下一代hadoop
1,hadoop 2.0 产生背景
2,hadoop 2.0 基本构成
3,HDFS 2.0
4 YARN
5 MapReduce On YARN
6 Hadoop 2.0初体验
7 总结 1,hadoop 2.0产生背景:
两个概念:
hadoop生态系统:由hadoop,hbase,hive,pig,sqoop,flume,mahout,zookeeper等构成。
hadoop:hadoop只是hadoop生态系统的一个组成部分,由分布式文件系统hdfs和分布式计算框架MapReduce组成。hadoop2.0由hdfs,yarn,mr组成
通俗的hadoop是指hadoop生态系统。
hdfs存在的问题:
NameNode单点故障,难以应用于在线场景(不能提供“服务”这样的长期在线,程序一旦挂掉没有备用方案)
NameNode压力过大(所有通信都通过namenode转向其他服务),且内存受限(元数据信息),影响系统扩展性(内存小,hdfs就不能随意加datanode)。
MapReduce存在的问题:
JobTracker单点故障
JobTracker访问压力大,影响系统扩展性
难以支持除Mapreduce之外的计算框架,比如Spark,Storm,Tez(资源调度,和计算在一起的架构不好)等 2 hadoop 2.0基本构成
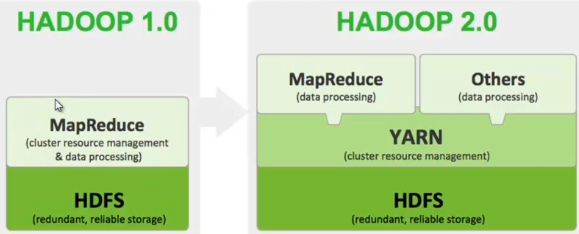
注解1:MapReduce同时负责资源管理和任务调度,hadoop 2.0将资源管理独立出来成为yarn,mr2.0仅仅是运行在yarn上的框架之一。
Hadoop 2.0由HDFS,Mapreduce和Yarn三个分支构成;
HDFS:NN Federation(分目录管理),HA(多个NameNode)
Mapreduce:运行在yarn上的mr
yarn:资源管理器。 下载地址:http://hadoop.apache.org/releases.html
svn:http://svn.apache.org/repos/asf/hadoop/common/branches/ 这里只有源代码,需编译才可使用 3 HDFS2.0 解决单点故障
通过主备NameNode解决
如果主NameNode发生故障,则切换到备NameNode上。 解决内存受限问题,(含并发过大)
水平扩展,支持多个NameNode
每个NameNode分管一部分目录;(每个namenode管理的文件数减少)
所有NameNode共享所有DataNode存储资源 4 Yarn
Yet Another Resource Negotiator
核心思想:将mrv1中JobTracker的资源管理和任务调度两个功能分开。分别由ResourceManager和ApplicationMaster进程实现。
ResourceManager:负责整个集群的资源管理和调度
ApplicationMaster:负责应用程序相关的事务,比如任务调度,任务监控和容错 Yarn的引入,使得多个计算框架可运行在一个集群中;
:每个应用程序对应一个ApplicationMaster
:目前多个计算框架可以运行在yarn上,比如Mapreduce,spark,storm等 5 Mapreduce on yarn(mrv2)
将Mapreduce作业直接运行在yarn上,而不是由JobTracker和TaskTracker构建在MRv1系统中; 基本功能模块:
yarn:负责资源管理和调度
MRAppMaster:负责任务切分,任务调度,任务监控和容错等
MapTask/ReduceTask:任务驱动引擎,与MRv1一致
每个应用程序对应一个MRAppMaster
单个应用程序运行失败,不会影响其他应用程序。
负责应用程序相关的事情,包括将yarn分配的资源二次分配给内部的任务,任务切分,监控容错等。 HDSF 2.0 HA 架构图
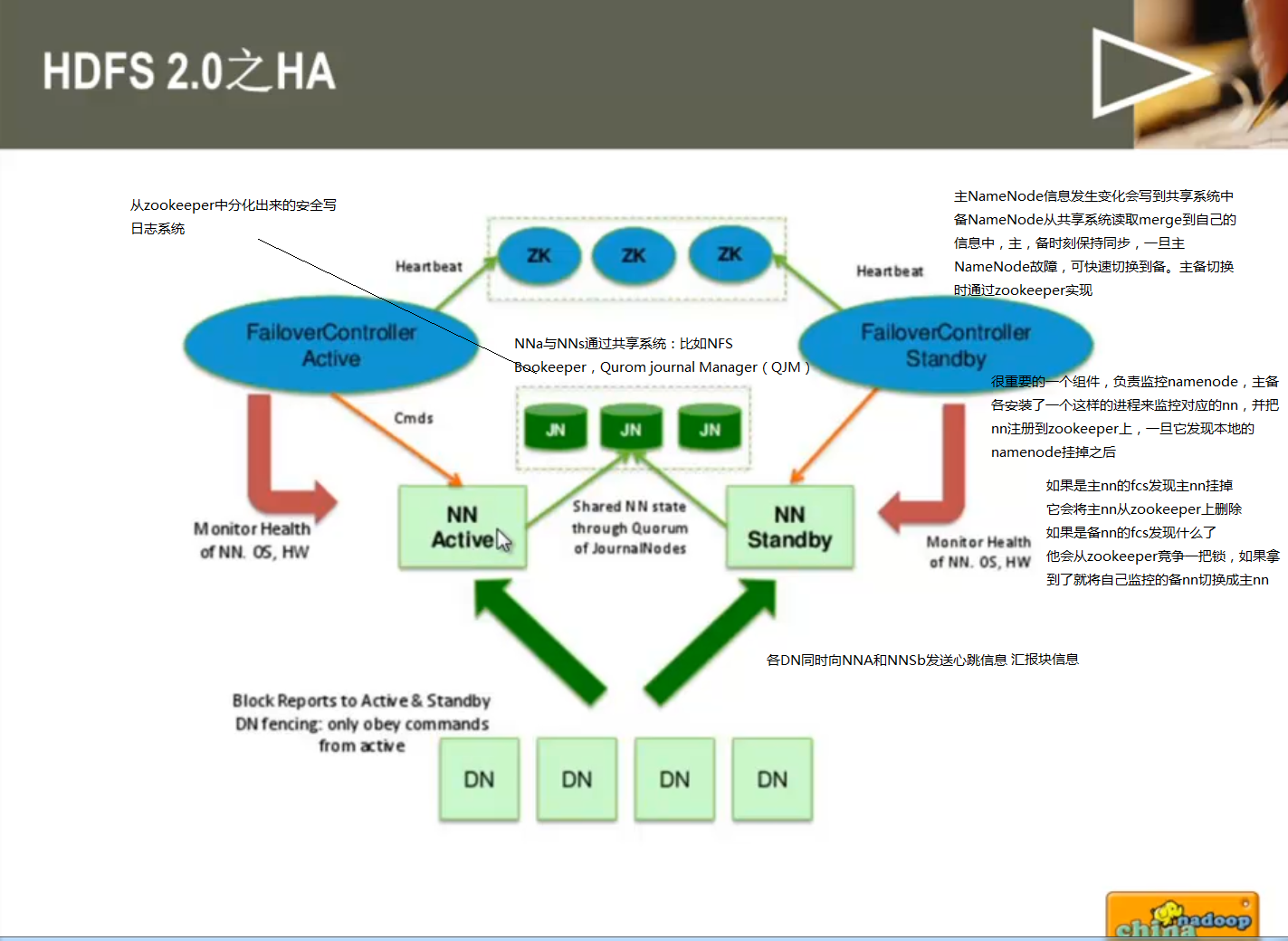
详细解释hdfs 2.0 -ha
1 主备namenode
主namenode对外提供服务,备namenode同步主nn元数据,以待切换
所有datanode同时向两个namenode汇报数据块信息
2 两种切换选择
手动切换:通过命令实现主备之间的切换,可以用于hdfs(namenode升级)升级等场合
自动切换:基于zookeeper实现 (降低运维成本)
3 基于zookeeper切换方案:
zookeeper failover controller(简称zkfc,以后会经常遇到):监控namenode健康状态,并向zookeeper注册namenode
namenode挂掉后,zkfc为namenode竞争锁(竞争锁,zookeeper用语),获得zkfc锁的namenode变为active 多种共享存储系统可供选择:
NFS
奇数个JournalNode构成集群
Bookeeper(这个跟Journal差不多) 推荐Journal Node方案:
基本原理,数据同时写入所有JournalNode,多数写入成功,则认为写成功
一般配置奇数个JournalNode,越多,容错性越好
比如3个JournalNode,只要两个写成功,则数据写成功,最多允许一个JournalNode挂掉。如果是7台电脑,最多允许3台挂掉
下一代hadoop的更多相关文章
- [BigData - Hadoop - YARN] YARN:下一代 Hadoop 计算平台
Apache Hadoop 是最流行的大数据处理工具之一.它多年来被许多公司成功部署在生产中.尽管 Hadoop 被视为可靠的.可扩展的.富有成本效益的解决方案,但大型开发人员社区仍在不断改进它.最终 ...
- hadoop生态圈介绍
原文地址:大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用户可以在不了解分 ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- Hadoop版本变迁
内容来自<Hadoop技术内幕:深入解析YARN架构设计与实现原理>第2章:http://book.51cto.com/art/201312/422022.htm Hadoop版本变迁 当 ...
- Hadoop 概述
Hadoop 是 Apache 基金会下的一个开源分布式计算平台,以 HDFS 分布式文件系统 和 MapReduce 分布式计算框架为核心,为用户提供底层细节透明的分布式基础设施.目前,Hadoop ...
- Hadoop发行版本介绍
前言 从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘.开源界及厂商,所有数据软件,无一不向Hadoop靠拢.Hadoop也从小众的高富帅领域 ...
- Hadoop、Pig、Hive、Storm、NOSQL 学习资源收集
(一)hadoop 相关安装部署 1.hadoop在windows cygwin下的部署: http://lib.open-open.com/view/1333428291655 http://blo ...
- about云资源汇总指引V1.4:包括hadoop,openstack,nosql,虚拟化
hadoop资料 云端云计算2G基础课程 (Hadoop简介.安装与范例) 炼数成金3G视频分享下载 虚拟机三种网络模式该如何上网指导此为视频 Hadoop传智播客七天hadoop(3800元)视频, ...
- 【原创 Hadoop&Spark 动手实践 4】Hadoop2.7.3 YARN原理与动手实践
简介 Apache Hadoop 2.0 包含 YARN,它将资源管理和处理组件分开.基于 YARN 的架构不受 MapReduce 约束.本文将介绍 YARN,以及它相对于 Hadoop 中以前的分 ...
随机推荐
- requireJS(二)
一.前言 requireJS(一) 本篇主要整理requirejs的一些用法,相对比较零散. 实例目录 二.优化 requirejs建议我们给每一个模块书写一个js文件.但是这样会增加网站的http请 ...
- android的消息处理机制(图+源码分析)——Looper,Handler,Message
android源码中包含了大量的设计模式,除此以外,android sdk还精心为我们设计了各种helper类,对于和我一样渴望水平得到进阶的人来说,都太值得一读了.这不,前几天为了了解android ...
- 【原】个人对win7开机黑屏只有鼠标排障总结
个人对win7开机黑屏只有鼠标排障总结 文:铁乐猫 第一种情况是explorer.exe进程丢失或损坏有关: 判断方法是按Ctrl+Alt+Del键能呼出任务管理器,结束explorer.exe进程, ...
- String类比较,String类运算比较,String运算
String类比较,String类运算比较 >>>>>>>>>>>>>>>>>>>&g ...
- php跨服务器信息获取之cURL
原文地址:php跨服务器信息获取之cURL作者:陌上花开 其实有几种方式 $content = file_get_contents("http://www.nettuts.com" ...
- JQuery判断子Iframe 加载完成的技术解决
当需要我们给当前页面动态创建Iframe子框架的时候,并且同时需要操作子Iframe里的方法的时候,我们发现无法成功实现.这是为什么呢?经小程总结,发现子Iframe还没有来的及加载完成,就去执行里面 ...
- android Activity 生命周期
今天第一次详细学习android,主要了解了一下activity的生命周期,下面详细说一下自己的简介: 在Actity中最主要的有一下几个方法: protectedvoid onCreate(Bund ...
- wordpress 后台显示空白现象
简单的说两句,出现此种现象的因素可能在于主题或者插件再或者是因为(恶意)插件(误更改)更改了某个重要的文件出现错误.本次我遇到的是插件的错误,具体是什么错误,我也没有去深究,重要的是结果! 使用排查的 ...
- 不知道的陷阱:C#委托和事件的困惑
转载网址:http://www.cnblogs.com/buptzym/archive/2013/03/15/2962300.html 不知道的陷阱:C#委托和事件的困惑 一. 问题引入 通常,一 ...
- hdoj 2054(A==B)
注意考虑以下数据: 123 123.0; 0.123 .123; 00.123 0.123; 代码: #include<iostream>#include<cstdio> ...