redis的zset数据结构:跳表
点赞再看,养成习惯,微信搜索「小大白日志」关注这个搬砖人。
文章不定期同步公众号,还有各种一线大厂面试原题、我的学习系列笔记。
广州这边封闭式管理好久了,今天终于周末可以出去溜溜了

什么是zset
zset是redis中一种有序、不重复的数据类型,每个元素都有一个分值,它可用于实现排行榜单,其底层采用压缩表ziplist或跳表skiplist的数据结构实现
zset的两种数据结构
- 压缩表ziplist
当redis插入第一个元素时,同时满足以下条件,就会以ziplist创建跳表
- 节点数量<128 (可通过server.zset_max_ziplist_entries设置)
- 节点的长度<64(可通过server.zset-max-zip以上任一个,都会list-value设置)
当选择用ziplist实现zset后,以后插入的节点若不满足以上任一个条件,就会转为skiplist
- 跳表skiplist
跳表的本质是一个多层链表,它能快速地查询、插入、删除【时间复杂度均为O(logn)】,所以它的查询速度媲美平衡二叉树,而且它的数据结构比平衡二叉树简单,结构示意图如下:

特点:
- 跳表的最底层拥有所有的元素
- 跳表每一层都是一个链表,除了最底层是原始链表,层次逐渐往上可分别划分为一级索引层、二级索引层...
- 跳表插入元素时,会先随机生成出一个“层次数字”,然后元素会插入到这个层次的所有底层,直到原始链表层
- 如果一个元素存在与某个索引层,那么这个元素也会存在于低于它的所有索引下层,如元素在第99索引层,那么由上到下从99索引层直到原始链表层都会存在该元素
- 空间换时间,跳表查找变快了,但是要存储许多索引层,故空间开销变大了
/**
* 产生节点的高度。使用抛硬币
*
* @return
*/
private int getRandomLevel() {
//可知,元素的插入层次i从1开始自增,随机到哪一层的概率就像抛硬币一样,都是50%,故i越往后,其概率越小(每次都*0.5)
//第一层概率:0.5,第二层0.5*0.5=0.25,...
int lev = 1;
while (random.nextInt() % 2 == 0) {
lev++;
}
//MAX_LEVEL为跳表的最大层级
return lev > MAX_LEVEL ? MAX_LEVEL : lev;
}
跳表skiplist
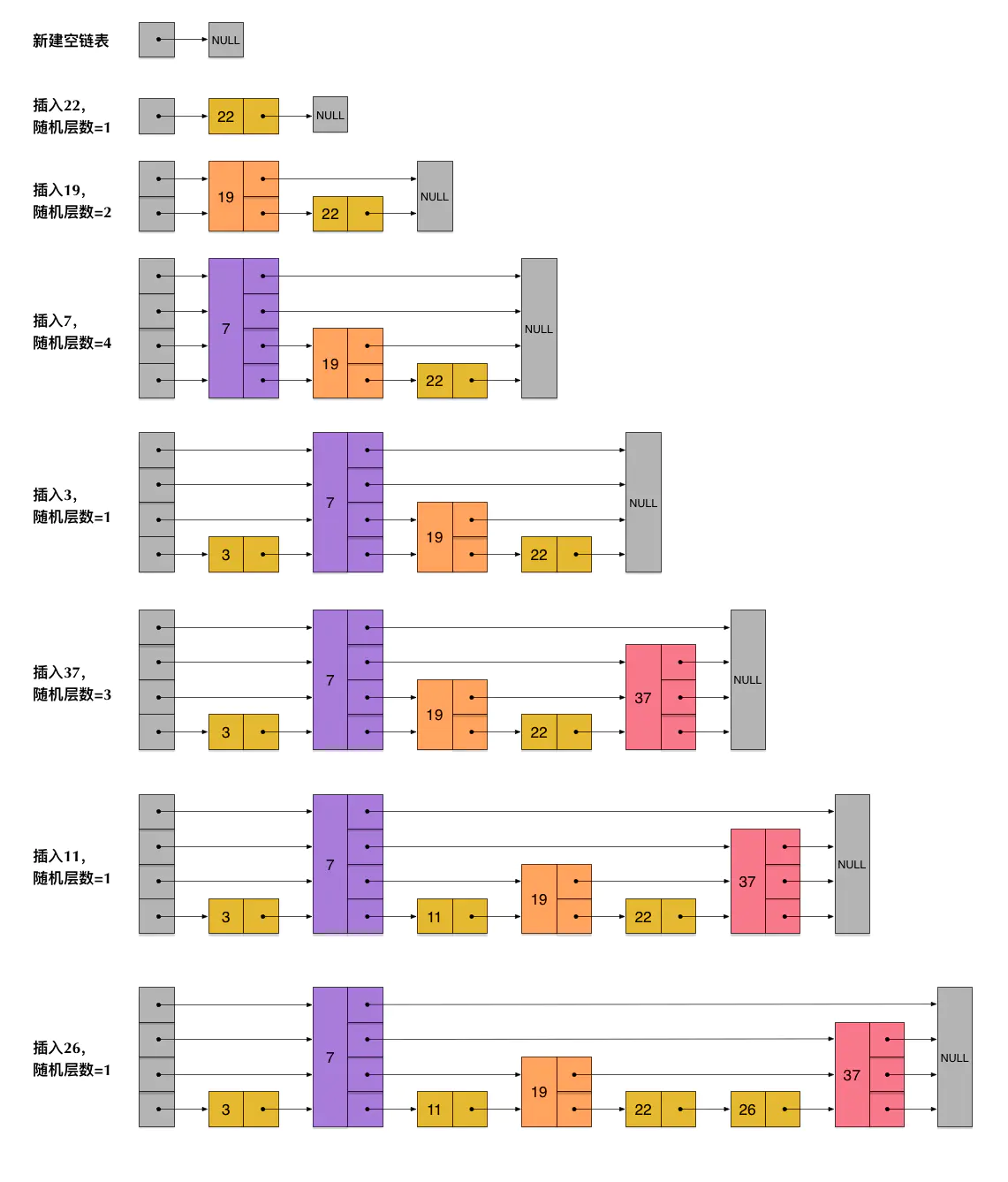
插入节点
- 插入的时间复杂度为O(logn),每次插入都会先查找到要插入的位置(查找的时间复杂度就已经是【O(logn)】了,找到后直接插入【O(1)】,所以总的为【O(logn)】),删除也是同理为O(logn)
- 每个节点的插入层次是通过getRandomLevel()随机出来的,插入层次互不影响
以下模拟节点插入:
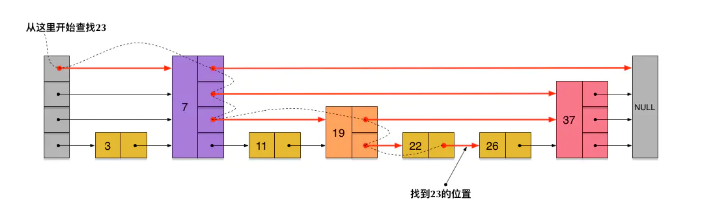
查找
查找节点时,从高索引层往低索引层查找:
一开始元素在高层从链表由前往后查找,直到要查找的目标元素在该层的某两个相邻元素之间,就会往下跳到下层的同一个位置,继续从同一位置向链表尾方向遍历查询->重复上面的过程,直到查找到目标元素
查找时每一层都跳过部分元素,进而加快了查找效率,以下模拟节点查找:
OK,如果文章哪里有错误或不足,欢迎各位留言。
创作不易,各位的「三连」是二少创作的最大动力!我们下期见!
redis的zset数据结构:跳表的更多相关文章
- Redis源码研究--跳表
-------------6月29日-------------------- 简单看了下跳表这一数据结构,理解起来很真实,效率可以和红黑树相比.我就喜欢这样的. typedef struct zski ...
- Redis中为什么使用跳表---------转自http://blog.csdn.net/u010412301/article/details/64923131
最近在研究数据库的一些底层实现,百度的面试官问到了跳表,当时没有回答上来,在csdn上看到了这篇文章,感觉写的比较好,希望大家可以多多交流. Redis里面使用skiplist是为了实现sorted ...
- 聊聊Mysql索引和redis跳表 ---redis的有序集合zset数据结构底层采用了跳表原理 时间复杂度O(logn)(阿里)
redis使用跳表不用B+数的原因是:redis是内存数据库,而B+树纯粹是为了mysql这种IO数据库准备的.B+树的每个节点的数量都是一个mysql分区页的大小(阿里面试) 还有个几个姊妹篇:介绍 ...
- Redis 学习笔记(篇三):跳表
跳表 跳表(skiplist)是一种有序的数据结构,是在有序链表的基础上发展起来的. 在 Redis 中跳表是有序集合(sort set)的底层实现之一. 说到 Redis 中的有序集合,是不是和 J ...
- Redis 的底层数据结构(跳跃表)
字典相对于数组,链表来说,是一种较高层次的数据结构,像我们的汉语字典一样,可以通过拼音或偏旁唯一确定一个汉字,在程序里我们管每一个映射关系叫做一个键值对,很多个键值对放在一起就构成了我们的字典结构. ...
- 深入理解跳表在Redis中的应用
本文首发于:深入理解跳表在Redis中的应用微信公众号:后端技术指南针持续输出干货 欢迎关注 前面写了一篇关于跳表基本原理和特性的文章,本次继续介绍跳表的概率平衡和工程实现, 跳表在Redis.Lev ...
- 红黑树、B(+)树、跳表、AVL等数据结构,应用场景及分析,以及一些英文缩写
在网上学习了一些材料. 这一篇:https://www.zhihu.com/question/30527705 AVL树:最早的平衡二叉树之一.应用相对其他数据结构比较少.windows对进程地址空间 ...
- 跳表(SkipList)设计与实现(Java)
微信搜一搜「bigsai」关注这个有趣的程序员 文章已收录在 我的Github bigsai-algorithm 欢迎star 前言 跳表是面试常问的一种数据结构,它在很多中间件和语言中得到应用,我们 ...
- 算法进阶面试题06——实现LFU缓存算法、计算带括号的公式、介绍和实现跳表结构
接着第四课的内容,主要讲LFU.表达式计算和跳表 第一题 上一题实现了LRU缓存算法,LFU也是一个著名的缓存算法 自行了解之后实现LFU中的set 和 get 要求:两个方法的时间复杂度都为O(1) ...
随机推荐
- C#中的类型转换-自定义隐式转换和显式转换
目录 前言 基础知识 示例代码 实际应用 问题 答案 报错 用户定义的转换必须是转换成封闭类型,或者从封闭类型转换 参考 其他 应用和设计 读音 参考 前言 有时我们会遇到这么一种情况:在json数据 ...
- java反射 java动态代理和cglib动态代理的区别
java反射 https://blog.csdn.net/f2764052703/article/details/89311013 java 动态代理 https://blog.csdn ...
- Redisson 加锁原理
一.分布式加锁过程 RLock lock = redissonClient.getLock(REDISSON_DISTRIBUTE_KEY); lock.lock(); wireshark抓包可以看见 ...
- Spring Boot 需要独立的容器运行吗?
可以不需要,内置了 Tomcat/ Jetty 等容器.
- 面试问题之操作系统:linux线程API
https://blog.csdn.net/youwotianya/article/details/80933449
- 什么是 rabbitmq?
采用 AMQP 高级消息队列协议的一种消息队列技术,最大的特点就是消费并不需要确保提供方存在,实现了服务之间的高度解耦
- ZAB 和 Paxos 算法的联系与区别?
相同点: 1.两者都存在一个类似于 Leader 进程的角色,由其负责协调多个 Follower 进程的运行 2.Leader 进程都会等待超过半数的 Follower 做出正确的反馈后,才会将一个提 ...
- memcached 能够更有效地使用内存吗?
Memcache 客户端仅根据哈希算法来决定将某个 key 存储在哪个节点上,而不考 虑节点的内存大小.因此,您可以在不同的节点上使用大小不等的缓存.但是一 般都是这样做的:拥有较多内存的节点上可以运 ...
- Java 中,throw 和 throws 有什么区别?
throw 用于抛出 java.lang.Throwable 类的一个实例化对象,意思是说你可以通 过关键字 throw 抛出一个 Error 或者 一个 Exception,如:throw new ...
- Flask-Script使用教程
Flask使用第三方脚本 一个干净的项目准备: 一个干净的Flask项目连接地址: https://pan.baidu.com/s/123TyVXOFvh5P7V8MbyMfDg 话不多说,上菜: 1 ...