【大数据课程】高途课程实践-Day01:Python编写Map Reduce函数实现各商品销售量展示(类似wordcount)
〇、概述
1、工具
http://www.dooccn.com/python3/
在线运行Python代码
2、步骤
(1)⽣成代码测试数据
(2)编写Mapper逻辑
(3)编写Reducer逻辑
(4)提交并执行
一、⽣成代码测试数据
运行代码,输出50个人,分别购买3种商品的数据
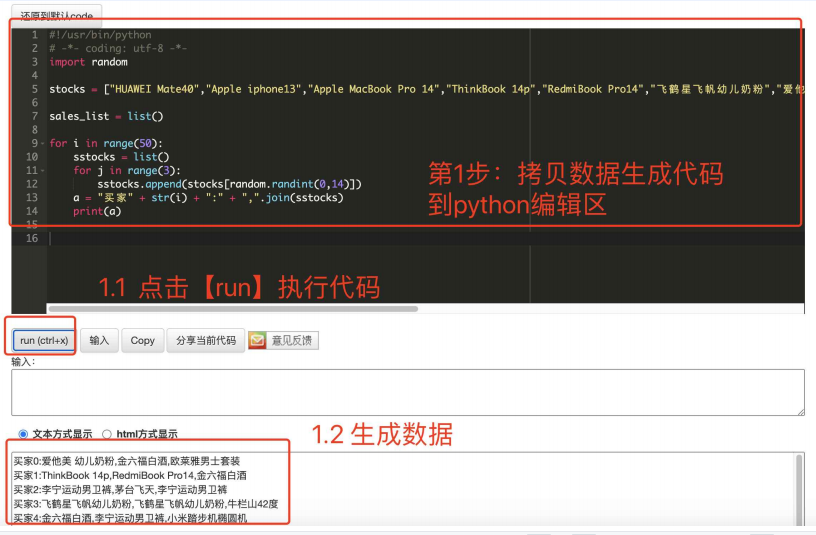
代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import random stocks = ["HUAWEI Mate40","Apple iphone13","Apple MacBook Pro 14","ThinkBook 14p","RedmiBook Pro14","飞鹤星飞帆幼儿奶粉","爱他美 幼儿奶粉","李宁运动男卫裤","小米踏步机椭圆机","欧莱雅面膜","御泥坊面膜","欧莱雅男士套装","金六福白酒","牛栏山42度","茅台飞天"] sales_list = list() for i in range(50):
sstocks = list()
for j in range(3):
sstocks.append(stocks[random.randint(0,14)])
a = "买家" + str(i) + ":" + ",".join(sstocks)
print(a)
二、编写Mapper逻辑
拷⻉第1步1.2 ⽣成的数据到输⼊框中,然后参考mapper.py代码进⾏编辑程序
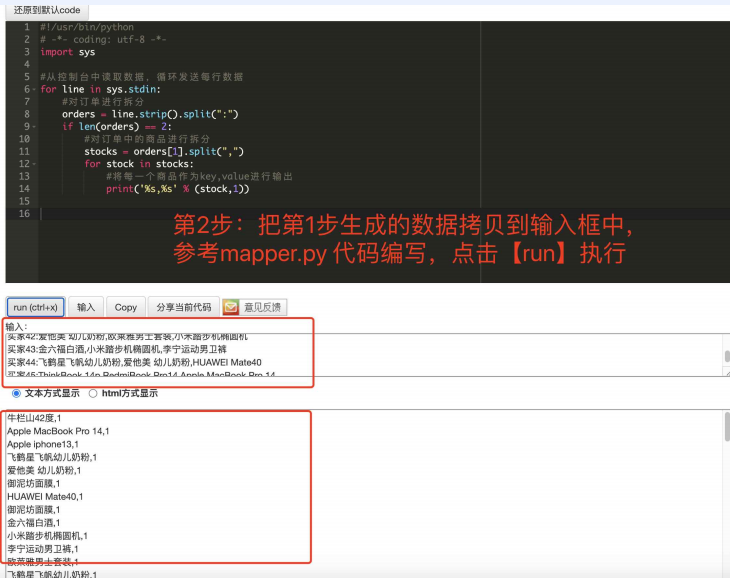
代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys #从控制台中读取数据,循环发送每行数据
for line in sys.stdin:
#对订单进行拆分
orders = line.strip().split(":")
if len(orders) == 2:
#对订单中的商品进行拆分
stocks = orders[1].split(",")
for stock in stocks:
#将每一个商品作为key,value进行输出
print('%s,%s' % (stock,1))
三、编写Reducer逻辑
拷⻉第2步⽣成的数据到输⼊框中,然后参考reducer.py代码进⾏编辑程序
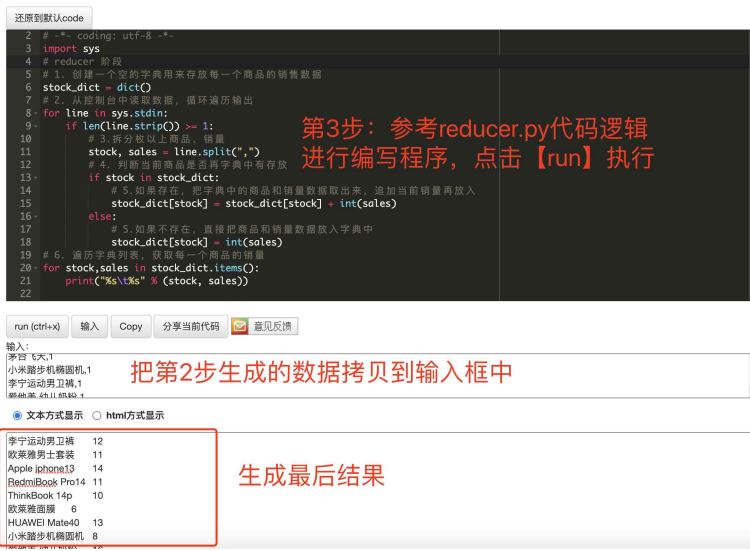
代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys # 创建一个空的字典用来每一个商品的销售数据
stock_dict = dict() for line in sys.stdin:
if len(line.strip()) >= 1:
# 拆分每一行的商品,销量
stock, sales = line.split(',')
# 判断当前商品是否在字典中有存放
if stock in stock_dict:
# 如果有,把字典中的商品和销量取出来,追加当前销量再放入
stock_dict[stock] = stock_dict[stock] + int(sales)
else:
# 如果没有,直接把商品和销量数据放入字典中
stock_dict[stock] = int(sales) # 遍历字典列表,获取每一个商品的销量
for stock, sales in stock_dict.items():
print('%s\t%s' % (stock, sales))
最终结果:各个商品的购买次数
四、提交并执行
# hadoop jar 使用hadoop命令调用jar资源
# 运行streaming程序所在的资源位置(路径)
hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar
-file mapper.py # 表示mapper程序所在位置
-mapper "python mapper.py" # 表示将要调用的map执行程序脚本
-file reduce.py # 表示reducer程序所在位置
-reducer "python reducer.py" # 表示将要调用的reduce执行程序脚本
-input /input/data # 数据的输入目录
-output /output # 数据的输出目录
【大数据课程】高途课程实践-Day01:Python编写Map Reduce函数实现各商品销售量展示(类似wordcount)的更多相关文章
- MySQL在大数据、高并发场景下的SQL语句优化和"最佳实践"
本文主要针对中小型应用或网站,重点探讨日常程序开发中SQL语句的优化问题,所谓“大数据”.“高并发”仅针对中小型应用而言,专业的数据库运维大神请无视.以下实践为个人在实际开发工作中,针对相对“大数据” ...
- WOT干货大放送:大数据架构发展趋势及探索实践分享
WOT大数据处理技术分会场,PingCAP CTO黄东旭.易观智库CTO郭炜.Mob开发者服务平台技术副总监林荣波.宜信技术研发中心高级架构师王东及商助科技(99Click)顾问总监郑泉五位讲师, ...
- 大数据量高并发的数据库优化详解(MSSQL)
转载自:http://www.jb51.net/article/71041.htm 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能. ...
- 网易大数据平台的Spark技术实践
网易大数据平台的Spark技术实践 作者 王健宗 网易的实时计算需求 对于大多数的大数据而言,实时性是其所应具备的重要属性,信息的到达和获取应满足实时性的要求,而信息的价值需在其到达那刻展现才能利益最 ...
- (数据科学学习手札80)用Python编写小工具下载OSM路网数据
本文对应脚本已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们平时在数据可视化或空间数据分析的过程中经常会 ...
- 王家林的81门一站式云计算分布式大数据&移动互联网解决方案课程第14门课程:Android软硬整合设计与框架揭秘: HAL&Framework &Native Service &App&HTML5架构设计与实战开发
掌握Android从底层开发到框架整合技术到上层App开发及HTML5的全部技术: 一次彻底的Android架构.思想和实战技术的洗礼: 彻底掌握Andorid HAL.Android Runtime ...
- IT大数据服务管理高级课程(IT服务,大数据,云计算,智能城市)
个人简历 金石先生是马克思主义中国化的研究学者,上海财经大学经济学和管理学硕士,中国民主建国会成员,中国特色社会主义人文科技管理哲学的理论奠基人之一.金石先生博学多才,对问题有独到见解.专于工作且乐于 ...
- 大数据系列修炼-Scala课程01
简介 由于本人刚毕业,也是从事软件开发相关的工作.想再学习一下关于大数据.移动互联网.云计算相关的技术.为我的未来打好基础.并且从零开始学习大数据相关的知识,脚踏实地的走好每一步,听行业前辈说毕业生刚 ...
- 大数据系列修炼-Scala课程03
前言 今天上班看了很多关于前端js,jQuery.bootstrap.js以及springMVC看得迷迷糊糊的,毕竟以前很少去学习前端的技术,所有看得有点困,还好看得比较多,回家后也开始学习关于Sca ...
- 大数据系列修炼-Scala课程07
由于昨天下班后有点困,就没有来及写博客,今天会把它补上!把这个习惯坚持下去! 关于Scala高阶函数详解 1.Scala高阶函数代码实现:高阶函数就是在我们函数中套用函数 2.高阶函数代码详解:高阶函 ...
随机推荐
- Shell 脚本实践指南
代码风格规范 开头有"蛇棒" 所谓shebang其实就是在很多脚本的第一行出现的以#!开头的注释,他指明了当我们没有指定解释器的时候默认的解释器,一般可能是下面这样: #!/bin ...
- Solutions:Elastic SIEM - 适用于家庭和企业的安全防护 ( 三)
- 利用 Nginx 反向代理搭建本地 yum 服务器
在政府,医院等单位有网络安全要求,对内外网进行物理隔离,然而内网主机无法访问互联网下载安装包,通过Nginx 反向代理搭建本地yum服务器实现内网主机安装包下载. Centos 8.2 部署 Ngin ...
- python及第三方库交叉编译
一.前言: 网上关于python的交叉编译的文章很多,但是关于python第三库的交叉编译的文章就比较少了,而且很多标题是第三方库的交叉编译,但是实际上用到的都是不需要交叉编译就能用的库,可参考性不强 ...
- Morris 遍历实现二叉树的遍历
Morris 遍历实现二叉树的遍历 作者:Grey 原文地址: 博客园:Morris 遍历实现二叉树的遍历 CSDN:Morris 遍历实现二叉树的遍历 说明 Morris 遍历可以实现二叉树的先,中 ...
- 驱动开发:内核枚举DpcTimer定时器
在笔者上一篇文章<驱动开发:内核枚举IoTimer定时器>中我们通过IoInitializeTimer这个API函数为跳板,向下扫描特征码获取到了IopTimerQueueHead也就是I ...
- 16.MongoDB系列之分片管理
1. 查看当前状态 1.1 查看配置信息 mongos> use config // 查看分片 mongos> db.shards.find() { "_id" : & ...
- python和C语言从路径中获取文件名
1.Python import os file_name = os.path.basename(filepath)#带后缀的文件名(不含路径) file_name_NoExtension = os.p ...
- 聊聊mysql的事务
今天来聊聊事务的四大特性以及其实现原理,需结合之前写的mysql是如何实现mvcc的来理解,因为大多数的实现都是基于mvcc的,理论介绍完后会通过实例来演示mvcc又是如何实现这些隔离级别的 事务的四 ...
- java学习之EL和JSTL
0x00前言 EL和JSTL都是JSP的内容的拓展,都是开发的一些东西,稍微学习记录一下,避免以后忘记 0x01EL 0x1基本用法 概念:Expression language 表达式语言 作用:替 ...