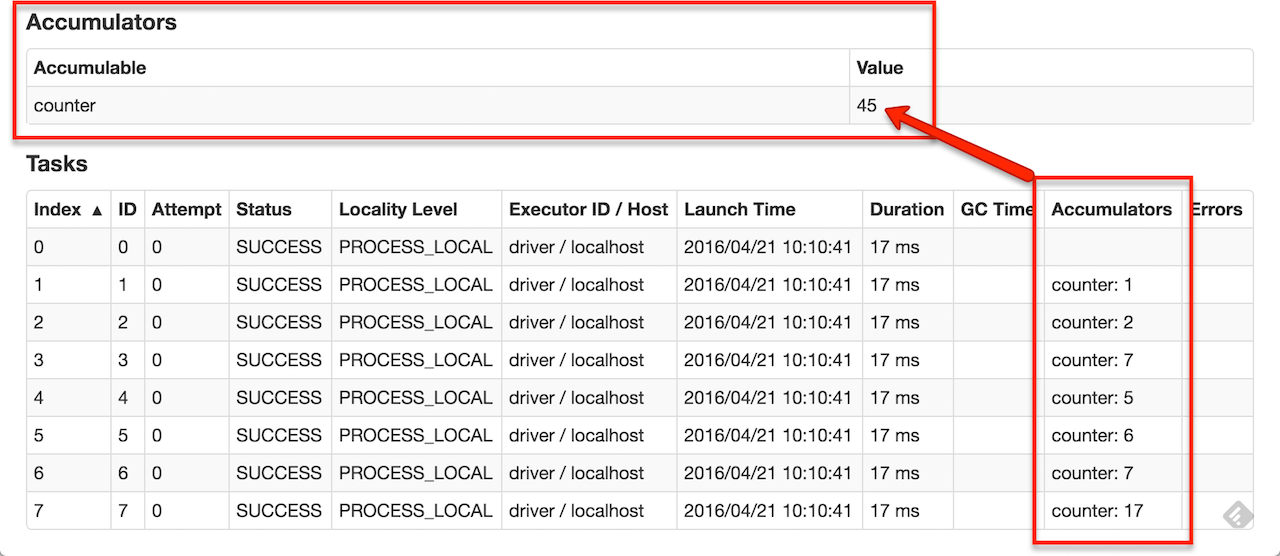
Tracking accumulators in the UI can be useful for understanding the progress of running stages (NOTE: this is not yet supported in Python).
A numeric accumulator can be created by calling SparkContext.longAccumulator() or SparkContext.doubleAccumulator() to accumulate values of type Long or Double, respectively. Tasks running on a cluster can then add to it using the add method. However, they cannot read its value. Only the driver program can read the accumulator’s value, using its value method.
The code below shows an accumulator being used to add up the elements of an array:
scala> val accum = sc.longAccumulator("My Accumulator")
accum: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 0, name: Some(My Accumulator), value: 0)
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
...
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
scala> accum.value
res2: Long = 10While this code used the built-in support for accumulators of type Long, programmers can also create their own types by subclassing AccumulatorV2. The AccumulatorV2 abstract class has several methods which one has to override: reset for resetting the accumulator to zero, addfor adding another value into the accumulator, merge for merging another same-type accumulator into this one. Other methods that must be overridden are contained in the API documentation. For example, supposing we had a MyVector class representing mathematical vectors, we could write:
class VectorAccumulatorV2 extends AccumulatorV2[MyVector, MyVector] {
private val myVector: MyVector = MyVector.createZeroVector
def reset(): Unit = {
myVector.reset()
}
def add(v: MyVector): Unit = {
myVector.add(v)
}
...
}
// Then, create an Accumulator of this type:
val myVectorAcc = new VectorAccumulatorV2
// Then, register it into spark context:
sc.register(myVectorAcc, "MyVectorAcc1")Note that, when programmers define their own type of AccumulatorV2, the resulting type can be different than that of the elements added.
For accumulator updates performed inside actions only, Spark guarantees that each task’s update to the accumulator will only be applied once, i.e. restarted tasks will not update the value. In transformations, users should be aware of that each task’s update may be applied more than once if tasks or job stages are re-executed.
Accumulators do not change the lazy evaluation model of Spark. If they are being updated within an operation on an RDD, their value is only updated once that RDD is computed as part of an action. Consequently, accumulator updates are not guaranteed to be executed when made within a lazy transformation like map(). The below code fragment demonstrates this property:
Scala
Java
Python
val accum = sc.longAccumulator
data.map { x => accum.add(x); x }
// Here, accum is still 0 because no actions have caused the map operation to be computed.
Narrow Wide Dependencies 宽依赖 窄依赖
shuffle
窄依赖 宽依赖 解析
Wide vs Narrow Dependencies · rohgar/scala-spark-4 Wiki · GitHub https://github.com/rohgar/scala-spark-4/wiki/Wide-vs-Narrow-Dependencies
窄 父RDD的一个分区,在RDD转换过程中,最多只会被一个子RDD的分区使用
宽 多个
一个Spark应用程序会被分解为多个作业Job提交给Spark集群进行处理。然而,作业并不是应用程序被执行的最小计算单元。
Spark集群收到作业后还要就爱那个作业继续进行2次切分和规划,并进行相应的调度。
第一步:将作业按照RDD转换操作处理为最小的处理单元,即任务Task
第二步:对任务进行规划,生成包含多个任务的阶段Stage
这两步都是由SparkContext创建的DAGScheduler实例进行
其输入是一个作业中的RDD有向无环图,输出为一系列任务
对应宽依赖,应尽量切分到不同的阶段中,以避免过大的网络传输和计算开销
连续窄依赖的RDD转换,则尽量多地放入同一个阶段
一旦遇到一个宽依赖的类型的RDD转换操作,则生成一个新的阶段
整个依赖链被划分为多个stage阶段,每个stage内都是一组互相关联、但彼此之间没有shuffle依赖关系的任务集合,称为任务集 Taskset。
DAGScheduler不仅负责将作业分割为多个阶段,还负责管理调度阶段的提交。
waitingStages集合
runningStages集合
failedStages集合
DAGScheduler是反向遍历整个RDD依赖链
Task调度
DAG
DAGScheduler
TaskScheduler 为每一个收到的TaskSet创建一个TaskSetManager,TaskSetManager决定每个Task应该在哪个物理在哪个物理资源上执行,并将调度计划发给TaskScheduler,TaskScheduler将Task提交给Spark集群实际执行。
TaskScheduler通过ShedulerBackend来了解可以分给应用程序的物理资源的的情况。
TaskSetManager不与底层实际的物理节点通信。
Scheduling Within an Application
Job Scheduling - Spark 2.3.0 Documentation http://spark.apache.org/docs/latest/job-scheduling.html
作业的两种调度顺序
spark 划分stage Wide vs Narrow Dependencies 窄依赖 宽依赖 解析 作业 job stage 阶段 RDD有向无环图拆分 任务 Task 网络传输和计算开销 任务集 taskset的更多相关文章
- 窄依赖与宽依赖&stage的划分依据
RDD根据对父RDD的依赖关系,可分为窄依赖与宽依赖2种. 主要的区分之处在于父RDD的分区被多少个子RDD分区所依赖,如果一个就为窄依赖,多个则为宽依赖.更好的定义应该是: 窄依赖的定义是子RDD的 ...
- Spark --【宽依赖和窄依赖】
前言 Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过程划分stage,暴力的理解就是stage的划分是按照有没有涉及到shuffle来划分的,没涉及的shuffle的都划 ...
- Spark 中的宽依赖和窄依赖
Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过程划分stage,而划分依据就是RDD之间的依赖关系.针对不同的转换函数,RDD之间的依赖关系分类窄依赖(narrow de ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- Spark宽依赖、窄依赖
在Spark中,RDD(弹性分布式数据集)存在依赖关系,宽依赖和窄依赖. 宽依赖和窄依赖的区别是RDD之间是否存在shuffle操作. 窄依赖 窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用 ...
- 大数据开发-从cogroup的实现来看join是宽依赖还是窄依赖
前面一篇文章提到大数据开发-Spark Join原理详解,本文从源码角度来看cogroup 的join实现 1.分析下面的代码 import org.apache.spark.rdd.RDD impo ...
- 021 RDD的依赖关系,以及造成的stage的划分
一:RDD的依赖关系 1.在代码中观察 val data = Array(1, 2, 3, 4, 5) val distData = sc.parallelize(data) val resultRD ...
- 小记--------spark的宽依赖与窄依赖分析
窄依赖: Narrow Dependency : 一个RDD对它的父RDD,只有简单的一对一的依赖关系.RDD的每个partition仅仅依赖于父RDD中的一个partition,父RDD和子RDD的 ...
- Spark剖析-宽依赖与窄依赖、基于yarn的两种提交模式、sparkcontext原理剖析
Spark剖析-宽依赖与窄依赖.基于yarn的两种提交模式.sparkcontext原理剖析 一.宽依赖与窄依赖 二.基于yarn的两种提交模式深度剖析 2.1 Standalne-client 2. ...
随机推荐
- vue.js源码学习分享(六)
/* */ /* globals MutationObserver *///全局变化观察者 // can we use __proto__?//我们能用__proto__吗? var hasProto ...
- Notepad++中常用的插件【转】
转自:http://www.crifan.com/files/doc/docbook/rec_soft_npp/release/htmls/npp_common_plugins.html 1.4. N ...
- Day 15 python 之 列表、元组、字典
基础: #! /usr/bin/env python # -*- coding: utf-8 -*- # __author__ = "DaChao" # Date: 2017/6/ ...
- PHP将emoji表情进行过滤
emoji表情是个麻烦的东西,不仅储存的时候需要处理,而且在PC的显示上需要三方的类库来处理.并且它还是经常更新.... 最近开发新项目的时候明确要求某个字段要过滤emoji表情,在网上找了个方法,亲 ...
- java并发之hashmap源码
在上篇博客中分析了hashmap的用法,详情查看java并发之hashmap 本篇博客重点分析下hashmap的源码(基于JDK1.8) 一.成员变量 HashMap有以下主要的成员变量 /** * ...
- ChsLLVMDocs
https://github.com/wuye9036/ChsLLVMDocs/blob/master/CodeGen.md
- Cesium热力图实现
转自原文 Cesium热力图实现 生成热力图的算法我是用的一个热力图插件 heatmap.js. heatmap中热力图生成原理: heatmap中首先会根据输入的渐进色参数,在内部生成一个0-2 ...
- mac os+selenium2+chrome驱动+python3
mac os 10.11.5 mac自带python2.7,自己下载了python3.5,pip list查看系统中的安装包,本人电脑中已经安装了pip和setuptools,若未安装,请先使用 su ...
- SilverLight:基础控件使用(1)
ylbtech-SilverLight-Basic-Control:基础控件使用(1) 本文详解控件有: Label, TextBox, PasswordBox, Image, Button , Ra ...
- CD_Lulu软件著作权中软件分类号
计算机软件著作权 登记中使用的软件分类编码指南 一.计算机软件著作权登记中使用的软件分类编码的结构采用组合代码结构,由9位数字组成并按照从左至右的顺序排列,前5位数字代表计算机软件分的代码:后4位数字 ...