【Kafka入门】Kafka入门第一篇:基础概念篇
Kafka简介
Kafka是一个消息系统服务框架,它以提交日志的形式存储消息,并且消息的存储是分布式的,为了提供并行性和容错保障,消息的存储是分区冗余形式存在的。
Kafka的架构
Kafka中包含以下几种专业术语:
1. topic:Kafka中以topic的形式来保存不同类别的消息
2. producer:Kafka中发布消息的称为producer
3. consumer:Kafka中订阅topic的进程称为consumer
4. broker:Kafka运行在由一个或多个服务(器)组成的集群上,每一个服务(器)称为一个broker。
具体的架构如下:
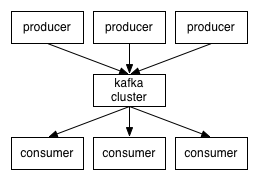
从架构图可以看出,producers通过网络将消息发布到Kafka上,然后消息以分区冗余的topic形式存储在分布式的Kafka服务集群上,最后consumers订阅不同的topic消息进行消费。其中客户端和服务器间是通过TCP协议进行通信。
topic(话题)
topic是已经发布的消息的一个分类名称,Kafka以分区(partition)日志的形式存储topic,也就是说,每个topic会被分成不同的partition,不同partition的关系如下:
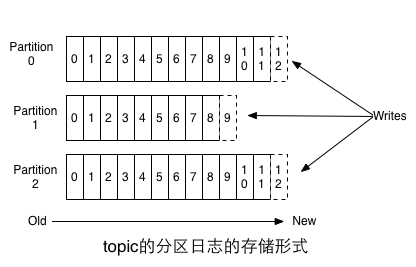
每个分区都是有序的不可变的消息序列,这些消息序列以追加形式写到提交日志上去。我们可以看到,在每个分区内,每条消息都被分配了一个下标号(offset),这些有序的下标号用以在不同partiton中唯一确定消息的位置。
消息在Kafka上的存储时间是可配置的,在配置时间范围内,消息是可以随时被消费,但是从消息发布时间开始计算,一旦配置的时间过了,为了腾出更多的空间,消息将会被丢弃。
topic的分布式存储和分布式的服务请求
producer(消息生产者)
consumer(消息消费者)
Kafka消息系统的几点保障
【Kafka入门】Kafka入门第一篇:基础概念篇的更多相关文章
- DNA拷贝数变异CNV检测——基础概念篇
DNA拷贝数变异CNV检测——基础概念篇 一.CNV 简介 拷贝数异常(copy number variations, CNVs)是属于基因组结构变异(structural variation), ...
- lua学习之基础概念篇
基础概念 程序块 (chunk) 定义 lua 中的每一个源代码文件或在交互模式(Cmd)中输入的一行代码都称之为程序块 一个程序块就是一连串语句或者命令 lua 中连续的语句不需要分隔符,但为了可读 ...
- (数据科学学习手札102)Python+Dash快速web应用开发——基础概念篇
本文示例代码与数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的新系列教程Python+Dash快 ...
- 函数响应式编程(FRP)从入门到”放弃”——基础概念篇
前言 研究ReactiveCocoa一段时间了,是时候总结一下学到的一些知识了. 一.函数响应式编程 说道函数响应式编程,就不得不提到函数式编程,它们俩到底有什么关系呢?今天我们就详细的解析一下他们的 ...
- 干货 | 自适应大邻域搜索(Adaptive Large Neighborhood Search)入门到精通超详细解析-概念篇
01 首先来区分几个概念 关于neighborhood serach,这里有好多种衍生和变种出来的胡里花俏的算法.大家在上网搜索的过程中可能看到什么Large Neighborhood Serach, ...
- 函数响应式编程(FRP)—基础概念篇
原文出处:http://ios.jobbole.com/86815/. 一函数响应式编程 说到函数响应式编程,就不得不提到函数式编程,他们俩有什么关系呢?今天我们就详细的解析一下他们的关系. 现在下面 ...
- Win32多线程编程(1) — 基础概念篇
内核对象的基本概念 Windows系统是非开源的,它提供给我们的接口是用户模式的,即User-Mode API.当我们调用某个API时,需要从用户模式切换到内核模式的I/O System Serv ...
- (一)github之基础概念篇
1.github: 一项为开发者提供git仓库的托管服务, 开发者间共享代码的场所.github上公开的软件源代码全都由git进行管理. 2.git: 开发者将源代码存入名为git仓库的资料库中,而g ...
- http协议之基础概念篇(1)
内容概述: 该篇主要内容概述 a.http相关术语解析 b.http的基本原理与工作流程 c.相关工具的使用(Wireshark) 作用介绍 绝大多数的web开发,都是构建在http协议之上的. HT ...
随机推荐
- 走进WCF一 (异常如此多娇,引无数码农竞折煞)
对于WCF一直都是只知其然,公司框架的架构者也只是对我们授之以鱼,而不授之以渔. 带着初学者的态度进入了大神Artech的博客,逐步慢慢上手. 我的解决方案(和大神的一模一样,只是过程中一波三折的) ...
- 笨方法学python 33课
今天Eiffel看到了第33章,任务是把一个while循环改成一个函数. 我在把while循环改成函数上很顺利,但是不知道怎么写python的主函数,在参数的调用上也出现了问题. 通过查资料,发现py ...
- twisted internet.reactor部分 源码分析
twisted.internet.reactor 是进行所有twisted事件循环的地方. reactor在1个python进程中只能有一个. 在windows下用的是select.linux下epo ...
- vim 分屏 screen
上下分割,并打开一个新的文件. :sp filename 左右分割当前打开的文件. Ctrl+W v 左右分割,并打开一个新的文件. :vsp filename 移动光标 Vi中的光标键是h, j, ...
- 1013: [JSOI2008]球形空间产生器sphere
很直观的一个gauss题: 用的是以前用过的一个模板: #include<cstdio> #include<algorithm> #include<cmath> # ...
- linux下查看文件编码及修改编码
http://blog.csdn.net/jnbbwyth/article/details/6991425 查看文件编码在Linux中查看文件编码可以通过以下几种方式:1.在Vim中可以直接查看文件编 ...
- RTMP
实时消息传输协议 RTMP(Real Time Messaging Protocol) http://blog.csdn.net/defonds/article/details/17403225 译序 ...
- UNICODE并没有提供对诸如Braille, Cherokee, Ethiopic, Khmer, Mongolian, Hmong, Tai Lu, Tai Mau文字的支持
UNICODE支持欧洲.非洲.中东.亚洲(包括统一标准的东亚象形汉字和韩国象形文字).但是,UNICODE并没有提供对诸如Braille, Cherokee, Ethiopic, Khmer, Mon ...
- APP-PER-50022: Oracle Human Resources could not retrieve a value for the User Type profile option.
Symptoms ----------------------- AP > Setup > Organizations Show Error tips: APP-PER-50022: Or ...
- AOP 实现的原理简析
AOP简介 AOP为Aspect Oriented Programming的缩写,意为:面向切面编程(也叫面向方面),可以通过预编译方式和运行期动态代理实现在不修改源代码的情况下给程序动态统一添加功能 ...