python之re模块补充和其他模块(collection、time、queue、datetime、random)
re模块补充说明
在正则表达式中,'()'的作用是进行分组,但是在re模块中,正则表达式中的'()'代表着其他的意思。

1、在findall()方法中,匹配到值会优先返回括号内的值
import re
res = re.findall('a(b)c', 'abc|a1bc|d|abc|2')
print(res) # 输出:['b', 'b']
"""匹配时先忽略括号,有结果时返回括号内的值"""
# 如果有多个括号
res = re.findall('(a)(b)c', 'abc|a1bc|d|abc|2')
print(res) # 输出:[('a', 'b'), ('a', 'b')]
"""匹配时先忽略括号,有结果时把括号内的值组成元组存到列表中"""
# 如果想让'()'表示在正则表达式中的意义,可以在括号里加'?:'
res = re.findall('a(?:b)c', 'abc|a1bc|d|abc|2')
print(res) # 输出:['abc', 'abc']
2、在search()方法中,具有分组的功能
import re
res = re.search('a(b)c', 'abc|a1bc|d|abc|2')
print(res) # <_sre.SRE_Match object; span=(0, 3), match='abc'>
print(res.group()) # 输出:abc
print(res.group(0)) # 0是默认值,输出内容与不加参数一致
print(res.group(1)) # 输出:b
"""可以给group()添加参数输出括号的值,但是参数不能超过括号的个数"""
# 如果有多个括号
res = re.search('(a)(b)(c)', 'abc|a1bc|d|abc|2')
print(res.group(1)) # 输出:a
print(res.group(2)) # 输出:b
print(res.group(3)) # 输出:c
print(res.group(4)) # 报错,超出括号分组的个数了
"""可以给group()添加参数按顺序输出"""
# 分组后可以给每个组起别名
res = re.search('(?P<name1>a)(?P<name2>b)c', 'abc|a1bc|d|abc|2')
print(res.group('name1')) # 输出:a
print(res.group('name2')) # 输出:b
"""?P<别名>放在括号中,<>内的名称就是别名"""
# 如果想让'()'表示在正则表达式中的意义,可以在括号里加'?:'
res = re.search('a(?:b)c', 'abc|a1bc|d|abc|2')
print(res.group(1)) # 报错,没有分组的内容
3、括号在match()、search()、finditer()中用法相同
4、括号在findall()、compile()中用法相同
collections模块
除了基本数据类型外,collections模块提供了额外的数据类型。
1、namedtuple(),生成一个可以从名字访问值的元组
from collections import namedtuple
# 生成一个叫做"坐标"的元组,传列表类型表示把列表中的值当作元组的key
point = namedtuple('坐标', ['x', 'y'])
# 传值要与列表元素个数对应
p1 = point(1, 2)
p2 = point(5, 6)
print(p1, p2) # 输出:坐标(x=1, y=2) 坐标(x=5, y=6)
# 按照名字来取值
print(p1.x) # 输出:1
print(p2.y) # 输出:6
# 也可以传字符串类型,每个key用空格隔开
person = namedtuple('人物', '姓名 age')
p1 = person('jason', 18)
p2 = person('kevin', 28)
print(p1, p2) # 输出:人物(姓名='jason', age=18) 人物(姓名='kevin', age=28)
print(p1.姓名, p1.age) # 输出:jason 18
2、deque(),双端队列,首尾都可以进出数据
from collections import deque
q = deque([1, 2, 3])
print(q) # 输出:deque([1, 2, 3])
q.append(4) # 默认从尾部添加数据
print(q) # 输出:deque([1, 2, 3, 4])
q.appendleft(0) # 从首部添加数据
print(q) # 输出:deque([0, 1, 2, 3, 4])
q.pop() # 默认从尾部弹出数据
print(q) # 输出:deque([0, 1, 2, 3])
q.popleft() # 从首部弹出数据
print(q) # 输出:deque([1, 2, 3])
3、OrderedDict(),生成一个有序字典
# 基本数据类型的字典是无序的
d1 = dict([('a', 1), ('b', 2), ('c', 3)])
d2 = dict([('b', 2), ('c', 3), ('a', 1)])
print(d1 == d2) # 输出:True
# 生成有序字典
from collections import OrderedDict
od1 = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
od2 = OrderedDict([('b', 2), ('c', 3), ('a', 1)])
print(od1 == od2) # 输出:False
"""
有序字典的方法与普通的字典类型相同
注意:给有序字典添加键值对是按顺序添加的
"""
4、defaultdict(),给字典的值设置一个默认值
from collections import defaultdict
# 设置默认值为列表类型
my_dict = defaultdict(list)
# 给列表添加值
my_dict['k1'].append('aaa')
# 不传值默认生成空列表
my_dict['k2']
print(my_dict) # 输出:defaultdict(<class 'list'>, {'k1': ['aaa'], 'k2': []})
print(my_dict['k2']) # 输出:[]
5、Counter(),统计所有字符出现的次数,返回的值可以当字典使用
from collections import Counter
res1 = 'asdbnbasdbanba'
r1 = Counter(res1)
print(r1) # 输出:Counter({'a': 4, 'b': 4, 's': 2, 'd': 2, 'n': 2})
print(r1.get('a')) # 输出:4
res2 = ['a', 45, 'qq', 2, 2, 'a']
r2 = Counter(res2)
print(r2) # 输出:Counter({'a': 2, 2: 2, 45: 1, 'qq': 1})

queue模块
简单讲解,生成队列
import queue
q = queue.Queue(3) # 最大只能放三个元素
# 存放元素
q.put(11)
q.put(22)
q.put(33)
"""此时队列满了,继续添加会原地等待,直到队列空出位置"""
# 获取元素
print(q.get()) # 输出:11
print(q.get()) # 输出:22
print(q.get()) # 输出:33
"""此时队列空了,继续获取会原地等待,直到队列有数据"""
time模块
和时间有关系的计算我们就要用到这个模块。

常用方法(sleep()、time())
import time
time.sleep(10) # 括号内为程序停止时间,单位为秒
time.time() # 获取当前时间戳
time模块有三种表示时间的格式:时间戳、结构化时间、格式化时间。
时间戳:
距离1970年1月1日0时0分0秒至此相差的秒数,使用time.time()可以获取时间戳。
结构化时间:
结构化时间中有9个元素,分别有着不同的意义,使用time.localtime()可以获取结构化时间。
import time
t = time.localtime()
print(t)
# 输出:time.struct_time(tm_year=2022, tm_mon=3, tm_mday=29, tm_hour=16, tm_min=43, tm_sec=12, tm_wday=1, tm_yday=88, tm_isdst=0)
索引 属性 值 0 tm_year(年) 比如2011 1 tm_mon(月) 1 - 12 2 tm_mday(日) 1 - 31 3 tm_hour(时) 0 - 23 4 tm_min(分) 0 - 59 5 tm_sec(秒) 0 - 60 6 tm_wday(星期) 0 - 6(0表示周一) 7 tm_yday(一年中的第几天) 1 - 366 8 tm_isdst(是否是夏令时) 默认为0 格式化时间:
我们可以最直观看懂的时间格式,使用time.strftime()可以获取格式化时间。
import time
t = time.strftime("%Y-%m-%d %X")
print(t) # 输出:2022-03-29 16:45:37
特殊符号表
符号 意义 %y 两位数的年份表示(00 - 99) %Y 四位数的年份表示(000 - 9999) %m 月份(01 - 12) %d 月内中的一天(0 - 31) %H 24小时制小时数(0 - 23) %I 12小时制小时数(01 - 12) %M 分钟数(00 - 59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001 - 366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身 只需要记住常用的即可。
时间格式的转换
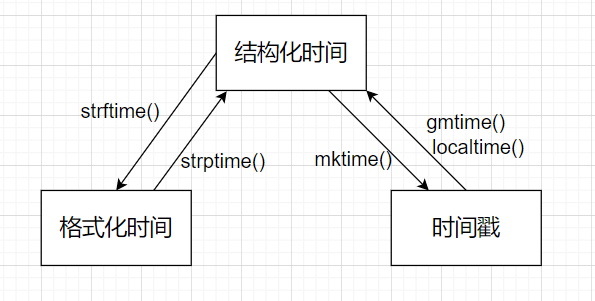
时间戳<==>结构化时间
# 时间戳-->结构化时间
time.gmtime(时间戳) # 返回结构化时间
time.localtime(时间戳) # 返回结构化时间
"""上述的方法返回的结构化时间是UTC时间"""
# 结构化时间-->时间戳
time.mktime(结构化时间) # 返回时间戳
格式化时间<==>结构化时间
# 结构化时间-->格式化时间
time.strftime(格式定义,结构化时间) # 结构化时间参数若不传,则显示当前时间
# 格式化时间-->结构化时间
time.strptime(格式化时间,对应的格式)
datetime模块
导入模块
import datetime
获取当前年月日
dt = datetime.date.today()
print(dt) # 输出:2022-03-29
# 获取年份
print(dt.year) # 输出:2022
# 获取月份
print(dt.month) # 输出:3
# 获取天数
print(dt.day) # 输出:29
# 获取星期(0-6),星期一开始
print(dt.weekday()) # 输出:1
# 获取星期(1-7),星期一开始
print(dt.isoweekday()) # 输出:2
获取当前年月日,时分秒
dt = datetime.datetime.today()
# 或者
dt = datetime.datetime.now()
print(dt) # 输出:2022-03-29 17:25:12.431065
# 获取年份
print(dt.year) # 输出:2022
# 获取月份
print(dt.month) # 输出:3
# 获取天数
print(dt.day) # 输出:29
# 获取时
print(dt.hour) # 输出:17
# 获取分
print(dt.minutes) # 输出:25
# 获取秒
print(dt.second) # 输出:12
# 获取星期(0-6),星期一开始
print(dt.weekday()) # 输出:1
# 获取星期(1-7),星期一开始
print(dt.isoweekday()) # 输出:2
时间差timedelta()
# 获取当前时间
date_time = datetime.datetime.today()
print(date_time) # 输出:2022-03-29 17:34:11.180282
# 括号内可以是多种时间选项,这里是四天的意思,hour=3代表3小时等等...
time_delta = datetime.timedelta(days=4)
print(date_time + time_delta) # 输出:2022-04-02 17:34:11.180282
自定义datetime()
dt = datetime.datetime(2001, 7, 28, 12, 12)
print(dt) # 输出:2001-07-28 12:12:00
datetime()也可以转成格式化时间,转换方法与结构化转格式化时间相同。
random模块
random模块讲究的就是一个随机。
导入模块
import random
产生[0,1)的随机小数
print(random.random())
产生[2.3,3.5)的随机小数
print(random.uniform(2.3,3.5))
产生[2,10]的随机整数
print(random.randint(2,10))
随机打乱数据集
l = [1, 2, 3, 4, 5]
random.shuffle(l)
print(l)
从数据集随机选择一个
l = [1, 2, 3, 4, 5]
print(random.choice(l))
随机指定个数抽样
l = [1, 2, 3, 4, 5]
# 从l中随机取2个
print(random.sample(l, 2))
小练习
使用random模块编写一个能够产生随机验证码的代码
点击查看代码
import random
# 定义空列表
l_all = []
# 把A-Z添加到空列表中
l_all.extend([chr(i) for i in range(65, 91)])
# 把a-z添加到列表中
l_all.extend([chr(i) for i in range(97, 123)])
# 把0-9转为字符串类型添加到列表中
l_all.extend([str(i) for i in range(0, 10)])
def get_random(num):
# 打乱列表,更随机
random.shuffle(l_all)
# 定义返回值为空字符串
res = ''
for i in range(num):
# 随机从列表中那一个添加到字符串中
res += random.choice(l_all)
return res
print(get_random(5))

python之re模块补充和其他模块(collection、time、queue、datetime、random)的更多相关文章
- python day 8: re模块补充,导入模块,hashlib模块,字符串格式化,模块知识拾遗,requests模块初识
目录 python day 8 1. re模块补充 2. import模块导入 3. os模块 4. hashlib模块 5. 字符串格式:百分号法与format方法 6. 模块知识拾遗 7. req ...
- os模块补充以及序列化模块
os模块补充以及序列化模块 一.os模块的补充 1.os.path.abspath 能把存在的相对路径的绝对路径显示出来 path = os.path.abspath("连达day19. ...
- re模块补充与其他模块介绍
注:昨日写了re单个模块几个重要的点需要补充 一.re模块补充 1.findall独有的优先级别展示 res = re.findall('abc', 'abcabcabcabc') print(res ...
- 文成小盆友python-num7 -常用模块补充 ,python 牛逼的面相对象
本篇内容: 常用模块的补充 python面相对象 一.常用模块补充 1.configparser模块 configparser 用于处理特定格式的文件,起内部是调用open()来实现的,他的使用场景是 ...
- python模块补充
一.模块补充 configparser 1.基本的读取配置文件 -read(filename) 直接读取ini文件内容 -sections() 得到所有的section,并以列表的形式返回 -opti ...
- Python全栈开发之7、模块和几种常见模块以及format知识补充
一.模块的分类 Python流行的一个原因就是因为它的第三方模块数量巨大,我们编写代码不必从零开始重新造轮子,许多要用的功能都已经写好封装成库了,我们只要直接调用即可,模块分为内建模块.自定义的模块. ...
- Python开发【第七篇】: 面向对象和模块补充
内容概要 特殊成员 反射 configparser模块 hashlib模块 logging模块 异常处理 模块 包 1. 特殊成员 什么是特殊成员呢? __init_()就是个特殊的成员. 带双下划线 ...
- python面向编程: 常用模块补充与面向对象
一.常用模块 1.模块 的用用法 模块的相互导入 绝对导入 从sys.path (项目根目录)开始的完整路径 相对导入 是指相对于当前正在执行的文件开始的路径 只能用于包内模块相互间导入 不能超过顶层 ...
- python【第五篇】常用模块学习
一.主要内容 模块介绍 time &datetime模块 random os sys shutil json & pickle shelve xml处理 yaml处理 configpa ...
随机推荐
- CSS入门指南-4:页面布局
这是<CSS设计指南>的读书笔记,用于加深学习效果. display 属性 display是 CSS 中最重要的用于控制布局的属性.每个元素都有一个默认的 display 值.对于大多数元 ...
- python爬虫---虎牙直播封面采集
代码: import requests from lxml import etree # html解析库 source = requests.get("https://www.huya.co ...
- 【uniapp 开发】uni-app 资源在线升级/热更新
注:本文为前端代码资源热更新.如果是整包升级,另见文档 https://ask.dcloud.net.cn/article/34972 HBuilderX 1.6.5 起,uni-app 支持生成 A ...
- 判断链表是否有环(Java实现)
判断给定的链表中是否有环.如果有环则返回true,否则返回false. 解题思路:设置两个指针,slow和fast,fast每次走两步,slow每次走一步,如果有环的话fast一定会追上slow,判断 ...
- add jars、add external jars、add library、add class folder的区别
add external jars = 增加工程外部的包add jars = 增加工程内包add library = 增加一个库add class folder = 增加一个类文件夹add jar是表 ...
- MySQL 中的 SQL 语句详解
@ 目录 总结内容 1. 基本概念 2. SQL列的常用类型 3. DDL简单操作 3.1 数据库操作 3.2 表操作 4. DML操作 4.1 修改操作(UPDATE SET) 4.2 插入操作(I ...
- 将对象push到数组中组成对象数组
let items = { key:'', value:'' } for(let i = 0;i<len;i++){ items.value = _this.ills[i].sName; ite ...
- uni-app 解析后台接口返回的HTML
正常使用rich-text是可以解决问题的,但是在支付宝小程序中不显示,在文档中看到" 支付宝小程序 nodes 属性只支持使用 Array 类型.如果需要支持 HTML String,则需 ...
- nacos集群模式搭建踩坑记录
首先数据库使用的本地的mysql 1.看日志提示no set datasource,使用虚拟机ping本地后发现无法ping通,原因是本地没有关闭防火墙. 2.看日志提示不允许建立数据库连接,原因是r ...
- 在UnityUI中绘制线状统计图2.0
##在之前的基础上添加横纵坐标 上一期在这里:https://www.cnblogs.com/AlphaIcarus/p/16123434.html 先分别创建横纵坐标点的模板,将这两个Text放在G ...